cat channelHandle*-out.log | awk -F ',' '{print $2}'| sort | uniq -c | sort -nr
在linux系统中,我们经常会写入大量的日志文件。有时候我们需要对这些日志文件进行统计。Linux中我们可以利用以下命令简单高效的实现这一功能。
需要用到的命令简介
- cat命令
cat命令主要有三大功能
1.一次显示整个文件 cat filename
2.创建一个文件 cat > fileName
3.将几个文件合并为一个文件 cat file1 file2 > file
参数:
-n 或 –number 由 1 开始对所有输出的行数编号
-b 或 –number-nonblank 和 -n 相似,只不过对于空白行不编号
-s 或 –squeeze-blank 当遇到有连续两行以上的空白行,就代换为一行的空白行
-v 或 –show-nonprinting - | 管道
管道的作用是将左边命令的输出作为右边命令的输入 -
awk 命令
awk 是行处理器,优点是处理庞大文件时不会出现内存溢出或处理缓慢的问题,通常用来格式化文本信息。awk依次对每一行进行处理,然后输出。
命令形式 awk [-F|-f|-v] ‘BEGIN{} //{command1; command2} END{}’ file
[-F|-f|-v] 大参数,-F指定分隔符,-f调用脚本,-v定义变量 var=value
’ ’ 引用代码块
BEGIN 初始化代码块,在对每一行进行处理之前,初始化代码,主要是引用全局变量,设置FS分隔符
// 匹配代码块,可以使字符串或正则表达式
{} 命令代码块,包含一条或多条命令
;多条命令使用分号分隔
END 结尾代码块,对每一行进行处理后再执行的代码块,主要进行最终计算或输出
由于篇幅限制,可自行查找更详细的信息。这里awk命令的作用是从文件中每一行取出我们需要的字符串 -
sort 命令
sort将文件的每一行作为一个单位,相互比较,比较原则是从首字符向后,依次按ASCII码值进行比较,最后将他们按升序输出。
-b:忽略每行前面开始出的空格字符;
-c:检查文件是否已经按照顺序排序;
-d:排序时,处理英文字母、数字及空格字符外,忽略其他的字符;
-f:排序时,将小写字母视为大写字母;
-i:排序时,除了040至176之间的ASCII字符外,忽略其他的字符;
-m:将几个排序号的文件进行合并;
-M:将前面3个字母依照月份的缩写进行排序;
-n:依照数值的大小排序;
-o<输出文件>:将排序后的结果存入制定的文件;
-r:以相反的顺序来排序;
-t<分隔字符>:指定排序时所用的栏位分隔字符; - uniq 命令
uniq 命令用于报告或忽略文件中的重复行,一般与sort命令结合使用
-c或——count:在每列旁边显示该行重复出现的次数;
-d或–repeated:仅显示重复出现的行列;
-f<栏位>或–skip-fields=<栏位>:忽略比较指定的栏位;
-s<字符位置>或–skip-chars=<字符位置>:忽略比较指定的字符;
-u或——unique:仅显示出一次的行列;
-w<字符位置>或–check-chars=<字符位置>:指定要比较的字符。 - > 命令
> 是定向输出到文件,如果文件不存在,就创建文件。如果文件存在,就将其清空
另外 >>是将输出内容追加到目标文件中。其他同>
现在我们开始
1 读入文件
cat test.log.2017-09-20 - 1
执行结果
2 从每一行取出我们需要的字符串
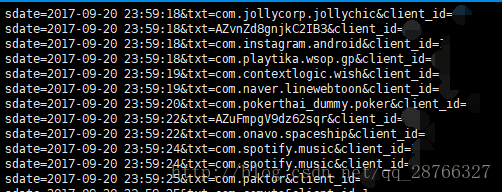
cat check_info.log.2017-09-20 | awk -F '(txt=|&client)' '{print $2}'- 1
awk 命令中 -F 指定每一行的分隔符 在这里 ‘(txt=|&client)’是分隔符,它是一个正则表达式。意义是,用’txt=’或’&client’ 作为分隔符
举例来说下面这行
sdate=2017-09-20 23:59:32&txt=com.ford.fordmobile&client_id=x- 1
会被分割成
sdate=2017-09-20 23:59:32&
com.ford.fordmobile
_id=x- 1
- 2
- 3
三部分
其中第二部分”com.ford.fordmobile”是我所需要的字段
而’{print $2}’的意思是将每行得到的第二个值打印出来,$0代表获取的所有值
执行效果如下
3 对行进行排序
先排序是因为去重与统计的 ‘unip’命令只能处理相邻行
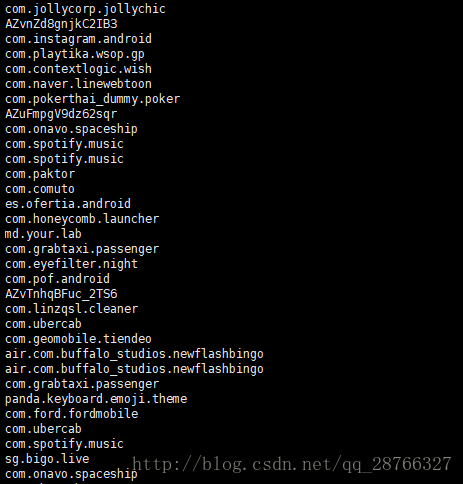
cat check_info.log.2017-09-20 | awk -F '(txt=|&client)' '{print $2}'|sort- 1
执行结果 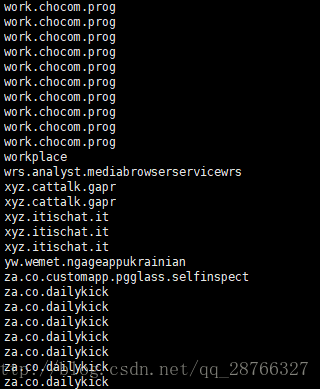
可以看到相同行已经被排在了一起
4 统计数量与去重
cat check_info.log.2017-09-20 | awk -F '(txt=|&client)' '{print $2}'| sort | uniq -c- 1
uniq -c 中的-c 代表在每列旁边显示该行重复出现的次数
执行结果
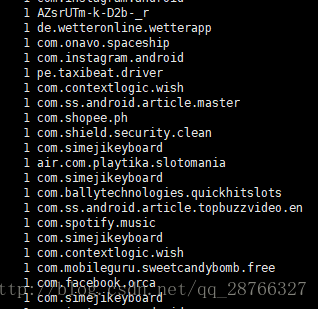
5 按重复次数排序
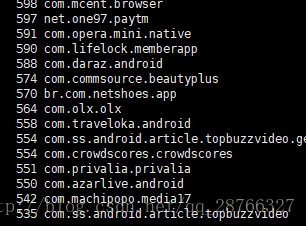
cat check_info.log.2017-09-20 | awk -F '(txt=|&client)' '{print $2}'| sort | uniq -c | sort -nr- 1
sort 的 -n:依照数值的大小排序;-r 按照相反顺序排列
执行结果
6 将结果输出到文件中
cat check_info.log.2017-09-20 | awk -F '(txt=|&client)' '{print $2}'| sort | uniq -c | sort -nr > testfile- 1
可以看到我们当前目录已有testfile 目录
用vim 打开可以看到