对于程序而言,外层循环越大,性能越低,对于数据库而言,永远是小的数据集放在最外层
程序设计原则:小的循环放到最外层,大的循环放在最小层
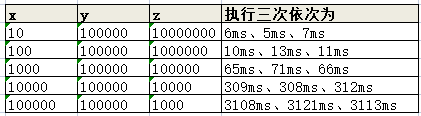
我们通过设置x、y、z的值来测试,而 x * y * z它的值是不变的,即我们测试的总循环次数不变。我们通过调整x、y、z的值分别来测试一下
注意,这里的测试需要通过三层for循环才能测出效果
public class ForTest { // Integer.MAX_VALUE = 2147483647 // static int x = 1000000000; static int x = 10000; static int y = 1000; static int z = 1000; public static void main(String[] args) { test1(); } public static void test1() { long nanoTime1 = System.currentTimeMillis(); for (int i = 0; i < x; i++) { for (int j = 0; j < y; j++) { for (int m = 0; m < z; m++) { int a = 10; int b = 20; int c = a + b; } } } long nanoTime2 = System.currentTimeMillis(); System.out.println("总耗时:" + (nanoTime2 - nanoTime1)); } }
测试结果:
LEFT JOIN
select * A left join B on A.id = B.aid 是给A表加索引还是给B表加索引?
对于left join而言,此SQL相当于
for (int i=0; i<A.size(); i++) { for (int i=0; i<B.size(); i++) { if(A.id==B.aid) { } } }
当A表为小表时,性能要比A表为大表的性能要高
索引建立原则:因为A表为基准表(固定不变的),B表为驱动表,因此需要在B表建立索引,即程序为:
for (int i=0; i<A.size(); i++) { B b = findB(A.id); // 通过索引查找 }
从另一个角度而言,假设A表数据集为100条,B表数据集为100000条,给B表加索引要比A表加索引要好!