背景
HBase统计 RowCount 的方法有好几种,并且执行效率差别巨大,以下3种方法效率依次提高。
一、hbase-shell的count命令
这是最简单直接的操作,但是执行效率非常低,适用于百万级以下的小表RowCount统计。

此操作可能需要很长时间,来运行计数MapReduce作业。默认情况下每1000行显示当前计数,计数间隔可自行指定。
默认情况下在计数扫描上启用缓存,默认缓存大小为10行。
行数为 3000W 的表测试结果,在默认INTERVAL为1000行时花了80分钟左右
二、hbase.RowCounter包执行MR任务
这种方式效率非常高!利用了hbase jar中自带的统计行数的工具类!
通过 $HBASE_HOME/bin/hbase 命令执行:
hbase org.apache.hadoop.hbase.mapreduce.RowCounter 'terminal_detail_data'

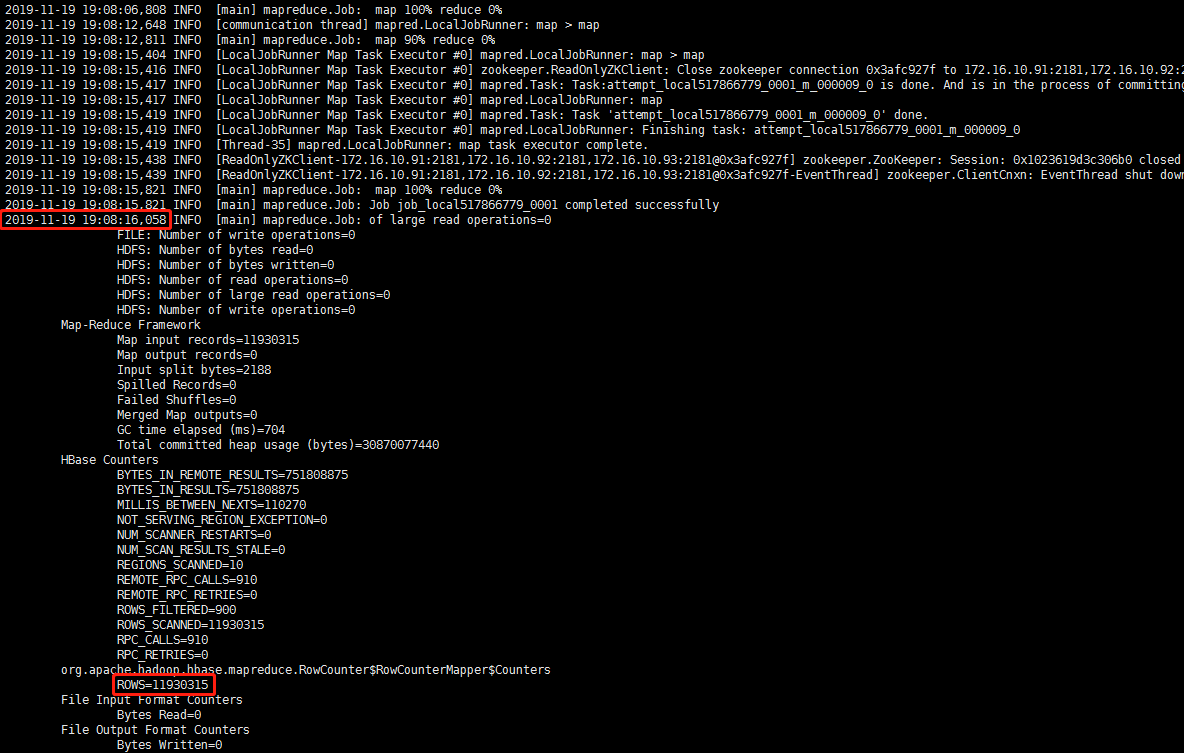
1200W的数据,耗时2分钟左右,速度较有了质的飞跃!
三、HBase协处理器Coprocessor(JAVA实现)
这是我目前发现效率最高的RowCount统计方式,利用了HBase高级特性:协处理器!
我们往往使用过滤器来减少服务器端通过网络返回到客户端的数据量。但HBase中还有一些特性让用户甚至可以把一部分计算也移动到数据的存放端,那就是协处理器 (coprocessor)。
协处理器简介:
(节选自《HBase权威指南》)
使用客户端API,配合筛选机制,例如,使用过滤器或限制列族的范围,都可以控制被返回到客户端的数据量。如果可以更进一步优化会更好,例如,数据的处理流程直接放到服务器端执行,然后仅返回一个小的处理结果集。这类似于一个小型的MapReduce框架,该框架将工作分发到整个集群。
协处理器 允许用户在region服务器上运行自己的代码,更准确地说是允许用户执行region级的操作,并且可以使用与RDBMS中触发器(trigger)类似的功能。在客户端,用户不用关心操作具体在哪里执行,HBase的分布式框架会帮助用户把这些工作变得透明。
实现代码:
public void rowCountByCoprocessor(String tablename){ try { //提前创建connection和conf Admin admin = connection.getAdmin(); TableName name=TableName.valueOf(tablename); //先disable表,添加协处理器后再enable表 admin.disableTable(name); HTableDescriptor descriptor = admin.getTableDescriptor(name); String coprocessorClass = "org.apache.hadoop.hbase.coprocessor.AggregateImplementation"; if (! descriptor.hasCoprocessor(coprocessorClass)) { descriptor.addCoprocessor(coprocessorClass); } admin.modifyTable(name, descriptor); admin.enableTable(name); //计时 StopWatch stopWatch = new StopWatch(); stopWatch.start(); Scan scan = new Scan(); AggregationClient aggregationClient = new AggregationClient(conf); System.out.println("RowCount: " + aggregationClient.rowCount(name, new LongColumnInterpreter(), scan)); stopWatch.stop(); System.out.println("统计耗时:" +stopWatch.getTotalTimeMillis()); } catch (Throwable e) { e.printStackTrace(); } }
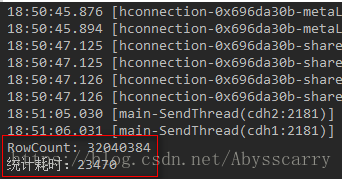
发现只花了 23秒 就统计完成!
为什么利用协处理器后速度会如此之快?
Table注册了Coprocessor之后,在执行AggregationClient的时候,会将RowCount分散到Table的每一个Region上,Region内RowCount的计算,是通过RPC执行调用接口,由Region对应的RegionServer执行InternalScanner进行的。
参考链接:https://blog.csdn.net/abysscarry/article/details/82861425