首先看下类的继承关系,不多介绍:
public interface Executor {void execute(Runnable);}
public interface ExecutorService extends Executor {...}
public abstract class AbstractExecutorService implements ExecutorService {...}
public class ThreadPoolExecutor extends AbstractExecutorService {...}
线程池构造器七大参数:
核心线程数,最大线程数,生存时间,时间单位,任务队列,线程工厂,拒绝策略
public ThreadPoolExecutor(int corePoolSize, //核心线程数
int maximumPoolSize, //最大线程数
long keepAliveTime, //生存时间
TimeUnit unit, //时间单位
BlockingQueue<Runnable> workQueue, //任务队列
ThreadFactory threadFactory, //线程工厂
RejectedExecutionHandler handler) //拒绝策略
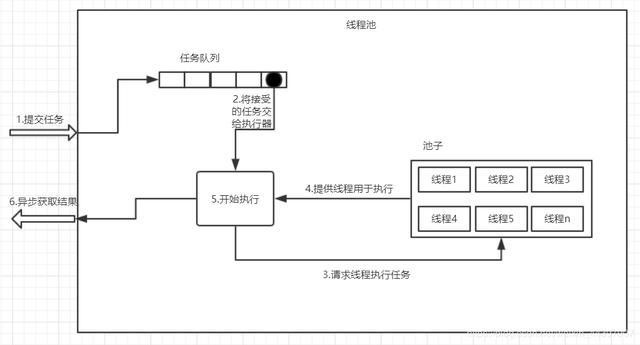
先对线程池有个大概的概念:线程池,有若干个运行中的线程(工作者,Worker),负责从任务队列(workQueue)中取任务(Task)出来,并执行它。
private final BlockingQueue<Runnable> workQueue;
private final HashSet<Worker> workers = new HashSet<Worker>();
这里再大概介绍一下Worker类:
Worker类内部有两个关键引用:线程Thread t、待执行任务Runnable firstTask。
并且其自身就是Runnable,其run()方法调用自身的runWorker()方法,稍后再来介绍runWorker()干了啥。

回到线程池的使用:一般都是调用submit()或者execute()。submit()只是把传入的Runnable包装成FutureTask来保存执行结果,本质也是调用execute()方法。

因此我们主要分析execute()方法:
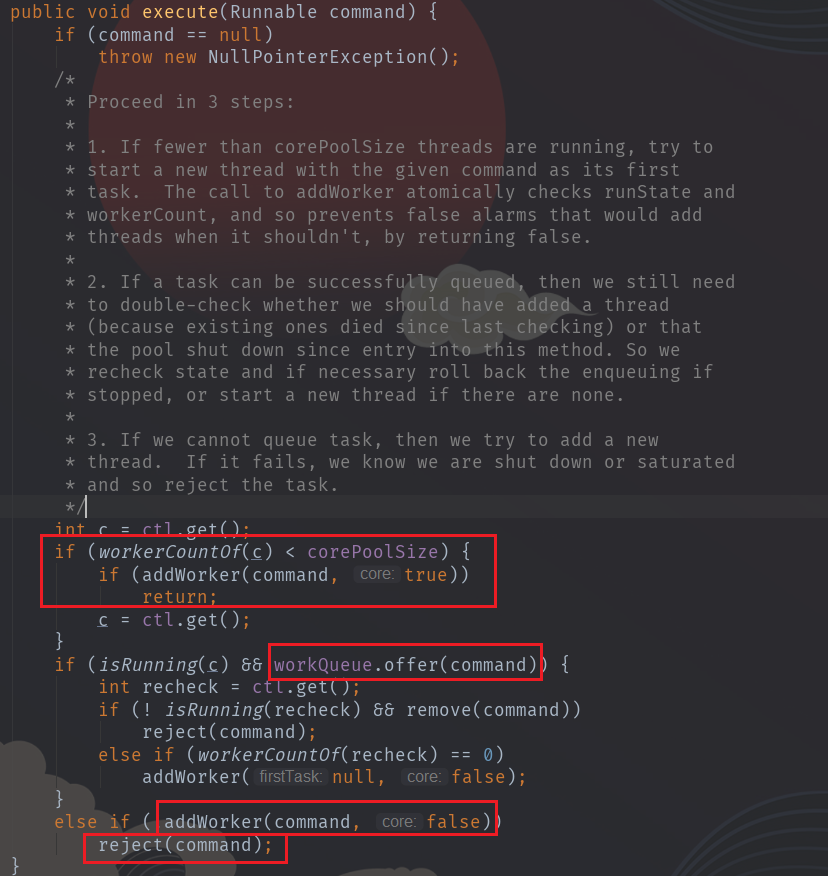
结合代码和注释,可以得出其执行流程:public void execute(Runnable command)
- 不够核心线程数的时候,起新线程(addWorker())
- 核心线程满的时候把command放进workQueue队列
- 核心线程和队列都满,不够最大线程数的时候,起新线程
- 否则执行拒绝策略

其中最关键的当然是创建新线程执行任务的过程,addWorker()方法:
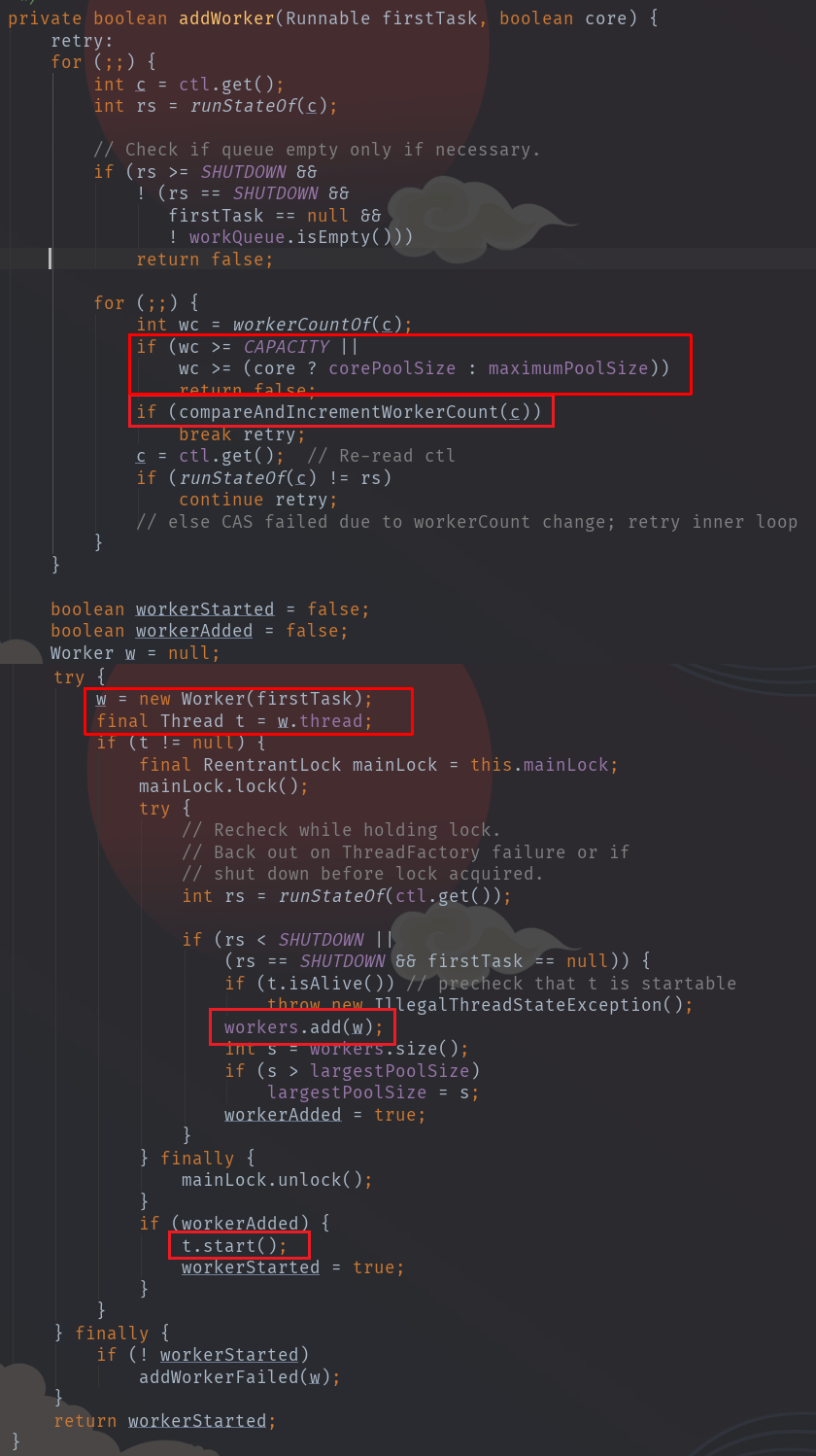
大概描述一下addWorker()的执行步骤:
- 双重CAS把工作线程数加一
new一个Worker w,并放入workers(HashSet)。- 放入成功则执行
w.t.start()(即会调用w.run())
其中,最初传入的command作为w的firstTask,w.t是用线程工厂创建一个新线程,把w自己作为Runnable传入。
而w.run()方法直接执行runWorker()方法:
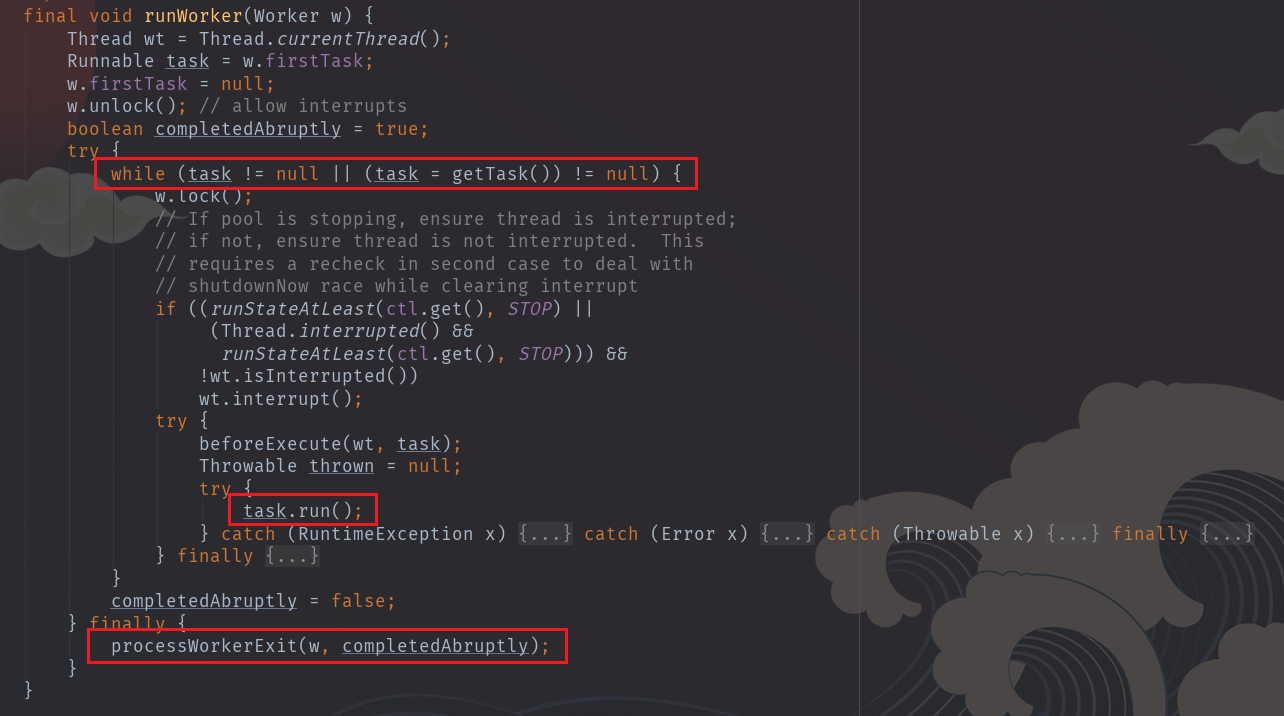
描述一下大概执行过程:
- 把 task 取出来:task = w.firstTask; w.firstTask = null;
- 首先执行 task ,然后循环从阻塞队列 workQueue 中获取一个 task 来执行
- 获取不到任务时,结束运行。结束之前执行一些后续处理。
此外,有几个小问题值得一提:
- 非核心线程与核心线程的区别:
并没有这种区别。从源码可以看到,addWorker()方法的参数boolean core并不会用于创建不同类型的Worker。只在新建Worker之前判断“核心线程是否已满”:core=true时,判断工作线程数是否大于corePoolSize,是则返回false而不新建Worker。core=false时,判断工作线程数是否大于maximumPoolSize,是则返回false而不新建Worker。
- 那怎么使得核心线程不被销毁而非核心线程被销毁呢?
可以看到,如果当前的工作线程数大于核心线程数,则从任务队列中取任务的方法则从阻塞的take()方法换为超时等待keepAliveTime时长的poll()。当非核心线程闲置(任务队列没有任务)的时候,等待一会从getTask()方法返回null,于是线程结束。
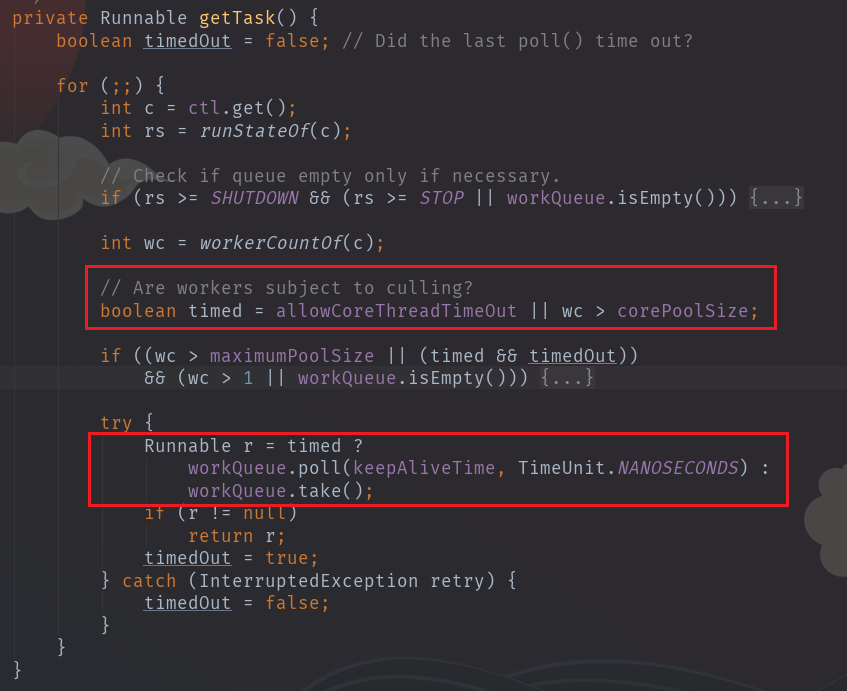
其中allowCoreThreadTimeOut属性指示keepAliveTime是否也会作用于核心线程。
并且,线程结束之前有“后续处理”:
可以看到,如果当前的工作线程数小于核心线程数,则新建一个没有task的线程(等待任务队列中的任务到来)。

最后提一下线程工厂和拒绝策略:
-
Executors提供的默认线程工厂DefaultThreadFactory其实内部也是new Thread的方式来新建线程,分配pool-i-thread-j这样的线程名称。当然最好自己实现线程工厂来分配有意义的线程名,方便查错。 -
ThreadPoolExecutor提供四种拒绝策略。当然,最好是根据需求自己实现拒绝策略。AbortPolicy:抛出异常DiscardPolicy:扔掉任务,不抛异常DiscardOldestPolicy:扔掉排队时间最久的任务CallerRunsPolicy:调用者负责处理任务