前言
在web页面中经常会遇到table表格,特别是后台操作页面比较常见。本篇详细讲解table表格如何定位。
一、认识table
1.首先看下table长什么样,如下图,这种网状表格的都是table
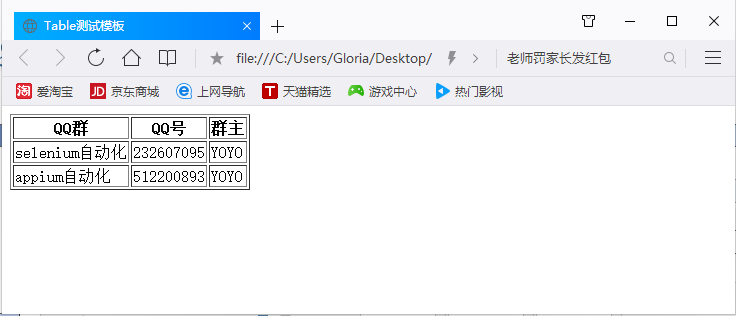
2.源码如下:(用txt文本保存,后缀改成html)
<!DOCTYPE html>
<meta charset="UTF-8"> <!-- for HTML5 -->
<meta http-equiv="Content-Type" content="text/html; charset=utf-8" />
<html>
<head>
<title>Table测试模板</title>
</head>
<body>
<table border="1" id="myTable">
<tr>
<th>QQ群</th>
<th>QQ号</th>
<th>群主</th>
</tr>
<tr>
<td>selenium自动化</td>
<td>232607095</td>
<td>YOYO</td>
</tr>
<tr>
<td>appium自动化</td>
<td>512200893</td>
<td>YOYO</td>
</tr>
</table>
</body>
</html>
二、table特征
1.table页面查看源码一般有这几个明显的标签:table、tr、th、td
2.<table>标示一个表格
3.<tr>标示这个表格中间的一个行
4.</th> 定义表头单元格
5.</td> 定义单元格标签,一组<td>标签将将建立一个单元格,<td>标签必须放在<tr>标签内
三、xpath定位table
1.举个例子:我想定位表格里面的“selenium自动化”元素,这里可以用xpath定位:
.//*[@id='myTable']/tbody/tr[2]/td[1]
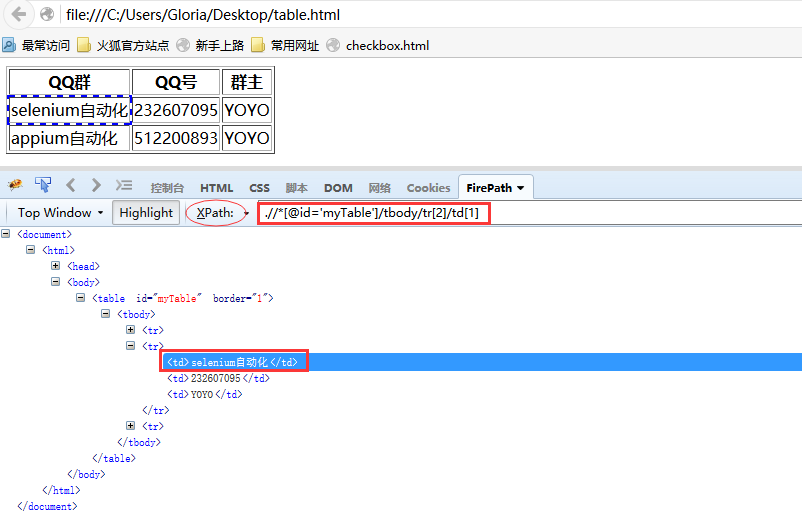
2.这里定位的格式是固定的,只需改tr和td后面的数字就可以了.如第二行第一列tr[2]td[1].
对xpath语法不熟悉的可以看这篇Selenium2+python自动化7-xpath定位
四、打印表格内容
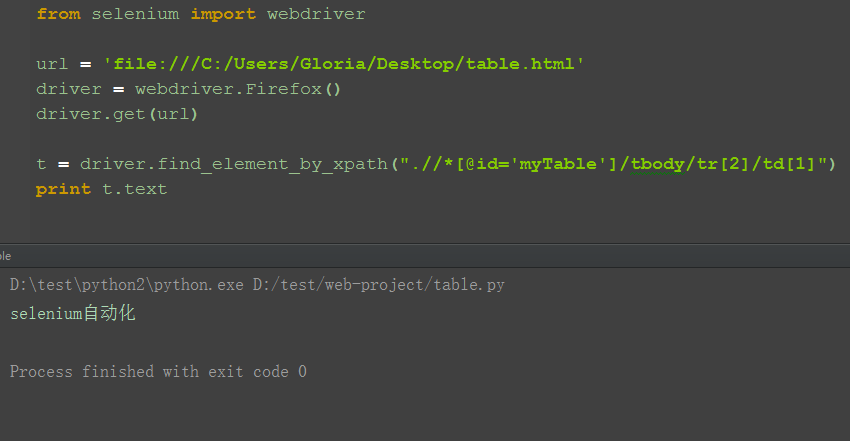
1.定位到表格内文本值,打印出来,脚本如下
五、参考代码:
# coding:utf-8
from selenium import webdriver
import time
url = 'file:///C:/Users/Gloria/Desktop/table.html'
driver = webdriver.Firefox()
driver.get(url)
time.sleep(3)
t = driver.find_element_by_xpath(".//*[@id='myTable']/tbody/tr[2]/td[1]")
print t.text