一、苏神系列
- 【未登录词】
没有被收录在分词词表中但必须被切分出来的词, 包括各种专有名词(人名、地名、企业名、机构名等)、 缩写词、网络新词以及新增词汇等。(参考:张剑锋.规则和统计相结合的中文分词方法研究.[硕士学位论文].太原:山西大学,2008.)
- 【频数(Frequency)及概率(Probavility)】
一个文本片段在文本中出现的频率。文本片段出现的概率:eg.在24万字的数据中,“电影”一共出现了2774次,出现的 概率P(“电影”)约为2774/(24w-1)=0.01155;“院”字出现了4797次,出现的概率P(“院”)为4797/24w=0.01998。
- 【凝固度】
也叫做点间互信息(Pointwise Mutual Information),表示一个文本片段的凝合程度,其中P(x)表示文本片段x在整个语料中出现的概率,因此凝固程度的计算公式为:

如果x和y的出现完全随机,那么PMI=1;如果x和y同时出现的概率,大于完全随机,那么PMI>1。PMI越大,说明这两个词经常出现在一起,意味着两个词的凝固程度越大,其组成一个新词的可能性也就越大。例如“电影院”三字可以由“电影”和“院”凝合或者“电”和“影院”凝合,Matrix67取其所有PMI最小值(去掉log)作为内部凝固度。
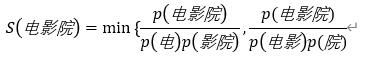
- 【信息熵(Information Entropy)】
反映知道一个事件的结果后平均会给你带来多大的信息量。若一个结果发生的概率为P,当你知道它确实发生了,你得到的信息量就被定义为-log(p),因此P越小你得到的信息量就越大。
- 【自由度(Freedom)】
也叫做左右信息熵(Information Entropy),指文本片段的自由运用程度:左邻字信息熵和右邻字信息熵中的较小值。
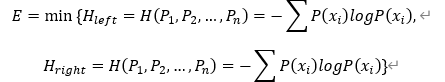
例如“被子”,可以在前面加上一个字成为“进被子”、“盖被子”、“好被子”、“这被子”、“掀被子”等等,其左邻词的熵很大;但“辈子”搭配较为固定,除了“一辈子”、 “这辈子”、“上辈子”、“下辈子”,基本就不能加上其他字了,其左邻词的熵较小。文本的运用程度是判断文本片段是否成词的重要标志。如果一个文本片段能够成词,一定具有非常丰富的左邻字集合和右邻字集合,其成为一个独立的词的可能性也就越大。
- 【网络经验公式】
(30M文本,字母n表示n-gram即相关新词包含的字数):词频>200,凝固度>10 ( n − 1 ) 10^{(n-1)}10 (n−1) ,自由度>1.5;词频>30, 凝固度>2 0 ( n − 1 ) 20^{(n-1)}20 (n−1)也能发现很多低频的词汇。
- 苏剑林. (Oct. 26, 2015). 《新词发现的信息熵方法与实现 》[Blog post]. Retrieved from https://kexue.fm/archives/3491
算法思想来源:Matrix67.com. (Oct. 26, 2015). 《互联网时代的社会语言学:基于SNS的文本数据挖掘》[Blog Post]. Retrieved from http://www.matrix67.com/blog/archives/5044
算法流程:把语料文本视作一整个字符串,并对该字符串的所有后缀按字典序排序,在内存中存储这些后缀的前d+1个字或者只存储它们在语料中的起始位置提高效率,对文本进行字频和字数统计后,根据候选词语的最大字数min_sep生成所有可能的候选词,随后统计候选词频进行过滤,再计算凝固度,根据最小凝固度min_support进行过滤。接下来, 从头到尾扫描一遍算出各个候选词的频数和右邻字信息熵,将整个语料逆序后重新排列所有的后缀,再扫描一遍后统计出每个候选词的左邻字信息熵,从而进行自由度 计算并根据min_s过滤产生较大信息熵的候选词,最后输出排序并且长度大于n字的新词。
总结:采用频数、凝固度、自由度进行筛选,效率O(nlogn)。
参考Code1:https://github.com/fzibin/New_word_discovery,包含反作弊新词发现和短语提取。
参考Code2:https://github.com/actank/new_words_find,新词发现/未登录词识别。
- 苏剑林. (Aug. 18, 2016). 《【中文分词系列】 2. 基于切分的新词发现 》[Blog post]. Retrieved from https://kexue.fm/archives/3913
算法流程:由于文本片段的凝固度大于一定程度时,片段的可能成词,然后考虑自由度,那么如果文本片段的凝固度低于一定值,则该文本片段不成词,则可以进行分词。设a、b是语料中哄相邻两字,统计(a, b)成对出现的次数#(a, b),继而估计它的频率P(a, b),分别统计a,b出现的次数#a、#b,然后估计它们的频率P(a)、P(b),判断 P(a, b) / [P(a)*P(b)] < α(α是给定的大于1的阈值),则在语料中将这两个字断开,实施对原始语料初步的分词,完成分词后统计词频,根据词频进行筛选。(只用了频数和凝固度,去掉了计算量最大的自由度,计算凝固度时只需要计算二字片段的凝固度,但理论上能够得到任意长度的词语。但凝固度不高的词语在α太大时会导致切错。)
优缺点:速度快,但词很粗糙,只用了频数和凝固度,去掉了计算量最大的边界熵,计算凝固度时只需要计算二字片段的凝固度,但理论上能够得到任意长度的词语,但凝固度不高的词语在α太大时会导致切错。
- 苏剑林. (Sep. 12, 2016). 《【中文分词系列】 5. 基于语言模型的无监督分词 》[Blog post]. Retrieved from https://kexue.fm/archives/3956
总结:结合语言模型和贝叶斯概率,强大但受到viterbi等限制。
- 苏剑林. (Mar. 06, 2017). 《【中文分词系列】 7. 深度学习分词?只需一个词典! 》[Blog post]. Retrieved from https://kexue.fm/archives/4245
总结:带词频的词表根据规则生成句子进行预标注作为训练数据,使用LSTM模型结合viterbi算法,通过动态规化来输出最后的结果。最终的模型在backoff2005的评测集上达到85%左右的准确率(backoff2005提供的score脚本算出的准确率)。
- 苏剑林. (Mar. 11, 2017). 《【中文分词系列】 8. 更好的新词发现算法 》[Blog post]. Retrieved from https://kexue.fm/archives/4256
代码:苏剑林. (Sep. 09, 2019). 《重新写了之前的新词发现算法:更快更好的新词发现 》[Blog post]. Retrieved from https://kexue.fm/archives/6920
Github地址:https://github.com/bojone/word-discovery
优化代码:https://github.com/Chuanyunux/Chinese-NewWordRecognition
Kenlm预训练及使用方法:https://github.com/mattzheng/py-kenlm-model
算法流程:
Step1.统计,选取某个固定的n,统计2grams、3grams、…、ngrams,计算他们的内部凝固度,只保留高于某个阈值的片段,构成一个集合G;这一步,可以为2grams、3grams、…、ngrams设置不同的阈值,不一定要相同,因为字数越大,一般来说统计就越不充分,越有可能相同,所以字数越大,阈值要越高。
Step2.切分,用上述grams对语料进行切分(粗糙的分词),并统计频率即统计分词结果,跟第一步的凝固度集合筛选没有交集,筛选出高频部分。切分的规则是,只要一个片段出现在前一步得到的集合G中,这个片段就不切分,比如“各项目”,只要“各项”和“项目”都在G中,这个时候就算“各项目”不在G中,那么“各项目”还是不切分,保留下来。
Step3.回溯,例如因为“各项”和“项目”都出现在高凝固度的片段中,所以第二步中不会把“各项目”切开,但并不希望“各项目”成词,因为“各”跟“项目”的凝固度不高,所以通过回溯,把“各项目”移除。
- 苏剑林. (Apr. 10, 2019). 《分享一次专业领域词汇的无监督挖掘 》[Blog post]. Retrieved from https://kexue.fm/archives/6540
总结:电力专业领域词汇挖掘竞赛数据的无监督挖掘,主要与基准做对比得到差集再聚类后处理。
二、主要方法
- 规则/概率/信息熵(如苏神基于分词的新词发现等)
1)TextRank关键词提取、关键短语提取、摘要提取:https://www.letiantian.me/2014-12-01-text-rank/,https://github.com/letiantian/TextRank4ZH。
2)TopWORDS(On the unsupervised analysis of domain-specific Chinese texts,Apriori+EM+动态规划得到词典排序结果):https://baijiahao.baidu.com/s?id=1622711692639477068&wfr=spider&for=pc,https://github.com/qf6101/topwords。
- 序列标注/实体识别+规则(如苏神基于分词的新词发现)。
- 候选词+分类器:基于SVM和特征相关性的微博新词发现研究_韩修龙.pdf、基于古汉语语料的新词发现方法。
三、工具
- SmoothNLP:https://github.com/smoothnlp/SmoothNLP。
- HarvestText:包括 底层 分词、文本清洗、实体链接、实体识别、新词发现、拼音纠错、别名识别, 上层任务:情感分析、文本摘要、事实抽取、问答。github 链接:https://github.com/blmoistawinde/HarvestText
- jiagu自然语言处理工具:包含多种NLP下游任务,包括中文分词、词性标注、命名实体识别、知识图谱关系抽取、关键词提取、文本摘要、新词发现、情感分析、文本聚类:https://github.com/ownthink/Jiagu,可直接调包。
- Transformer:
开天-新词,中文新词发现与校对工具:https://zhuanlan.zhihu.com/p/94486848,https://github.com/DenseAI/kaitian-xinci ;
keras-transformer:https://github.com/kpot/keras-transformer ;https://github.com/GlassyWing/transformer-word-segmenter。
- 基于C++的新词发现,速度更快:https://github.com/Lapis-Hong/fast-xinci。