一、Hadoop命令行操作
(1)查看帮助
$hdfs dfs -help

(2)查看当前目录信息
$hdfs dfs -ls /

(3)上传文件
$hdfs dfs -put /本地路径 /hdfs路径

(4)剪切文件
$hdfs dfs -moveFromLocal a.txt /aa.txt

(5)下载文件到本地
$hdfs dfs -get /hdfs路径 /本地路径

(6)合并下载
$hdfs dfs -getmerge /hdfs路径文件夹 /合并后的文件

(7)创建文件夹
$hdfs dfs -mkdir /hello

(8)创建多级文件夹
$hdfs dfs -mkdir -p /hello/world


(9)移动hdfs文件
$hdfs dfs -mv /hdfs路径 /hdfs路径

(10)复制hdfs文件
$hdfs dfs -cp /hdfs路径 /hdfs路径


(11)删除hdfs文件
$hdfs dfs -rm /aa.txt

(12)删除hdfs文件夹
$hdfs dfs -rm -r /hello

(13)查看hdfs中的文件
$hdfs dfs -cat /文件
$hdfs dfs -tail -f /文件
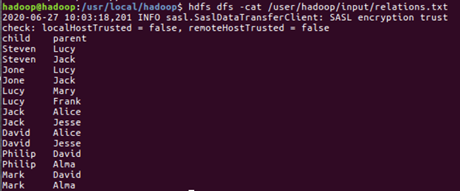
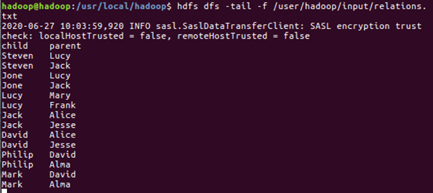
(14)查看文件夹中有多少个文件
$hdfs dfs -count /文件夹

(15)查看hdfs的总空间
$hdfs dfs -df /
$hdfs dfs -df -h /


(16)修改副本数
$hdfs dfs -setrep 1 /a.txt


二、熟悉HDFS操作常用的Java API
1.Elipse安装和配置
(1)下载elipse官方的installer:https://www.eclipse.org/downloads/download.php?file=/oomph/epp/2019-03/R/eclipse-inst-linux64.tar.gz,解压后双击运行报错:A Java Runtime Environment (JRE) or Java Development Kit (JDK) must be available in order to run Eclipse. No Java virtual machine was found after searching the following locations:……。则:Eclipse解压包中创建一个叫做jre的文件夹并且进入其中,在终端中打开,在jre中创建链接:ln -s /usr/lib/jvm/java/bin bin,双击运行成功。
(2)启动Hadoop
$ cd /usr/local/hadoop/
$ ./sbin/start-dfs.sh
$ jps
2.使用Maven创建一个新的项目,命名位“HelloHdfs”
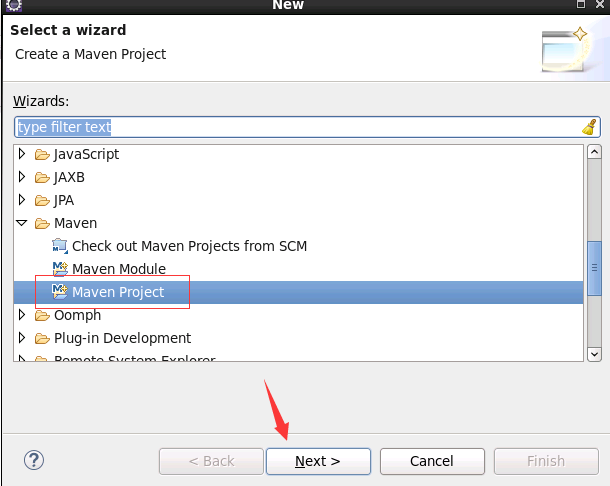
(1)选择创建项目的方式

(2)使用maven创建
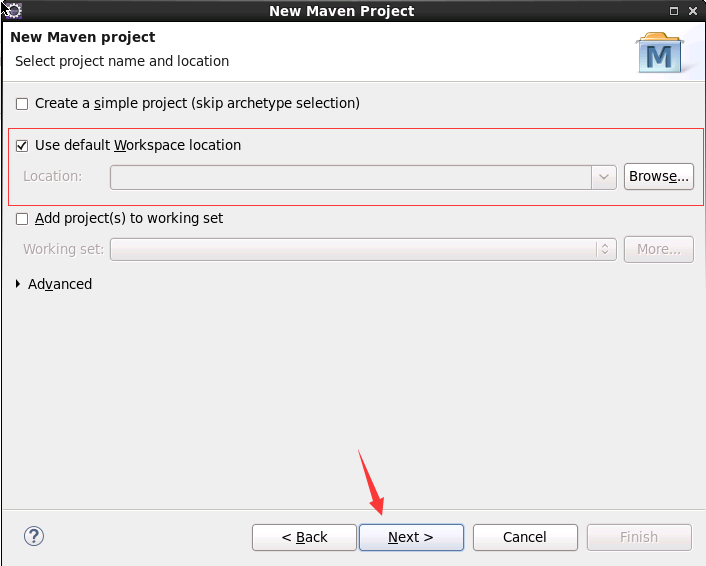
 (3)选择项目存放路径,这里使用默认路径,然后点击下一步“next”
(3)选择项目存放路径,这里使用默认路径,然后点击下一步“next”
(4)选择项目原型,这里选择“maven-archetype-quickstart”,然后点击下一步“next“
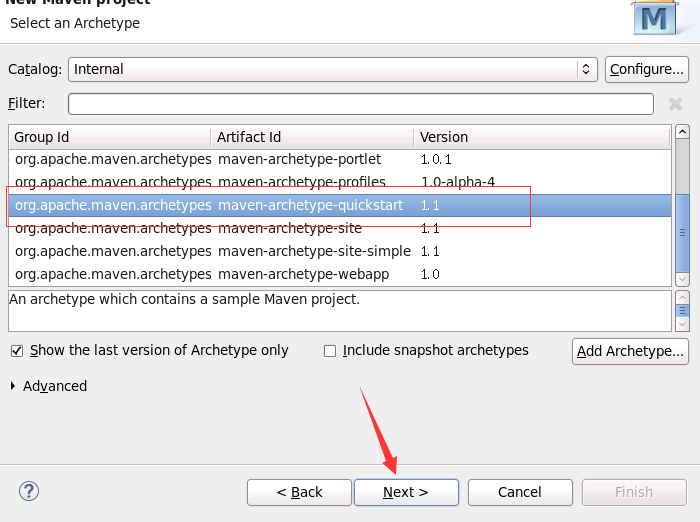
(5)填写项目参数
Group Id:组织的名称,即包名的前一段,比如说包名是“com.techvalley.hdfs.uploadmain”,那么“com.techvalley.hdfs”就是组织的名称。
Artifact Id:项目的名称HelloHdfs。
Version: 版本,随便填写或者不填写,使用默认的即可。
Package:包名,填写后会自动生成一个包,可以删除,可以随意填写。
填写完成厚后点击“Finish”即可完成创建
(6)pom.xml添加项目需要使用到的jar包,采用添加依赖的方式。在<dependencies></dependencies>添加如下内容:
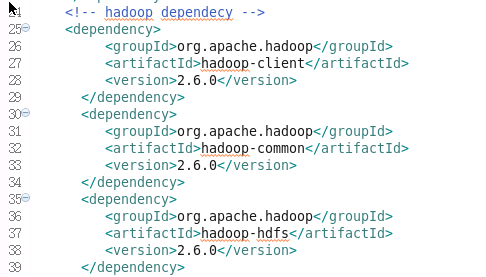
保存(等待build完毕)。
3.JAVA API操作
(1)向HDFS中上传任意文本文件
如果指定的文件在HDFS中已经存在,由用户指定是追加到原有文件末尾还是覆盖原有的文件。
(2)从HDFS中下载指定文件
如果本地文件与要下载的文件名称相同,则自动对下载的文件重命名。
(3)将HDFS中指定文件的内容输出到终端
(4)显示HDFS中指定的文件读写权限、大小、创建时间、路径等信息。
(5)输出目录信息
给定HDFS中某一个目录,输出该目录下的所有文件的读写权限、大小、创建时间、路径等信息。如果该文件是目录,则递归输出该目录下所有文件相关信息.
(6)提供一个HDFS内的文件的路径,对该文件进行创建和删除操作。如果文件所在目录不存在,则自动创建目录。
(7)提供一个HDFS的目录的路径,对该目录进行创建和删除操作。创建目录时,如果目录文件所在目录不存在则自动创建相应目录;删除目录时,由用户指定当该目录不为空时是否还删除该目录。
(8)向HDFS中指定的文件追加内容,由用户定内容追加到原有文件的开头或结尾。
(9)在HDFS中将文件从源路径移动到目的路径