一、安装 web scraper 插件
在网页上搜索web scraper 下载,下载后是一个 crx 文件(web scraper插件只支持Chrome浏览器)
二、在Chrome浏览器中部署 web scraper
打开Chrome浏览器,找到扩展程序
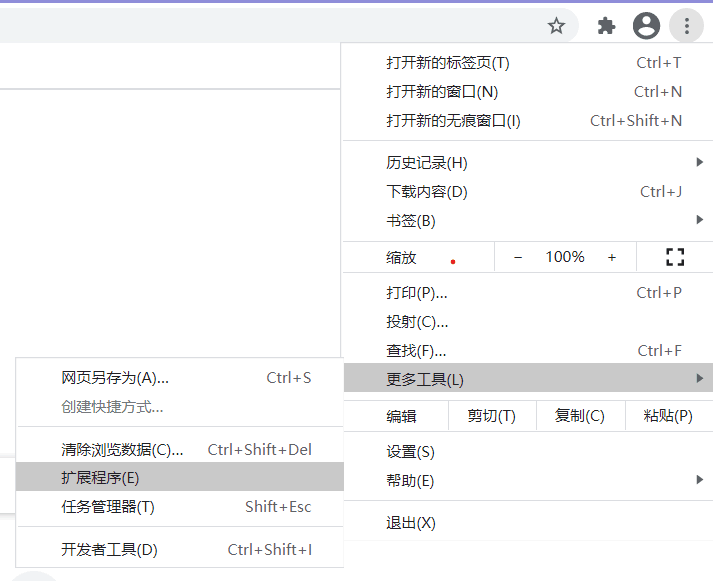
进入扩展程序的页面后,打开开发者模式

点击加载已解压的扩展程序,选择刚刚下载的crx文件

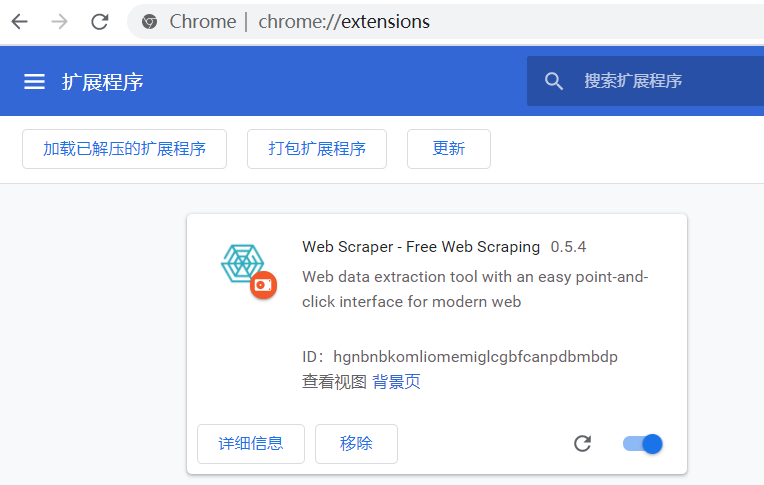
出现以下这个页面后,部署 web scraper 完成
三、爬取一页景点信息
1.先打开美团的官网,登录自己的账号
搜索山东的景点
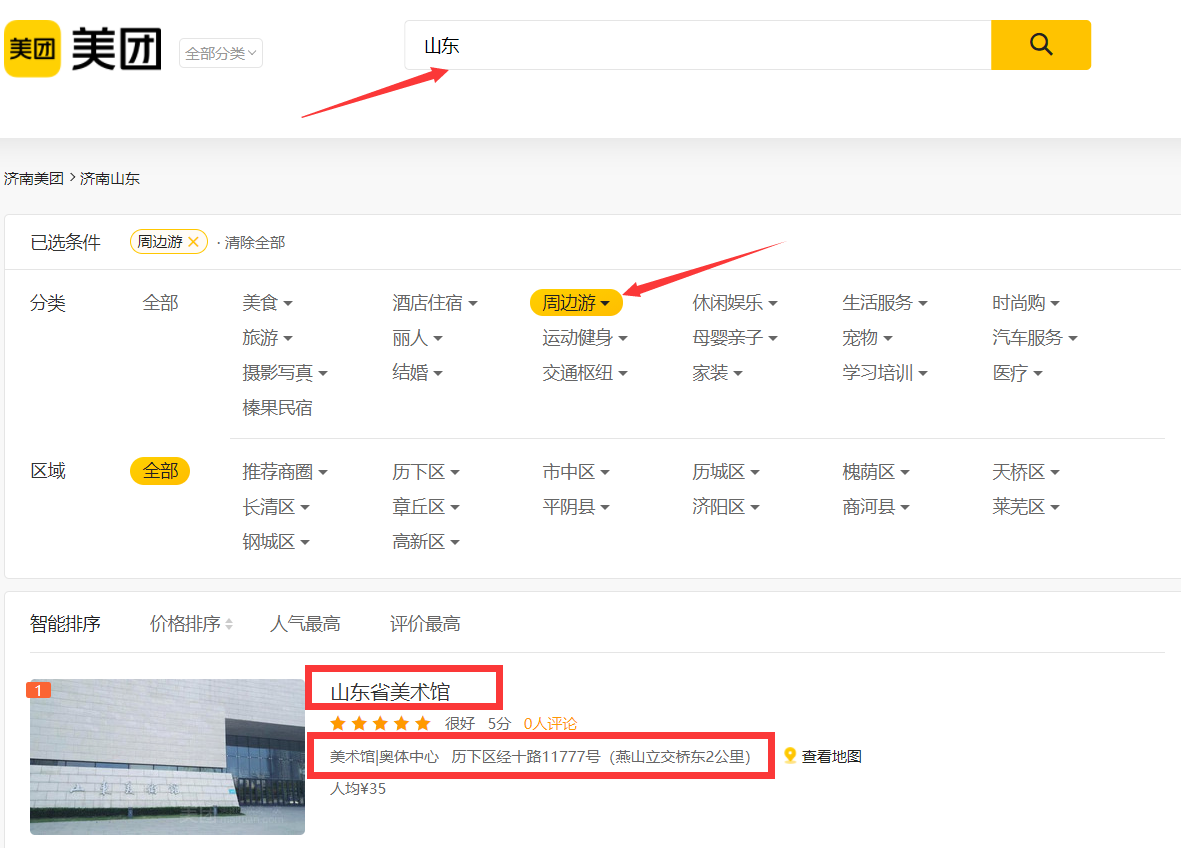
要爬取的内容为两部分,景点的名称和位置
2. 右键选择检查,进入开发者模式,选择web scraper
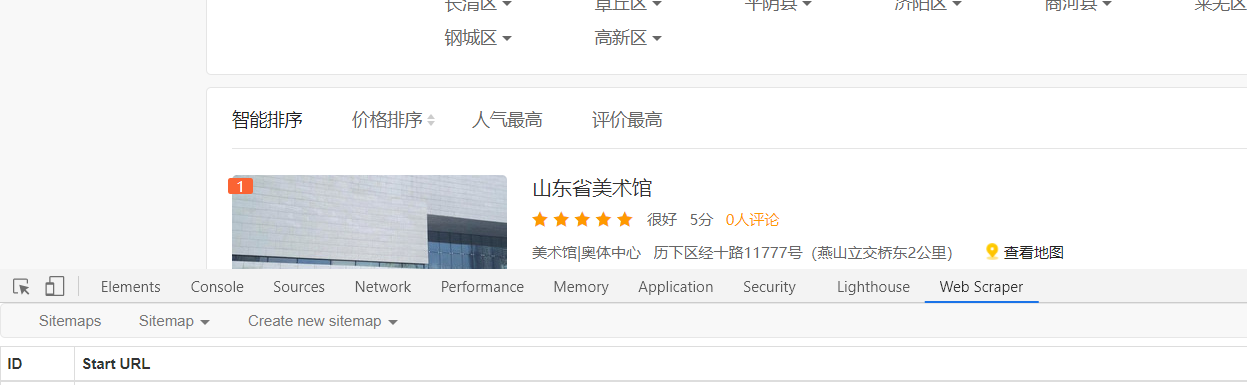
新建一个 sitemap
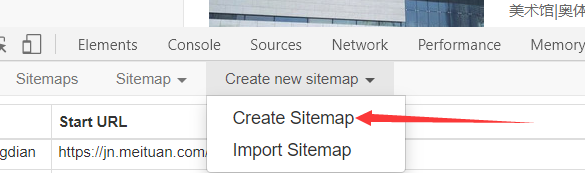
自己起一个名字,URL填写要爬取页面的网址(就是当前页面地址栏的地址,直接复制粘贴就行)
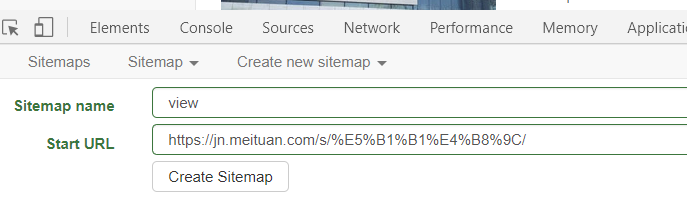
创建完成后,添加一个新的selector
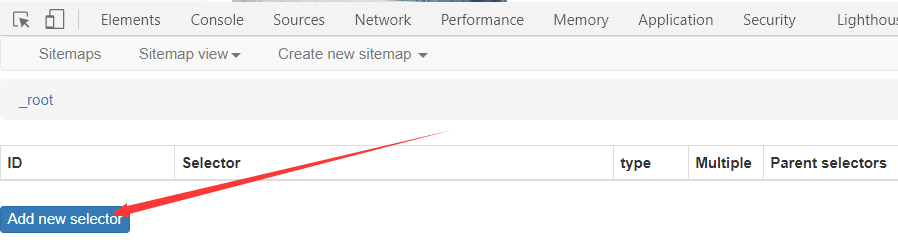
然后按照以下图中的步骤操作

创建完成后
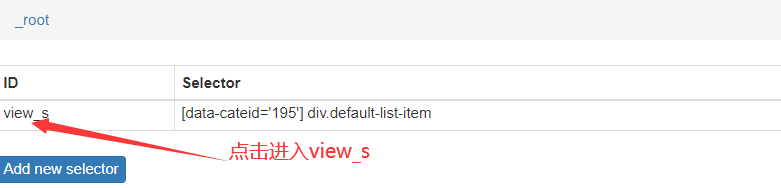
进入view_s
仿照上面的步骤,添加一个新的selector,这个是关于景点的名称的
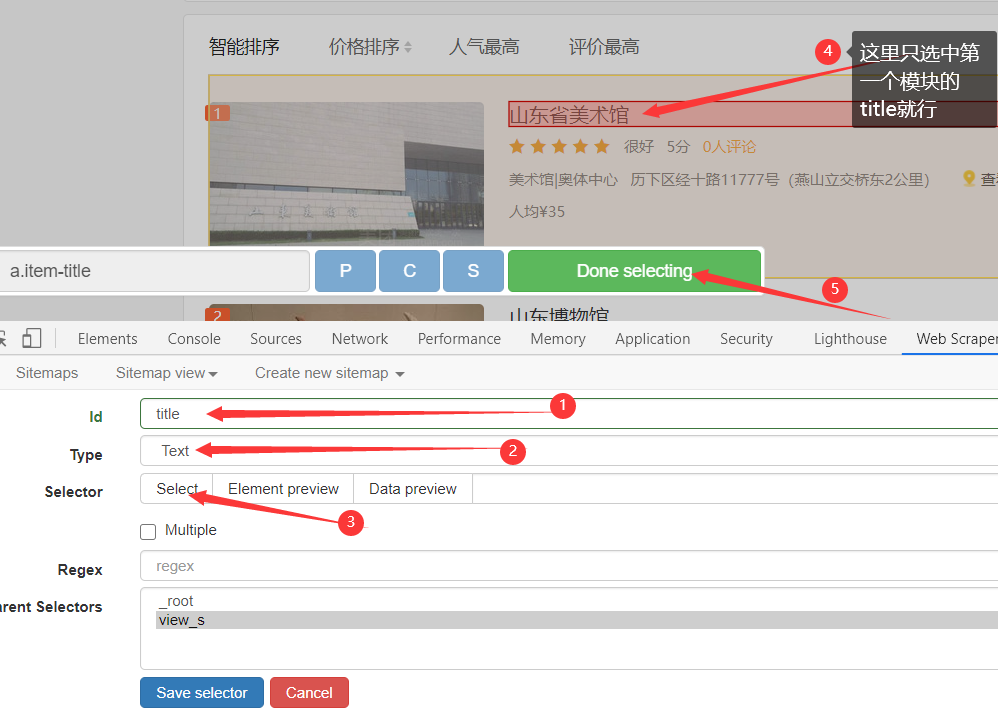
再添加一个新的selector,这个是关于景点位置的,操作如上一步
创建完成之后,如下所示

可以在selector graph中查看结构
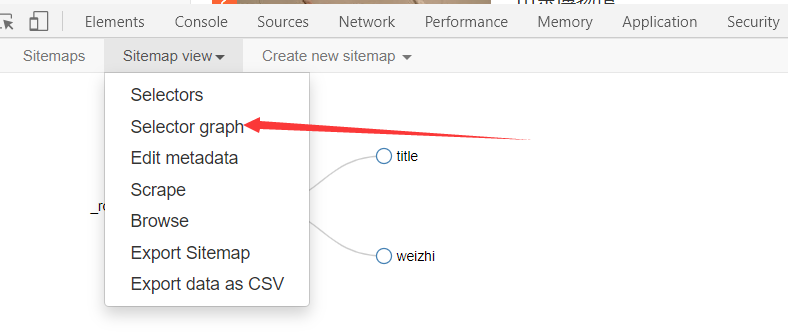
结构如下:

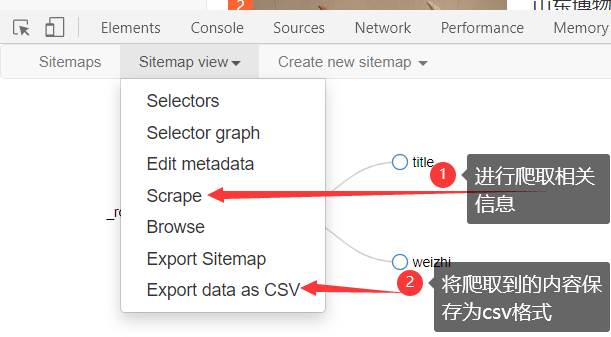
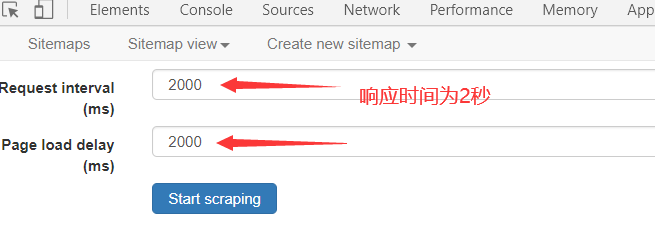
点击scrape进行爬取
响应时间为2秒
爬取完成后点击refresh,更新数据

也可以点击export data as csv,将数据保存为一个csv格式的外部文件