环境说明
采用kubeadm进行kubernetes cluster的安装,一共三个节点,IP地址和主机名如下
172.16.10.102 k8s-master 172.16.10.103 k8s-node1 172.16.10.104 k8s-node2
涉及的操作系统和各软件版本如下
| 系统/软件 | 版本 |
| CentOS7 | CentOS-7-x86_64-1908 |
| docker | docker-ce-18.09.01 |
| kubernetes | 1.16.9 |
| kube-apiserver | 1.16.9 |
| kube-controller-manager | 1.16.9 |
| kube-scheduler | 1.16.9 |
| kube-proxy | 1.16.9 |
| etcd | 3.3.15-0 |
| coredns | 1.6.2 |
| pause | 3.1 |
系统环境准备-每个节点都需要执行
关闭防火墙
systemctl stop firewalld.service
systemctl disable firewalld.service
关闭各节点的selinux
sed -i 's/enforcing/disabled/' /etc/selinux/config setenforce 0
同步时间
yum install -y ntpdate ntpdate -u ntp.api.bz
修改/etc/hosts文件
172.16.10.102 k8s-master 172.16.10.103 k8s-node1 172.16.10.104 k8s-node2
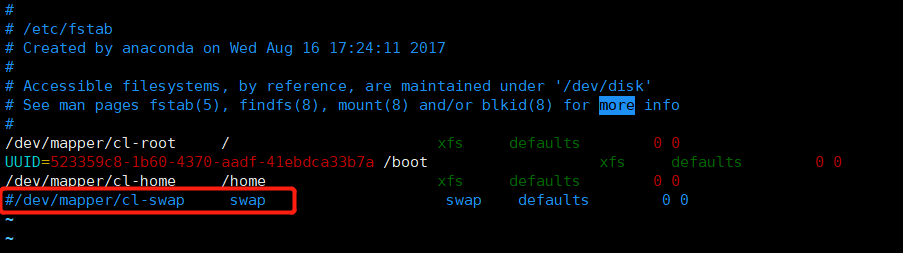
关闭swap
swapoff -a # 临时
vim /etc/fstab #永久
永久关闭
建议打开IP_VS模块
pod的负载均衡是用kube-proxy来实现的,实现方式有两种,一种是默认的iptables,一种是ipvs,ipvs比iptable的性能更好,查看是否开启
cut -f1 -d " " /proc/modules | grep -e ip_vs -e nf_conntrack_ipv4
没有的话,使用以下命令加载
modprobe -- ip_vs modprobe -- ip_vs_rr modprobe -- ip_vs_wrr modprobe -- ip_vs_sh modprobe -- nf_conntrack_ipv4
在各节点安装docker
可以参考 https://developer.aliyun.com/mirror/docker-ce
配置docker的yum源,使用阿里的镜像服务
# step 1: 安装必要的一些系统工具 sudo yum install -y yum-utils device-mapper-persistent-data lvm2 # Step 2: 添加软件源信息 sudo yum-config-manager --add-repo https://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo # Step 3: 更新并安装Docker-CE, sudo yum makecache fast
注意这步是安装最新版,如果不是特别了解的话不建议使用
#sudo yum -y install docker-ce # Step
4: 开启Docker服务 sudo service docker start
可以查看有哪些版本的docker可以安装
[root@docker61 ~]#yum list docker-ce.x86_64 --showduplicates | sort -r Loading mirror speeds from cached hostfile Loaded plugins: fastestmirror Installed Packages docker-ce.x86_64 3:19.03.9-3.el7 docker-ce-stable docker-ce.x86_64 3:19.03.8-3.el7 docker-ce-stable docker-ce.x86_64 3:19.03.7-3.el7 docker-ce-stable docker-ce.x86_64 3:19.03.6-3.el7 docker-ce-stable docker-ce.x86_64 3:19.03.5-3.el7 docker-ce-stable docker-ce.x86_64 3:19.03.4-3.el7 docker-ce-stable docker-ce.x86_64 3:19.03.3-3.el7 docker-ce-stable docker-ce.x86_64 3:19.03.2-3.el7 docker-ce-stable docker-ce.x86_64 3:19.03.1-3.el7 docker-ce-stable docker-ce.x86_64 3:19.03.11-3.el7 docker-ce-stable docker-ce.x86_64 3:19.03.10-3.el7 docker-ce-stable docker-ce.x86_64 3:19.03.0-3.el7 docker-ce-stable docker-ce.x86_64 3:18.09.9-3.el7 docker-ce-stable docker-ce.x86_64 3:18.09.8-3.el7 docker-ce-stable docker-ce.x86_64 3:18.09.7-3.el7 docker-ce-stable docker-ce.x86_64 3:18.09.6-3.el7 docker-ce-stable docker-ce.x86_64 3:18.09.5-3.el7 docker-ce-stable docker-ce.x86_64 3:18.09.4-3.el7 docker-ce-stable docker-ce.x86_64 3:18.09.3-3.el7 docker-ce-stable docker-ce.x86_64 3:18.09.2-3.el7 docker-ce-stable docker-ce.x86_64 3:18.09.1-3.el7 docker-ce-stable docker-ce.x86_64 3:18.09.1-3.el7 @docker-ce-stable docker-ce.x86_64 3:18.09.0-3.el7 docker-ce-stable docker-ce.x86_64 18.06.3.ce-3.el7 docker-ce-stable ... Available Packages
本次选择 18.09.1-3.el7版本
yum install -y docker-ce-18.09.1-3.el7
启动docker
systemctl start docker
systemctl enable docker
安装完成后可通过下面的命令查看
docker version
保证nf-call为1
于docker随后会大量的操作iptables,需要确认nf-call的值是否为1
cat /proc/sys/net/bridge/bridge-nf-call-iptables
cat /proc/sys/net/bridge/bridge-nf-call-ip6tables
执行
docker info | grep -i cgroup
如果出现
WARNING: bridge-nf-call-iptables is disabled
WARNING: bridge-nf-call-ip6tables is disabled
则修改/etc/sysctl.conf文件
net.bridge.bridge-nf-call-iptables = 1
net.bridge.bridge-nf-call-ip6tables = 1
然后执行命令
[root@master ~]# sysctl -p
net.bridge.bridge-nf-call-iptables = 1
net.bridge.bridge-nf-call-ip6tables = 1
安装kubeadm、kubelet、kubectl
安装kubernetes的yum源,采用阿里的镜像
可以参考https://developer.aliyun.com/mirror/kubernetes
在/etc/yum.repo.d/中新建文件kubernetes.repo,文件内容如下
[kubernetes] name=Kubernetes baseurl=https://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64 enabled=1 gpgcheck=1 repo_gpgcheck=1 gpgkey=https://mirrors.aliyun.com/kubernetes/yum/doc/yum-key.gpg https://mirrors.aliyun.com/kubernetes/yum/doc/rpm-package-key.gpg
执行
yum makecache fast
查看可用的kubernetes版本
yum list kubeadm --showduplicates | sort -r
kubeadm.x86_64 1.18.4-0 kubernetes kubeadm.x86_64 1.18.3-0 kubernetes kubeadm.x86_64 1.18.2-0 kubernetes kubeadm.x86_64 1.18.1-0 kubernetes kubeadm.x86_64 1.18.0-0 kubernetes kubeadm.x86_64 1.17.7-0 kubernetes kubeadm.x86_64 1.17.6-0 kubernetes kubeadm.x86_64 1.17.5-0 kubernetes kubeadm.x86_64 1.17.4-0 kubernetes kubeadm.x86_64 1.17.3-0 kubernetes kubeadm.x86_64 1.17.2-0 kubernetes kubeadm.x86_64 1.17.1-0 kubernetes kubeadm.x86_64 1.17.0-0 kubernetes kubeadm.x86_64 1.16.9-0 kubernetes kubeadm.x86_64 1.16.8-0 kubernetes kubeadm.x86_64 1.16.7-0 kubernetes kubeadm.x86_64 1.16.6-0 kubernetes kubeadm.x86_64 1.16.5-0 kubernetes kubeadm.x86_64 1.16.4-0 kubernetes kubeadm.x86_64 1.16.3-0 kubernetes kubeadm.x86_64 1.16.2-0 kubernetes ...
本次安装采用 1.16.9
yum install -y kubeadm-1.16.9-0 kubealet-1.16.9-0 kubectl-1.16.9-0
采用上面的命令会出现如下错误
Error: Package: kubeadm-1.16.9-0.x86_64 (kubernetes) Requires: kubernetes-cni >= 0.7.5 Available: kubernetes-cni-0.3.0.1-0.07a8a2.x86_64 (kubernetes) kubernetes-cni = 0.3.0.1-0.07a8a2 Available: kubernetes-cni-0.5.1-0.x86_64 (kubernetes) kubernetes-cni = 0.5.1-0 Available: kubernetes-cni-0.5.1-1.x86_64 (kubernetes) kubernetes-cni = 0.5.1-1 Available: kubernetes-cni-0.6.0-0.x86_64 (kubernetes) kubernetes-cni = 0.6.0-0 Available: kubernetes-cni-0.7.5-0.x86_64 (kubernetes) kubernetes-cni = 0.7.5-0 You could try using --skip-broken to work around the problem You could try running: rpm -Va --nofiles --nodigest
问题原因是,在新的版本中,kubernetes-cni组件安装包的功能已经被kubelet替代,yum这时会进行解析并给出提示,此时也不能直接使用 yum安装 kubernetes-cni-0.7.5.0-0,因为一旦执行yum会自动安装最新版本的kubelet,而不是我们指定的版本。
本文编写时,最新版本是1.18.4-0,所以采用如下命令进行安装
yum install -y kubeadm-1.16.9-0 kubelet-1.16.9-0 kubectl-1.16.9-0 --exclude kubelet-1.18.4-0
执行
yum list installed | grep kube
确保结果如下:

准备kebernetes所需组件的镜像
kubernetes正常工作需要 kubernetes-proxy,kubernetes-apiserver,kubernetes-scheduler,kubernetes-controller-manager以及etcd,pause,coredns,flannel等组件的镜像,由于这些镜像都在google的镜像仓库中,下载较慢,所以需要使用阿里的镜像进行下载,下载完成后通过 docker tag命令修改镜像名称,以便kubernetes能够发现和使用
docker pull registry.cn-hangzhou.aliyuncs.com/google_containers/kube-apiserver-amd64:v1.16.9 docker pull registry.cn-hangzhou.aliyuncs.com/google_containers/kube-proxy-amd64:v1.16.9 docker pull registry.cn-hangzhou.aliyuncs.com/google_containers/kube-controller-manager-amd64:v1.16.9 docker pull registry.cn-hangzhou.aliyuncs.com/google_containers/kube-scheduler-amd64:v1.16.9 docker pull registry.cn-hangzhou.aliyuncs.com/google_containers/etcd-amd64:3.3.15-0
docker pull registry.cn-hangzhou.aliyuncs.com/google_containers/pause:3.1
docker pull registry.cn-hangzhou.aliyuncs.com/google_containers/coredns:1.6.2
docker pull quay.io/coreos/flannel:v0.12.0-amd64
修改名称
docker tag registry.cn-hangzhou.aliyuncs.com/google_containers/kube-apiserver-amd64:v1.16.9 k8s.gcr.io/kube-apiserver:v1.16.9 docker tag registry.cn-hangzhou.aliyuncs.com/google_containers/kube-proxy-amd64:v1.16.9 k8s.gcr.io/kube-proxy:v1.16.9 docker tag registry.cn-hangzhou.aliyuncs.com/google_containers/kube-controller-manager-amd64:v1.16.9 k8s.gcr.io/kube-controller-manager:v1.16.9 docker tag registry.cn-hangzhou.aliyuncs.com/google_containers/kube-scheduler-amd64:v1.16.9 k8s.gcr.io/kube-scheduler:v1.16.9 docker tag registry.cn-hangzhou.aliyuncs.com/google_containers/etcd-amd64:3.3.15-0 k8s.gcr.io/etcd:3.3.15-0 docker tag registry.cn-hangzhou.aliyuncs.com/google_containers/pause:3.1 k8s.gcr.io/pause:3.1 docker tag registry.cn-hangzhou.aliyuncs.com/google_containers/coredns:1.6.2 k8s.gcr.io/coredns:1.6.2
docker images查看如下
REPOSITORY TAG IMAGE ID CREATED SIZE registry.cn-hangzhou.aliyuncs.com/google_containers/kube-controller-manager-amd64 v1.16.9 b6f6512bb3ba 2 months ago 152MB k8s.gcr.io/kube-controller-manager v1.16.9 b6f6512bb3ba 2 months ago 152MB k8s.gcr.io/kube-apiserver v1.16.9 dd3b6beaa554 2 months ago 160MB registry.cn-hangzhou.aliyuncs.com/google_containers/kube-apiserver-amd64 v1.16.9 dd3b6beaa554 2 months ago 160MB k8s.gcr.io/kube-proxy v1.16.9 a197b1cf22e3 2 months ago 82.8MB registry.cn-hangzhou.aliyuncs.com/google_containers/kube-proxy-amd64 v1.16.9 a197b1cf22e3 2 months ago 82.8MB registry.cn-hangzhou.aliyuncs.com/google_containers/kube-scheduler-amd64 v1.16.9 476ac3ab84e5 2 months ago 83.6MB k8s.gcr.io/kube-scheduler v1.16.9 476ac3ab84e5 2 months ago 83.6MB k8s.gcr.io/etcd 3.3.15-0 b2756210eeab 9 months ago 247MB registry.cn-hangzhou.aliyuncs.com/google_containers/etcd-amd64 3.3.15-0 b2756210eeab 9 months ago 247MB k8s.gcr.io/coredns 1.6.2 bf261d157914 10 months ago 44.1MB registry.cn-hangzhou.aliyuncs.com/google_containers/coredns 1.6.2 bf261d157914 10 months ago 44.1MB k8s.gcr.io/pause 3.1 da86e6ba6ca1 2 years ago 742kB registry.cn-hangzhou.aliyuncs.com/google_containers/pause 3.1 da86e6ba6ca1 2 years ago 742kB
关于etcd,pause和coredns版本的确定
可以先安装指定版本的kubeadm,然后执行
kubeadm config images list
结果如下:
I0623 22:13:15.868280 9670 version.go:251] remote version is much newer: v1.18.4; falling back to: stable-1.16 k8s.gcr.io/kube-apiserver:v1.16.11 k8s.gcr.io/kube-controller-manager:v1.16.11 k8s.gcr.io/kube-scheduler:v1.16.11 k8s.gcr.io/kube-proxy:v1.16.11 k8s.gcr.io/pause:3.1 k8s.gcr.io/etcd:3.3.15-0 k8s.gcr.io/coredns:1.6.2
根据结果可以选择需要的etcd,pause和coredns进行下载
配置kubelet的cgroup drive
确保docker 的cgroup drive 和kubelet的cgroup drive一样
[root@k8s-node1 ~]# cat /etc/systemd/system/kubelet.service.d/10-kubeadm.conf cat: /etc/systemd/system/kubelet.service.d/10-kubeadm.conf: No such file or directory 如果提示找不到该文件,就再去我们的:/usr/lib/systemd/system/kubelet.service.d/10-kubeadm.conf [root@k8s-node1 ~]# cat /usr/lib/systemd/system/kubelet.service.d/10-kubeadm.conf # Note: This dropin only works with kubeadm and kubelet v1.11+ [Service] Environment="KUBELET_KUBECONFIG_ARGS=--bootstrap-kubeconfig=/etc/kubernetes/bootstrap-kubelet.conf --kubeconfig=/etc/kubernetes/kubelet.conf" Environment="KUBELET_CONFIG_ARGS=--config=/var/lib/kubelet/config.yaml" # This is a file that "kubeadm init" and "kubeadm join" generates at runtime, populating the KUBELET_KUBEADM_ARGS variable dynamically EnvironmentFile=-/var/lib/kubelet/kubeadm-flags.env # This is a file that the user can use for overrides of the kubelet args as a last resort. Preferably, the user should use # the .NodeRegistration.KubeletExtraArgs object in the configuration files instead. KUBELET_EXTRA_ARGS should be sourced from this file. EnvironmentFile=-/etc/sysconfig/kubelet ExecStart= ExecStart=/usr/bin/kubelet $KUBELET_KUBECONFIG_ARGS $KUBELET_CONFIG_ARGS $KUBELET_KUBEADM_ARGS $KUBELET_EXTRA_ARGS [root@k8s-node1 ~]#
没有的话,加入进去
Environment="KUBELET_CGROUP_ARGS=--cgroup-driver=cgroupfs"
然后重新加载
systemctl daemon-reload
至此单个节点的环境配置完成,一定要注意的是,如果采用的是克隆虚拟机的方式组建集群的话,一定要保证三个节点的hostname不同,并且hostname要写入/etc/hosts,否则后续工作节点加入的时候,会出很多莫名其妙的问题
初始化kubernetes master节点
在Master主节点(k8s-master)上执行
kubeadm init --pod-network-cidr=10.244.0.0/16 --kubernetes-version=v1.16.9 --apiserver-advertise-address=172.16.10.102
含义: 1.选项--pod-network-cidr=10.244.0.0/16表示集群将使用Calico网络,这里需要提前指定Calico的子网范围 2.选项--kubernetes-version=v1.16.9 指定K8S版本,这里必须与之前导入到Docker镜像版本一致,否则会访问谷歌去重新下载K8S最新版的Docker镜像 3.选项--apiserver-advertise-address表示绑定的网卡IP 4.若执行kubeadm init出错或强制终止,则再需要执行该命令时,需要先执行kubeadm reset重置
如果出现下面报错:
ERROR FileContent--proc-sys-net-bridge-bridge-nf-call-iptables]: /proc/sys/net/bridge/bridge-nf-call-iptables contents are not set to 1 [preflight] If you know what you are doing, you can make a check non-fatal with `--ignore-preflight-errors=...`
则执行
echo "1" >/proc/sys/net/bridge/bridge-nf-call-iptables
然后再重新操作:
root@k8s-master ~]# kubeadm init --pod-network-cidr=10.244.0.0/16 --kubernetes-version=v1.16.9 --apiserver-advertise-address=172.16.10.102 [init] Using Kubernetes version: v1.16.9 [preflight] Running pre-flight checks [WARNING IsDockerSystemdCheck]: detected "cgroupfs" as the Docker cgroup driver. The recommended driver is "systemd". Please follow the guide at https://kubernetes.io/docs/setup/cri/ [WARNING Service-Kubelet]: kubelet service is not enabled, please run 'systemctl enable kubelet.service' [preflight] Pulling images required for setting up a Kubernetes cluster [preflight] This might take a minute or two, depending on the speed of your internet connection [preflight] You can also perform this action in beforehand using 'kubeadm config images pull' [kubelet-start] Writing kubelet environment file with flags to file "/var/lib/kubelet/kubeadm-flags.env" [kubelet-start] Writing kubelet configuration to file "/var/lib/kubelet/config.yaml" [kubelet-start] Activating the kubelet service [certs] Using certificateDir folder "/etc/kubernetes/pki" [certs] Generating "ca" certificate and key [certs] Generating "apiserver" certificate and key [certs] apiserver serving cert is signed for DNS names [k8s-master kubernetes kubernetes.default kubernetes.default.svc kubernetes.default.svc.cluster.local] and IPs [10.96.0.1 172.16.10.102] [certs] Generating "apiserver-kubelet-client" certificate and key [certs] Generating "front-proxy-ca" certificate and key [certs] Generating "front-proxy-client" certificate and key [certs] Generating "etcd/ca" certificate and key [certs] Generating "etcd/server" certificate and key [certs] etcd/server serving cert is signed for DNS names [k8s-master localhost] and IPs [172.16.10.102 127.0.0.1 ::1] [certs] Generating "etcd/peer" certificate and key [certs] etcd/peer serving cert is signed for DNS names [k8s-master localhost] and IPs [172.16.10.102 127.0.0.1 ::1] [certs] Generating "etcd/healthcheck-client" certificate and key [certs] Generating "apiserver-etcd-client" certificate and key [certs] Generating "sa" key and public key [kubeconfig] Using kubeconfig folder "/etc/kubernetes" [kubeconfig] Writing "admin.conf" kubeconfig file [kubeconfig] Writing "kubelet.conf" kubeconfig file [kubeconfig] Writing "controller-manager.conf" kubeconfig file [kubeconfig] Writing "scheduler.conf" kubeconfig file [control-plane] Using manifest folder "/etc/kubernetes/manifests" [control-plane] Creating static Pod manifest for "kube-apiserver" [control-plane] Creating static Pod manifest for "kube-controller-manager" [control-plane] Creating static Pod manifest for "kube-scheduler" [etcd] Creating static Pod manifest for local etcd in "/etc/kubernetes/manifests" [wait-control-plane] Waiting for the kubelet to boot up the control plane as static Pods from directory "/etc/kubernetes/manifests". This can take up to 4m0s [kubelet-check] Initial timeout of 40s passed. [apiclient] All control plane components are healthy after 45.004988 seconds [upload-config] Storing the configuration used in ConfigMap "kubeadm-config" in the "kube-system" Namespace [kubelet] Creating a ConfigMap "kubelet-config-1.16" in namespace kube-system with the configuration for the kubelets in the cluster [upload-certs] Skipping phase. Please see --upload-certs [mark-control-plane] Marking the node k8s-master as control-plane by adding the label "node-role.kubernetes.io/master=''" [mark-control-plane] Marking the node k8s-master as control-plane by adding the taints [node-role.kubernetes.io/master:NoSchedule] [bootstrap-token] Using token: 7wogu3.yko2b420q8gib6id [bootstrap-token] Configuring bootstrap tokens, cluster-info ConfigMap, RBAC Roles [bootstrap-token] configured RBAC rules to allow Node Bootstrap tokens to post CSRs in order for nodes to get long term certificate credentials [bootstrap-token] configured RBAC rules to allow the csrapprover controller automatically approve CSRs from a Node Bootstrap Token [bootstrap-token] configured RBAC rules to allow certificate rotation for all node client certificates in the cluster [bootstrap-token] Creating the "cluster-info" ConfigMap in the "kube-public" namespace [addons] Applied essential addon: CoreDNS [addons] Applied essential addon: kube-proxy Your Kubernetes control-plane has initialized successfully! To start using your cluster, you need to run the following as a regular user: mkdir -p $HOME/.kube sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config sudo chown $(id -u):$(id -g) $HOME/.kube/config You should now deploy a pod network to the cluster. Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at: https://kubernetes.io/docs/concepts/cluster-administration/addons/ Then you can join any number of worker nodes by running the following on each as root: kubeadm join 172.16.10.102:6443 --token 7wogu3.yko2b420q8gib6id --discovery-token-ca-cert-hash sha256:158b1f66371f64d1922b1ae5d2917c77955c83699f3bb276a74241834721e110
如上结果表明已经初始化完成,为了后续操作,需要执行红色字体提示的下一步操作,并记录
kubeadm join 172.16.10.102:6443 --token 7wogu3.yko2b420q8gib6id --discovery-token-ca-cert-hash sha256:158b1f66371f64d1922b1ae5d2917c77955c83699f3bb276a74241834721e110
首先执行
mkdir -p $HOME/.kube sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config sudo chown $(id -u):$(id -g) $HOME/.kube/config
然后查看
kubectl get nodes
此时的结果是
NAME STATUS ROLES AGE VERSION k8s-master NotReady master 3m52s v1.16.9
注意此时master的状态是 NotReady
具体查看
kubectl get pods -n kube-system
结果

此时在执行提示信息中的下一步,即Run "kubectl apply -f [podnetwork].yaml" with one of the options listed
下载kube-flannel.yml
wget https://raw.githubusercontent.com/coreos/flannel/v0.12.0/Documentation/kube-flannel.yml
然后执行
[root@k8s-master ~]# kubectl apply -f ./kube-flannel.yml podsecuritypolicy.policy/psp.flannel.unprivileged created clusterrole.rbac.authorization.k8s.io/flannel created clusterrolebinding.rbac.authorization.k8s.io/flannel created serviceaccount/flannel created configmap/kube-flannel-cfg created daemonset.apps/kube-flannel-ds-amd64 created daemonset.apps/kube-flannel-ds-arm64 created daemonset.apps/kube-flannel-ds-arm created daemonset.apps/kube-flannel-ds-ppc64le created daemonset.apps/kube-flannel-ds-s390x created
此时再次查看
kubectl get pods -n kube-system
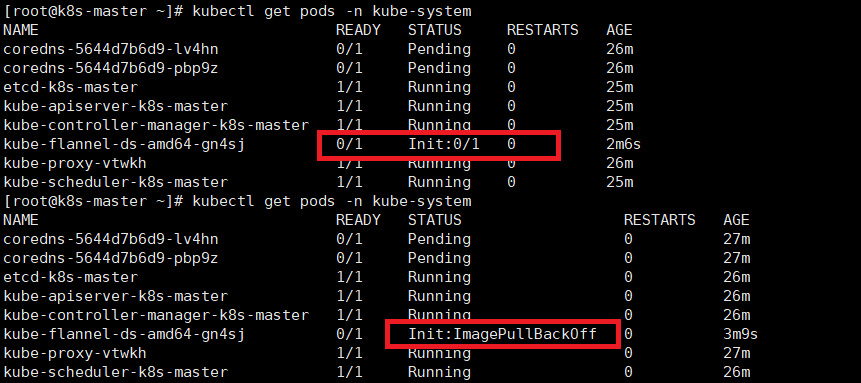
pod的初始化过程会持续一段时间,最终结果如下


至此,master节点已经完成初始化
将Master作为工作节点-非必须
K8S集群默认不会将Pod调度到Master上,这样Master的资源就浪费了。在Master(即k8s-master)上,可以运行以下命令使其作为一个工作节点:(利用该方法,我们可以不使用minikube而创建一个单节点的K8S集群)
kubectl taint nodes --all node-role.kubernetes.io/master-node/k8s-master untainted
加入工作节点-在node1和node2节点上执行
为了避免错误,首先在各node节点上执行
echo "1" >/proc/sys/net/bridge/bridge-nf-call-iptables
systemctl enable kubelet.service
执行加入操作(集群初始化时的提示信息)
kubeadm join 172.16.10.102:6443 --token 7wogu3.yko2b420q8gib6id --discovery-token-ca-cert-hash sha256:158b1f66371f64d1922b1ae5d2917c77955c83699f3bb276a74241834721e110
如果出现
error execution phase preflight: couldn't validate the identity of the API Server: abort connecting to API servers after timeout of 5m0s To see the stack trace of this error execute with --v=5 or higher
则有三种可能
第一,token过期,执行
kubeadm token create --print-join-command
重新获取加入命令
第二,防火墙没有关,关闭防火墙
第三,开启了iptables.service服务,为了试验方便,彻底移除该服务
yum install -y iptables-services
执行成功结果
[kubelet-start] Waiting for the kubelet to perform the TLS Bootstrap... This node has joined the cluster: * Certificate signing request was sent to apiserver and a response was received. * The Kubelet was informed of the new secure connection details. Run 'kubectl get nodes' on the control-plane to see this node join the cluster.
此时在工作节点上执行
kubectl get nodes
如果出现
The connection to the server localhost:8080 was refused - did you specify the right host or port?
解决方法如下
第一种,将主节点中的【/etc/kubernetes/admin.conf】文件拷贝到从节点相同目录下,然后配置环境变量:
echo "export KUBECONFIG=/etc/kubernetes/admin.conf" >> ~/.bash_profile
source ~/.bash_profile
第二种,将主节点中的【/etc/kubernetes/admin.conf】文件拷贝到从节点相同目录下,然后执行
mkdir -p $HOME/.kube sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config sudo chown $(id -u):$(id -g) $HOME/.kube/config
再运行kubectl命令就成功了
