题目背景
滚粗了的HansBug在收拾旧英语书,然而他发现了什么奇妙的东西。
题目描述
udp2.T3如果遇到相同的字符串,输出后面的
蒟蒻HansBug在一本英语书里面找到了一个单词表,包含N个单词(每个单词内包含大小写字母)。现在他想要找出某一段连续的单词内字典序最大的单词。
输入输出格式
输入格式:
第一行包含两个正整数N、M,分别表示单词个数和询问个数。
接下来N行每行包含一个字符串,仅包含大小写字母,长度不超过15,表示一个单词。
再接下来M行每行包含两个整数x、y,表示求从第x到第y个单词中字典序最大的单词。
输出格式:
输出包含M行,每行为一个字符串,分别依次对应前面M个询问的结果。
输入输出样例
说明
样例说明:
第一次操作:在{absi,hansbug,lzn,kkk,yyy}中找出字典序最大的,故为yyy
第二次操作:在{absi}中找出字典序最大的,故为absi
第三次操作:在{absi,hansbug}中找出字典序最大的,故为hansbug
第四次操作:在{hansbug,lzn}中找出字典序最大的,故为lzn
第五次操作:在{kkk}中找出字典序最大的,故为kkk
数据规模:
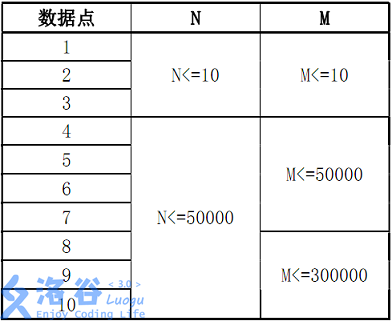
注意事项:1.该题目单词字典序比对过程中大小写不敏感,但是输出必须输出原单词
2.该题目时间限制为0.2s
思路:天啦噜!!线段树竟然TLE,但是模拟却AC了。
#include<cstdio> #include<cstring> #include<iostream> #include<algorithm> using namespace std; int n,m; string c1; struct Name{ string c,s; int id; }name[50005]; bool cmp(Name x,Name y){ return x.s>y.s; } int main(){ scanf("%d%d",&n,&m); for(int i=1;i<=n;i++){ cin>>c1;int l=sizeof(c1); name[i].c=c1; for(int j=0;j<l;j++){ if(c1[j]<='Z'&&c1[j]>='A') c1[j]=c1[j]-'A'+'a'; else c1[j]=c1[j]; } name[i].s=c1; name[i].id=i; } sort(name+1,name+1+n,cmp); for(int i=1,x,y;i<=m;i++){ scanf("%d%d",&x,&y); int j=1; while(1){ if(name[j].id>=x&&name[j].id<=y) break; j++; } cout<<name[j].c<<endl; } return 0; }