一、创建数据集
R语言中创建或导入数据框是非常常见的,只需要一个data.frame的命令就可以了,这个是R语言的基本命令。
我不习惯用Python进行表格式的数据操作和分析,这次和阿雷一起学习如何在Python中使用pandas库来进行基本的数据框操作。
首先当然是要安装pandas库,这个在上一篇文章中已经写过了,
其次就是要加载这个库,python中可以使用命令:

1、使用DataFrame()命令,来创建数据框(这个命令的含义是,括号里面的数据类型,捆绑成数据框的形式)
2. 我这里使用的是字典,索引‘a’和‘b’分别可以看成是列名,然后每一列下面的值就是序列,使用命令range生成,也就是值包含了很多值(因为range生成的不只是一个数)
3. 我还想试试字典里面的值不是range,而是列表

经过实践,这样也是可以的!!
4. 在Rstudio这样的编译器中,可以很方便地可视化看到我们的数据结构是如何的,这里我们也可以。直接双击右侧变量管理中的value值,就可以看到啦
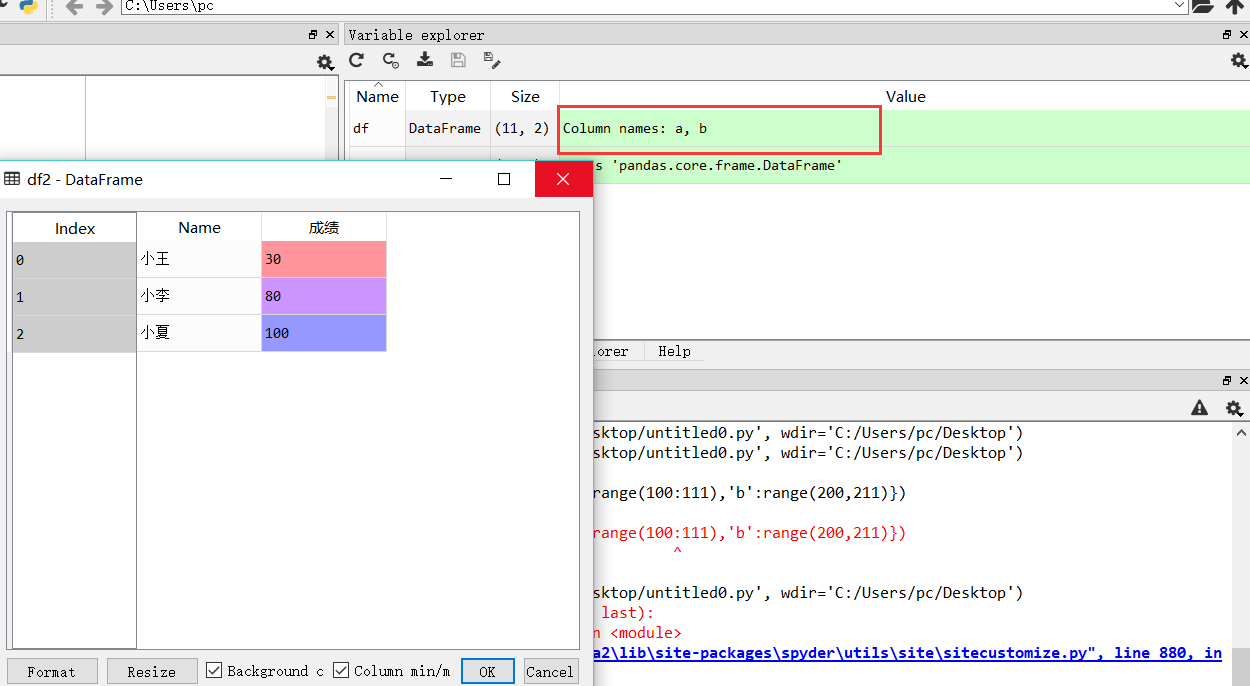
这样一来,我觉得Spyder的编译器和Studio也很类似,编译环境变得异常友好起来!
二、外部数据集导入
学习了如何创建数据集,下面开始学习数据集如何导入。
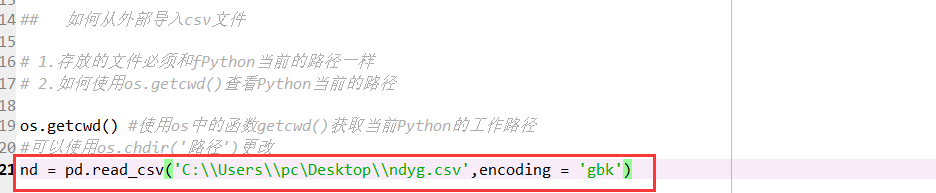
1. 导入的文件必须是存放在Python当前的路径
2. 如何查看Python当前的路径:import os之后,os.getcwd(),也可以使用ios.chdir()更换文件所在路径
3.使用pd.read_csv('文件名及后缀',encoding = 'dbk') 这里如果你的表格有中文,要加一个参数encoding = 'gbk',如果不是的话,那么就不必了,如果操作系统是MAC的话,就换成utf-8
4.如果是exlce文件,可以使用pd.read_excel('文件名.xlsx',encoding = 'gbk')
三、数据导出
假设一个数据df2已经存放在了Python环境中,使用df.to_csv('导出后的文件名和后缀'),就可以了
