内存不足时group by操作失败。
正常应该速度变慢,而不是失败,因为还有磁盘可用
错误日志:
Task:
java.io.IOException: Filesystem closed
atorg.apache.hadoop.hdfs.DFSClient.checkOpen(DFSClient.java:765)
atorg.apache.hadoop.hdfs.DFSInputStream.readWithStrategy(DFSInputStream.java:783)
atorg.apache.hadoop.hdfs.DFSInputStream.read(DFSInputStream.java:844)
atjava.io.DataInputStream.read(DataInputStream.java:100)
atorg.apache.hadoop.util.LineReader.fillBuffer(LineReader.java:180)
atorg.apache.hadoop.util.LineReader.readDefaultLine(LineReader.java:216)
atorg.apache.hadoop.util.LineReader.readLine(LineReader.java:174)
atorg.apache.hadoop.mapred.LineRecordReader.next(LineRecordReader.java:246)
atorg.apache.hadoop.mapred.LineRecordReader.next(LineRecordReader.java:47)
atorg.apache.spark.rdd.HadoopRDD$$anon$1.getNext(HadoopRDD.scala:244)
atorg.apache.spark.rdd.HadoopRDD$$anon$1.getNext(HadoopRDD.scala:210)
atorg.apache.spark.util.NextIterator.hasNext(NextIterator.scala:71)
atorg.apache.spark.InterruptibleIterator.hasNext(InterruptibleIterator.scala:39)
atscala.collection.Iterator$$anon$11.hasNext(Iterator.scala:327)
atscala.collection.Iterator$$anon$11.hasNext(Iterator.scala:327)
atorg.apache.spark.sql.execution.Aggregate
atorg.apache.spark.sql.execution.Aggregate
atorg.apache.spark.rdd.RDD$$anonfun$13.apply(RDD.scala:601)
atorg.apache.spark.rdd.RDD$$anonfun$13.apply(RDD.scala:601)
atorg.apache.spark.rdd.MapPartitionsRDD.compute(MapPartitionsRDD.scala:35)
atorg.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:263)
atorg.apache.spark.rdd.RDD.iterator(RDD.scala:230)
atorg.apache.spark.rdd.MapPartitionsRDD.compute(MapPartitionsRDD.scala:35)
atorg.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:263)
atorg.apache.spark.rdd.RDD.iterator(RDD.scala:230)
atorg.apache.spark.scheduler.ShuffleMapTask.runTask(ShuffleMapTask.scala:68)
atorg.apache.spark.scheduler.ShuffleMapTask.runTask(ShuffleMapTask.scala:41)
atorg.apache.spark.scheduler.Task.run(Task.scala:56)
atorg.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:196)
atjava.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1145)
atjava.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:615)
atjava.lang.Thread.run(Thread.java:745)
2 数据
6.7 G 20.1 G /user/hive/warehouse/ldp.db/bigt2_2
Key数量:1亿
总条数:1亿
Shuffle write 2GB
Shuffle read 1.5GB
3 语句
4 GC测试
4.1 G1
spark-shell--num-executors 3 --executor-memory 12g --executor-cores 3 --driver-memory 2g--master yarn-client --conf spark.dynamicAllocation.enabled=false --confspark.shuffle.service.enabled=false --conf spark.shuffle.compress=true --confspark.shuffle.manager=sort --conf spark.sql.shuffle.partitions=20 --confspark.executor.extraJavaOptions="-XX:+UseG1GC -XX:+PrintFlagsFinal-XX:+PrintReferenceGC -verbose:gc -XX:+PrintGCDetails -XX:+PrintGCTimeStamps-XX:+PrintAdaptiveSizePolicy -XX:+UnlockDiagnosticVMOptions-XX:+G1SummarizeConcMark -XX:InitiatingHeapOccupancyPercent=45" --confspark.shuffle.file.buffer.kb=10240 --conf spark.storage.memoryFraction=0.2--conf spark.shuffle.memoryFraction=0.6
stage1 + staage2 3.4 + 2.2 min
GC时间,max=25s 75%=5s
Stage1
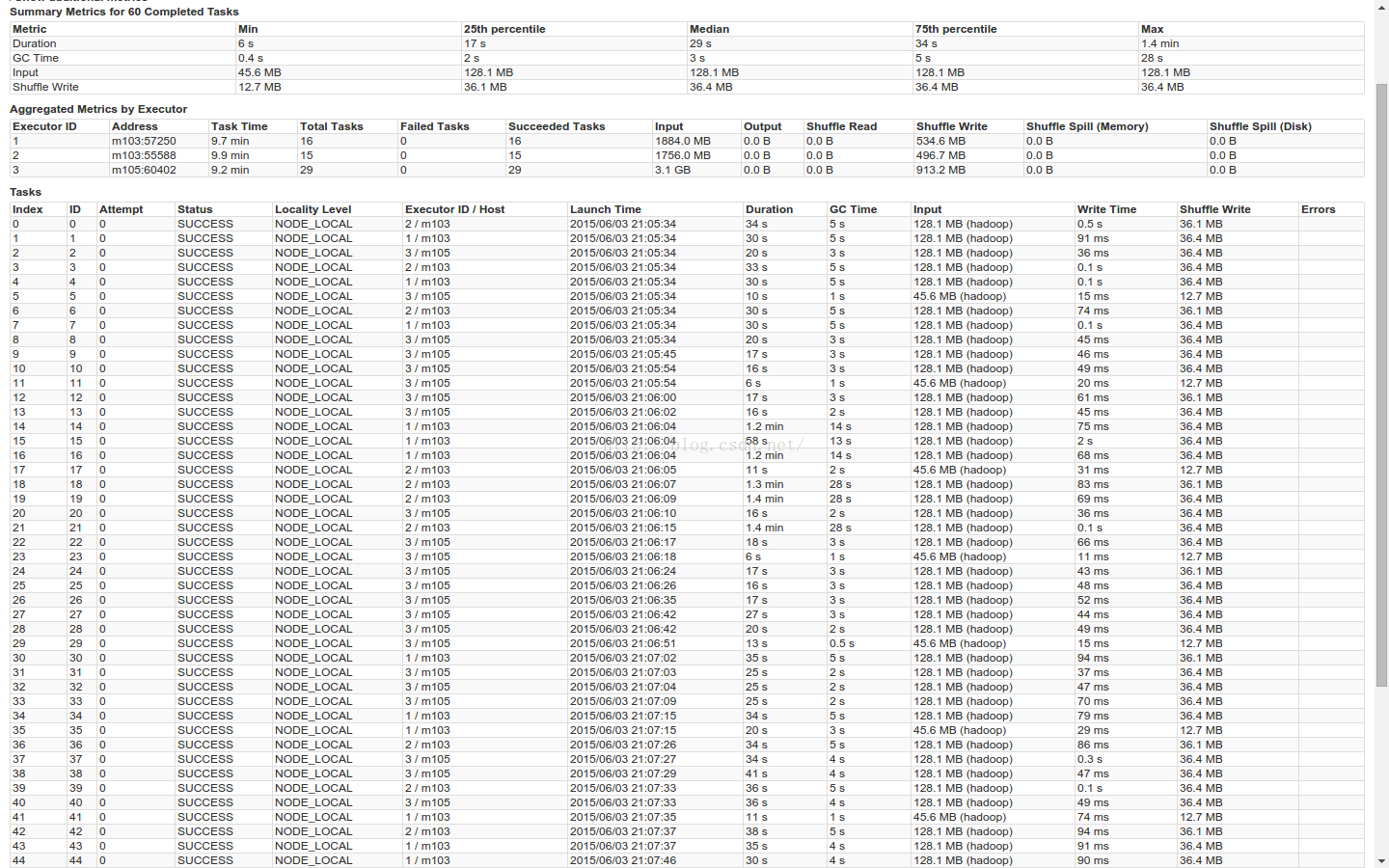
Stage2

4.2 Paralle
spark-shell--num-executors 3 --executor-memory 12g --executor-cores 3 --driver-memory 2g--master yarn-client --conf spark.dynamicAllocation.enabled=false --confspark.shuffle.service.enabled=false --conf spark.shuffle.compress=true --confspark.shuffle.manager=sort --conf spark.sql.shuffle.partitions=20 --confspark.executor.extraJavaOptions="-XX:+UseParallelGC-Xmn8g -XX:+PrintFlagsFinal-XX:+PrintReferenceGC -verbose:gc -XX:+PrintGCDetails -XX:+PrintGCTimeStamps-XX:+PrintAdaptiveSizePolicy -XX:+UnlockDiagnosticVMOptions-XX:+G1SummarizeConcMark" --conf spark.shuffle.file.buffer.kb=10240 --confspark.storage.memoryFraction=0.2 --conf spark.shuffle.memoryFraction=0.6
注:Xmn为新生代大小,且最大值和初始值相等。
stage1 + staage2 5.7 + 1.5 min
GC时间 max=4.7min 75%=15s
stage1

Stage2
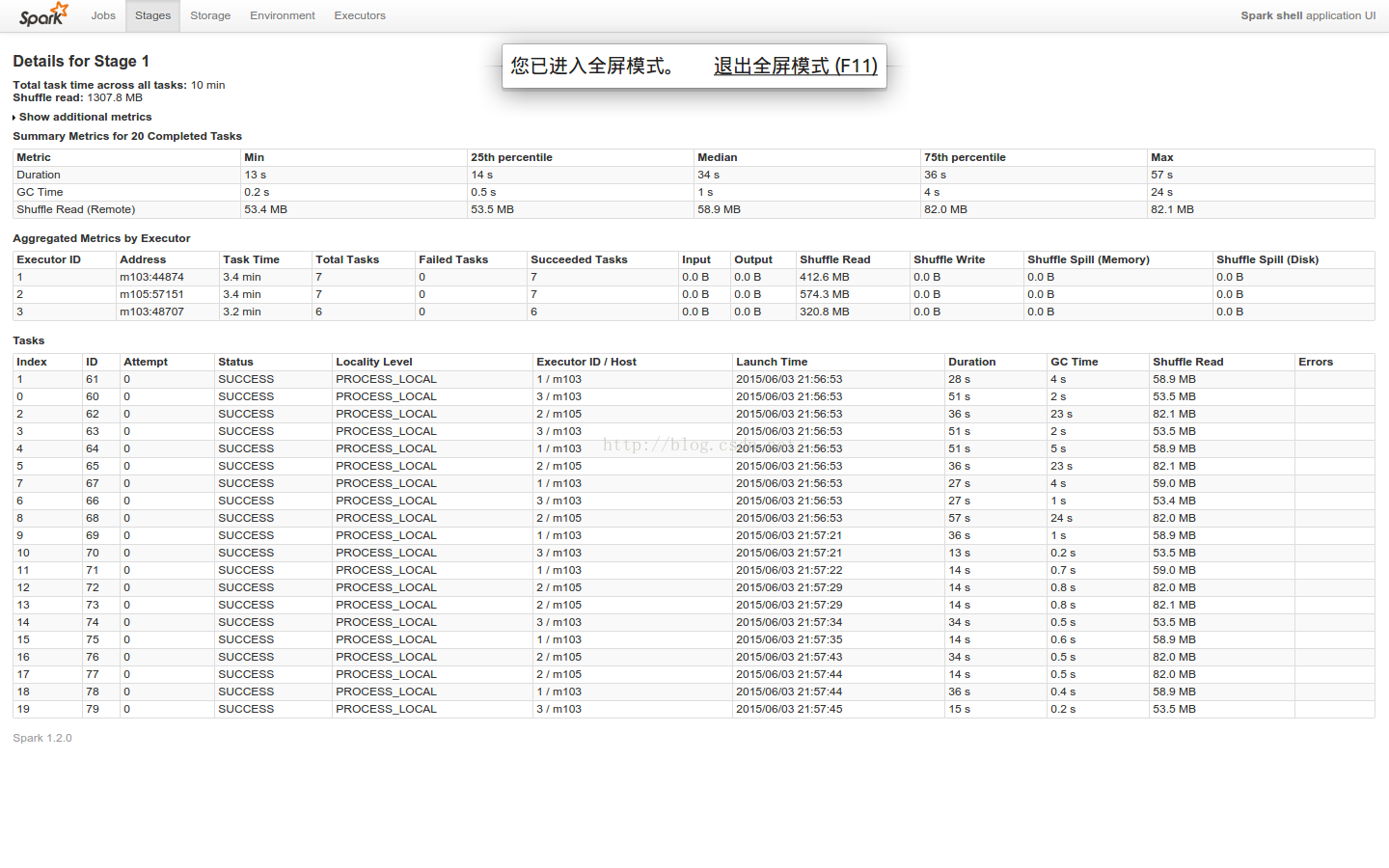
4.3 结论
1. G1比parallel的运行时间短了20%左右。
G1: 5.6min
Parallel: 7.2min
2. 且75%对比中,前者为5s,后者为15s
关于memoryFraction的调整:
由于groupby过程中没有必要对RDD进行cache,即不需要RDD常驻内存,所以我们可以把内存节省下来用于shuffle过程中的排序等操作中,可以通过memoryFraction来调整。我们分两次测试,以验证该参数的变化对groupby速度的影响。
关于partition的调整:
为了减少reduce数量,我们把partition从200改成了20。后面会对该修改进行验证测试。基本依据就是涉及到文件操作(shuffle),越大越好。
当使用sortshuffle时,Reduce数量的减少意味着可以在不降低并行度的情况下减少相关sort buffer的数量,进而有了更多的空间增大每个sort buffer,从而提高sort速度。对于reduce端,降低reduce数量,较少了频繁提交任务的开销,同时也会降低reader句柄的数量。
使用hash shuffle时,减少partition数量也没啥坏处
由于默认memoryFraction时,GC时间过长,我们把默认情况放在了后面,有时间就测测,唯一的目的也就是挑战一下极端内存的情况,当然了也熟悉一下shuffle过程中的其他参数设置。
5 memoryFraction测试
并调整file buffer大小为10MB
5.1 增大shuffle.memoryFraction
5.1.1 G1
spark-shell--num-executors 3 --executor-memory 12g --executor-cores 3 --driver-memory 2g--master yarn-client --conf spark.dynamicAllocation.enabled=false --confspark.shuffle.service.enabled=false --conf spark.shuffle.compress=true --confspark.shuffle.manager=sort --conf spark.sql.shuffle.partitions=20 --confspark.executor.extraJavaOptions="-XX:+UseG1GC -XX:+PrintFlagsFinal-XX:+PrintReferenceGC -verbose:gc -XX:+PrintGCDetails -XX:+PrintGCTimeStamps-XX:+PrintAdaptiveSizePolicy -XX:+UnlockDiagnosticVMOptions-XX:+G1SummarizeConcMark -XX:InitiatingHeapOccupancyPercent=45" --confspark.shuffle.file.buffer.kb=10240 --conf spark.storage.memoryFraction=0.2--conf spark.shuffle.memoryFraction=0.6
stage1 + staage2 3.4 + 2.2 min
GC时间,max=25s 75%=5s
Stage1
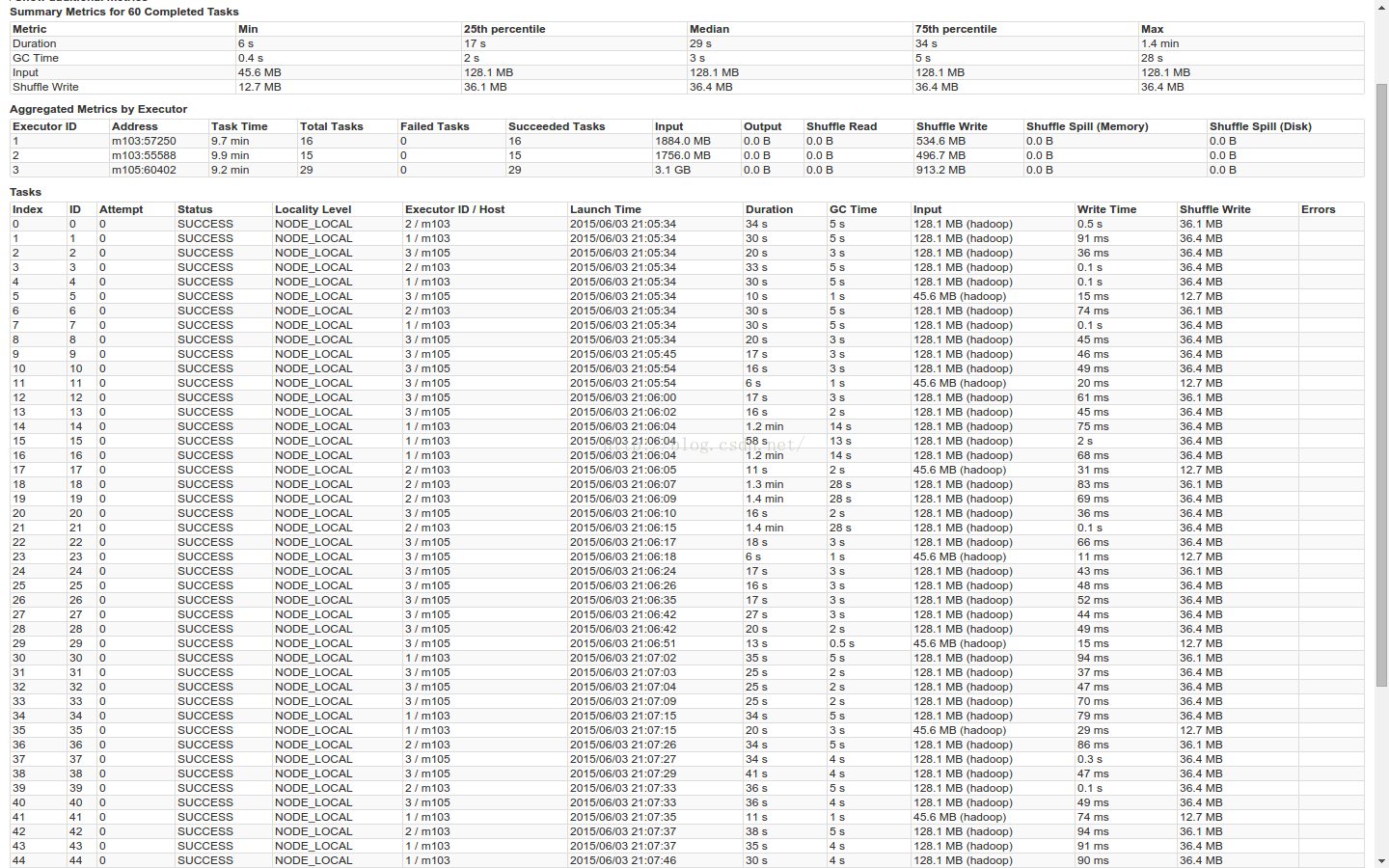
Stage2
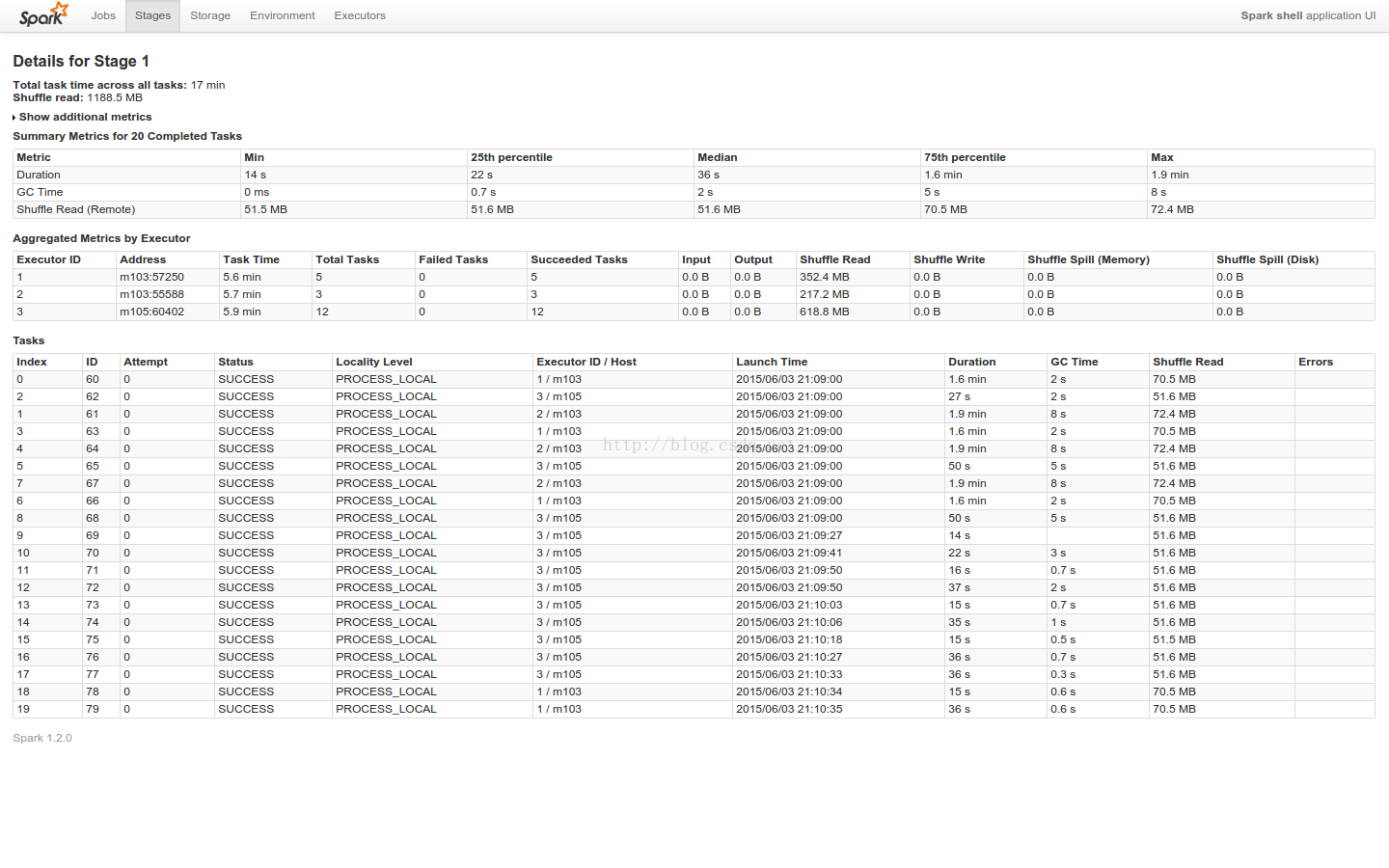
5.1.2 Paralle
spark-shell--num-executors 3 --executor-memory 12g --executor-cores 3 --driver-memory 2g--master yarn-client --conf spark.dynamicAllocation.enabled=false --confspark.shuffle.service.enabled=false --conf spark.shuffle.compress=true --confspark.shuffle.manager=sort --conf spark.sql.shuffle.partitions=20 --confspark.executor.extraJavaOptions="-XX:+UseParallelGC-Xmn8g -XX:+PrintFlagsFinal-XX:+PrintReferenceGC -verbose:gc -XX:+PrintGCDetails -XX:+PrintGCTimeStamps-XX:+PrintAdaptiveSizePolicy -XX:+UnlockDiagnosticVMOptions-XX:+G1SummarizeConcMark" --conf spark.shuffle.file.buffer.kb=10240 --confspark.storage.memoryFraction=0.2 --conf spark.shuffle.memoryFraction=0.6
注:Xmn为新生代大小,且最大值和初始值相等。
stage1 + staage2 5.7 + 1.5 min
GC时间 max=4.7min 75%=15s
stage1
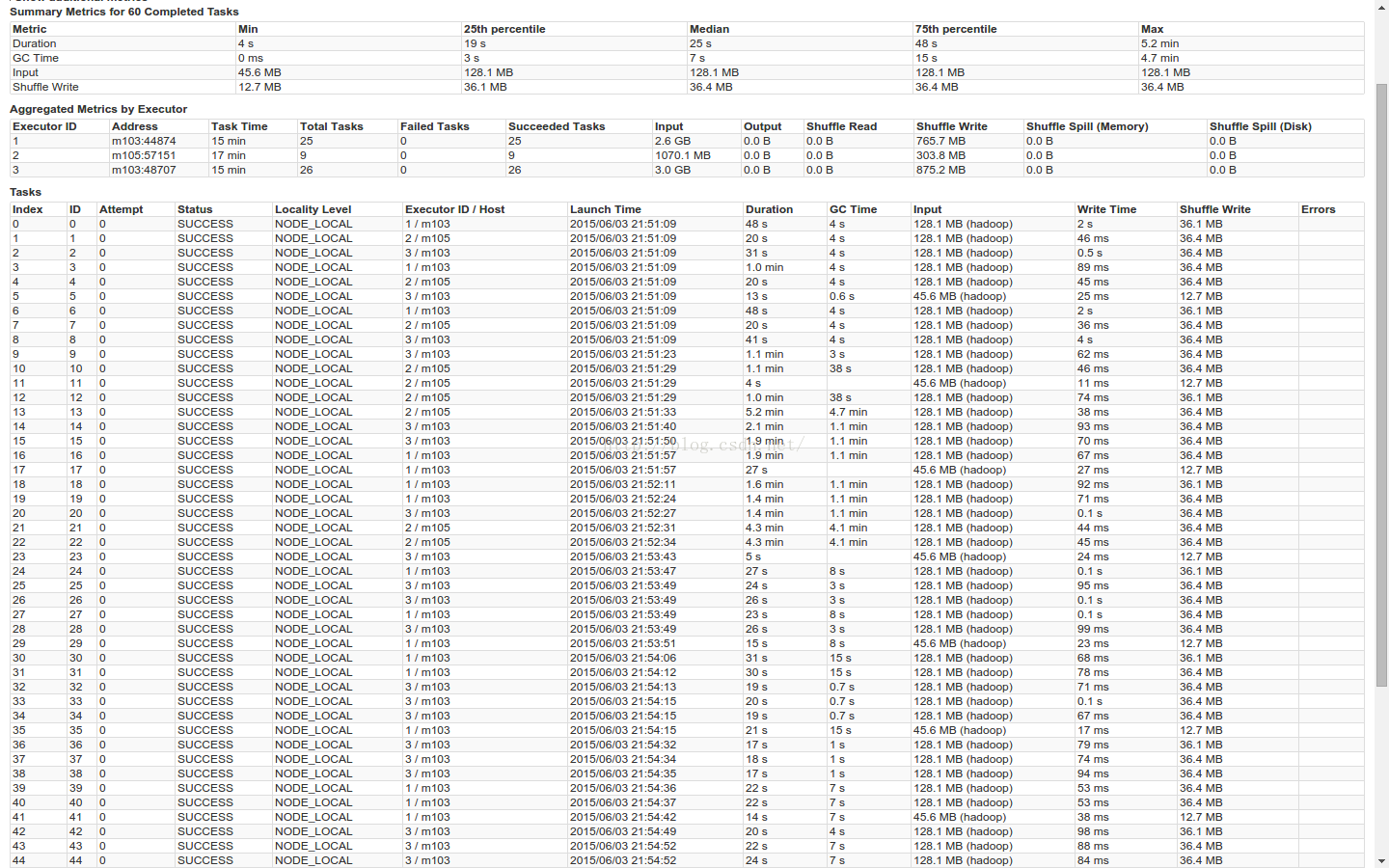
Stage2

5.2 memoryFraction保持默认
5.2.1 G1
spark-shell--num-executors 1 --executor-memory 32g --executor-cores 8 --driver-memory 2g--master yarn-client --conf spark.dynamicAllocation.enabled=false --confspark.shuffle.service.enabled=false --conf spark.shuffle.compress=true --confspark.shuffle.manager=sort --conf spark.sql.shuffle.partitions=20 --confspark.executor.extraJavaOptions="-XX:+UseG1GC -XX:+PrintFlagsFinal-XX:+PrintReferenceGC -verbose:gc -XX:+PrintGCDetails -XX:+PrintGCTimeStamps-XX:+PrintAdaptiveSizePolicy -XX:+UnlockDiagnosticVMOptions-XX:+G1SummarizeConcMark -XX:InitiatingHeapOccupancyPercent=45" --confspark.shuffle.file.buffer.kb=32 --conf spark.storage.memoryFraction=0.6 --confspark.shuffle.memoryFraction=0.2
第一批task运行时间大于10min,且出现超时现象。
stage1 + staage2 18 + 3.1 min
5.3 结论
变化详情:0.6(storage)-> 0.2 0.2(shuffle)->0.6
增大shuffle.memoryFraction之后,运行时间相当于默认情况的1/3。
6 partition数量测试
此处我们使用G1进行GC
spark-shell--num-executors 3 --executor-memory 12g --executor-cores 3 --driver-memory 2g--master yarn-client --conf spark.dynamicAllocation.enabled=false --confspark.shuffle.service.enabled=false --conf spark.shuffle.compress=true --confspark.shuffle.manager=sort --conf spark.sql.shuffle.partitions=NUM--conf spark.executor.extraJavaOptions="-XX:+UseG1GC -XX:+PrintFlagsFinal-XX:+PrintReferenceGC -verbose:gc -XX:+PrintGCDetails -XX:+PrintGCTimeStamps-XX:+PrintAdaptiveSizePolicy -XX:+UnlockDiagnosticVMOptions-XX:+G1SummarizeConcMark -XX:InitiatingHeapOccupancyPercent=45" --confspark.shuffle.file.buffer.kb=10240 --conf spark.storage.memoryFraction=0.2--conf spark.shuffle.memoryFraction=0.6
6.1 Partition = 200默认情况
stage1 + staage2 35 + 3.7 min
GC max=8.3min 75% = 15s
stage1

Stage2
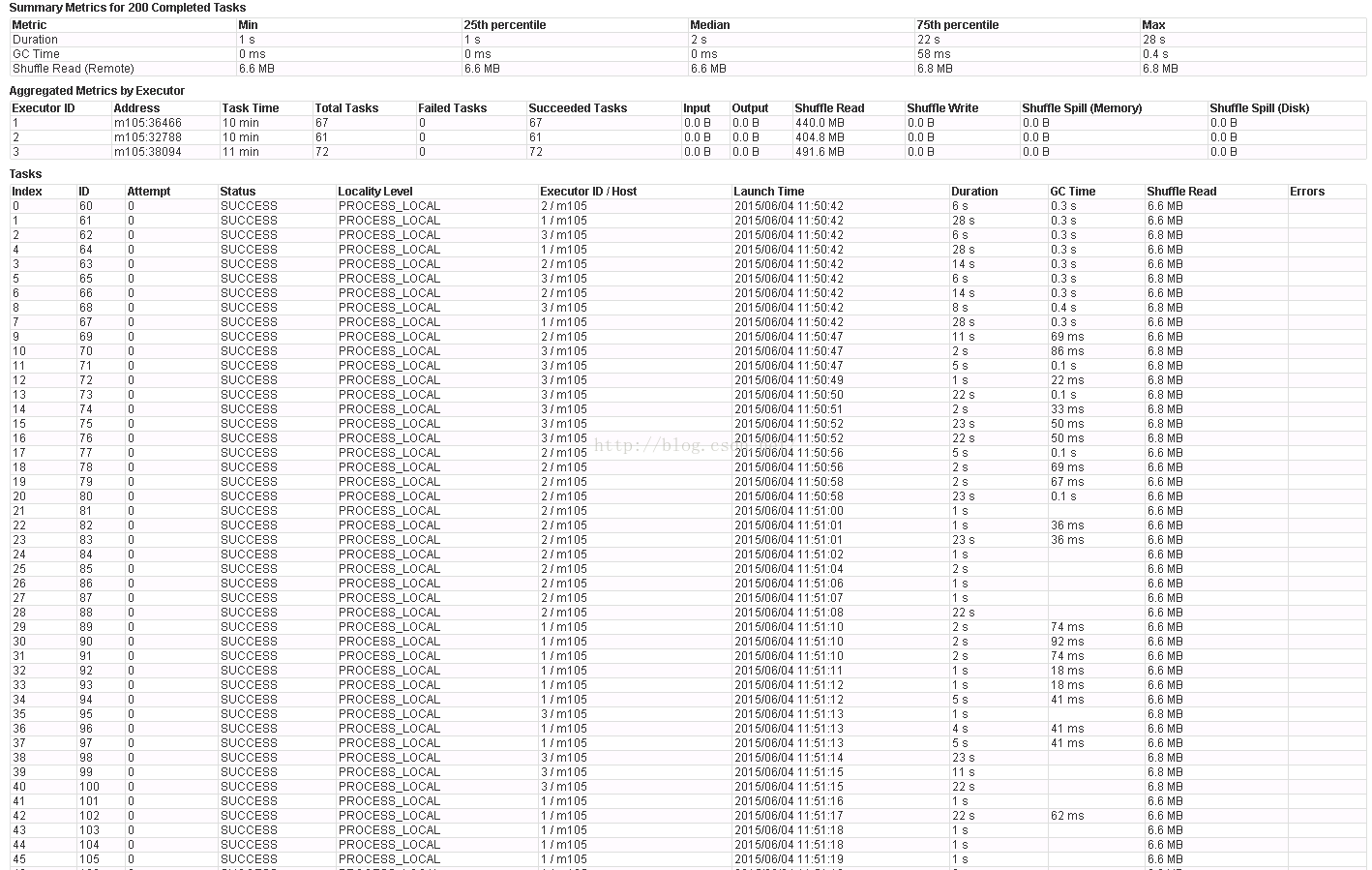
6.2 Partition = 20
(同4.1 GC测试-G1)
stage1 + staage2 3.4 + 2.2 min
GC时间,max=25s 75%=5s
6.3 结论
该partition为20时的运行时间相当于200时的1/8。