1.1 什么是过拟合
所谓过拟合(Overfit),是这样一种现象:一个假设在训练数据上能够获得比其他假设更好的拟合,但是在训练数据外的数据集 上却不能很好的拟合数据。此时我们就叫这个假设出现了overfit的现象。
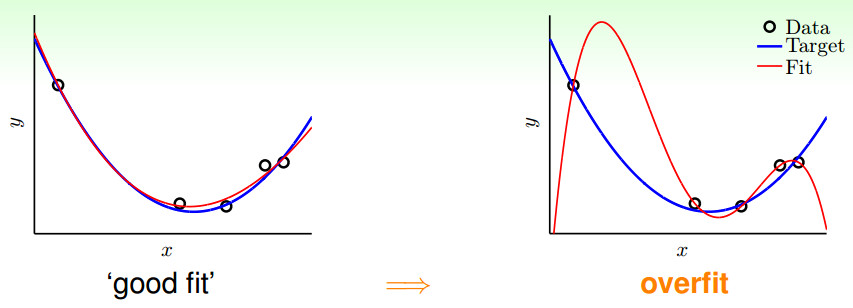
如上图所示:过拟合,就是拟合函数需要顾忌每一个点,最终形成的拟合函数波动很大。在某些很小的区间里,函数值的变化很剧烈。这就意味着函数在某些小区间里的导数值(绝对值)非常大,由于自变量值可大可小,所以只有系数足够大,才能保证导数值很大。
1.2 造成过拟合的原因
1.过拟合其中一个可能的成因就是模型的vc维过高,使用了过强的模型复杂度(model complexity)的能力。(参数多并且过训练)
2.还有一个原因是数据中的噪声,造成了如果完全拟合的话,也许与真实情景的偏差更大。
3.最后还有一个原因是数据量有限,这使得模型无法真正了解整个数据的真实分布。
4.权值学习迭代次数足够多(Overtraining),拟合了训练数据中的噪声和训练样例中没有代表性的特征。
1.3 过拟合解决方法
1.权值衰减
在每次迭代过程中以某个小因子降低每个权值,这等效于修改E的定义,加入一个与网络权值的总量相应的惩罚项,此方法的动机是保持权值较小,避免weight decay,从而使学习过程向着复杂决策面的反方向偏。(L2正则化)
2.Cross-validation with some patterns
交叉验证方法在可获得额外的数据提供验证集合时工作得很好,但是小训练集合的过度拟合问题更为严重
k-fold交叉方法:
把训练样例分成k份,然后进行k次交叉验证过程,每次使用不同的一份作为验证集合,其余k-1份合并作为训练集合.每个样例会在一次实验中被用作验证样例,在k-1次实验中被用作训练样例;每次实验中,使用上面讨论的交叉验证过程来决定在验证集合上取得最佳性能的迭代次数n*,然后计算这些迭代次数的均值,作为最终需要的迭代次数。
3.正则化