Kim Y’s Paper
模型结构及原理
模型的结构如下:
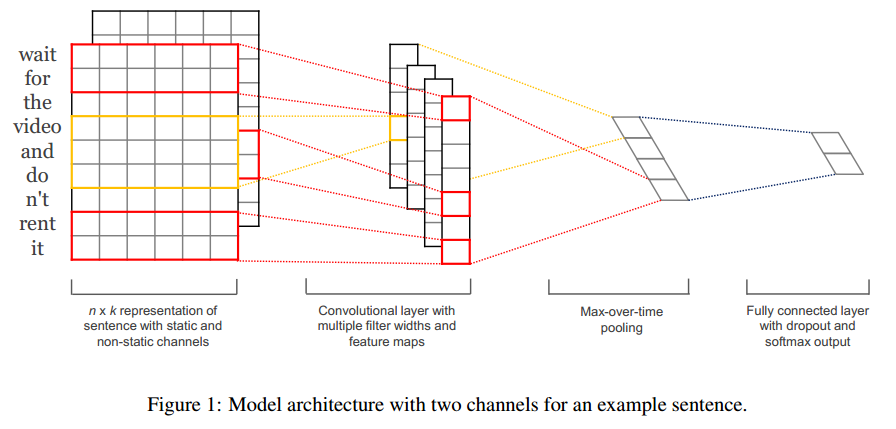
- 输入层
如图所示,输入层是句子中的词语对应的word vector依次(从上到下)排列的矩阵,假设句子有 n 个词,vector的维数为 k ,那么这个矩阵就是 n×k 的。
这个矩阵的类型可以是静态的(static),也可以是动态的(non static)。静态就是word vector是固定不变的,而动态则是在模型训练过程中,word vector也当做是可优化的参数,通常把反向误差传播导致word vector中值发生变化的这一过程称为Fine tune。
对于未登录词的vector,可以用0或者随机小的正数来填充。
- 第一层卷积层
输入层通过卷积操作得到若干个Feature Map,卷积窗口的大小为 h×k ,其中 h 表示纵向词语的个数,而 k 表示word vector的维数。通过这样一个大型的卷积窗口,将得到若干个列数为1的Feature Map。
- 池化层
接下来的池化层,文中用了一种称为Max-over-time Pooling的方法。这种方法就是简单地从之前一维的Feature Map中提出最大的值,文中解释最大值代表着最重要的信号。可以看出,这种Pooling方式可以解决可变长度的句子输入问题(因为不管Feature Map中有多少个值,只需要提取其中的最大值)。
最终池化层的输出为各个Feature Map的最大值们,即一个一维的向量。
- 全连接 + Softmax层
池化层的一维向量的输出通过全连接的方式,连接一个Softmax层,Softmax层可根据任务的需要设置(通常反映着最终类别上的概率分布)。
最终实现时,我们可以在倒数第二层的全连接部分上使用Dropout技术,即对全连接层上的权值参数给予L2正则化的限制。这样做的好处是防止隐藏层单元自适应(或者对称),从而减轻过拟合的程度。
4.实验部分
1. 数据
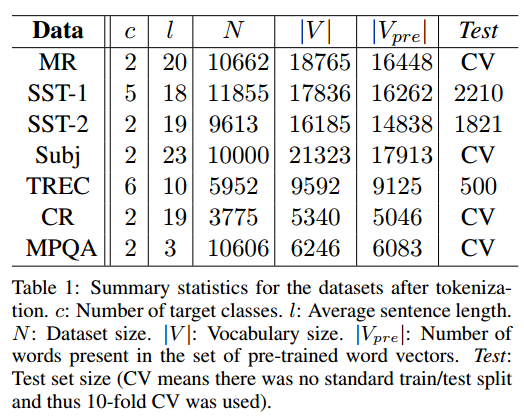
实验用到的数据集如下(具体的名称和来源可以参考论文):
2.模型训练和调参
- 修正线性单元(Rectified linear units)
- 滤波器的h大小:3,4,5;对应的Feature Map的数量为100;
- Dropout率为0.5,L2正则化限制权值大小不超过3;
- mini-batch的大小为50;
这些参数的选择都是基于SST-2 dev数据集,通过网格搜索方法(Grid Search)得到的最优参数。另外,训练过程中采用随机梯度下降方法,基于shuffled mini-batches之上的,使用了Adadelta update rule(Zeiler, 2012)。
3.预训练的Word Vector
这里的word vector使用的是公开的数据,即连续词袋模型(COW)在Google News上的训练结果。未登录次的vector值是随机初始化的。
4.实验结果
实验结果如下图:
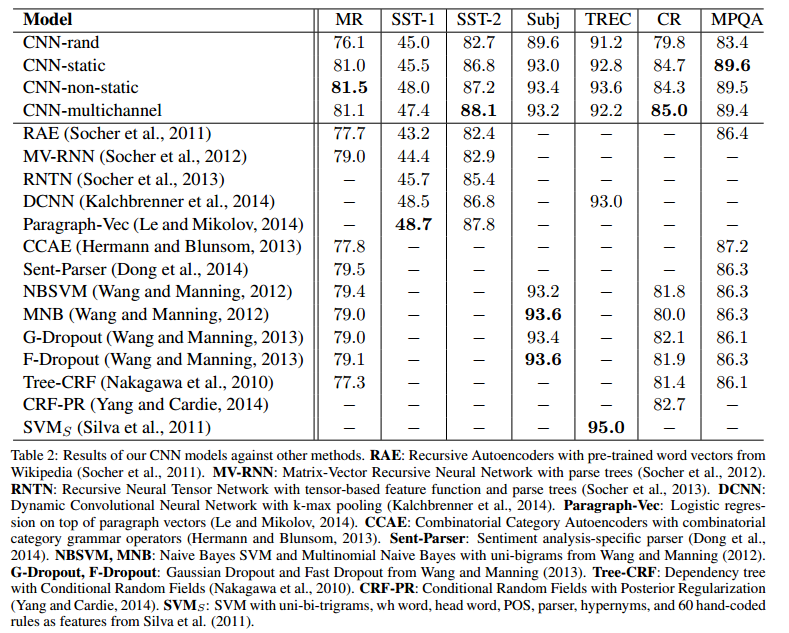
其中,前四个模型是上文中所提出的基本模型的各个变种:
- CNN-rand: 所有的word vector都是随机初始化的,同时当做训练过程中优化的参数;
- CNN-static: 所有的word vector直接使用无监督学习即Google的Word2Vector工具(COW模型)得到的结果,并且是固定不变的;
- CNN-non-static: 所有的word vector直接使用无监督学习即Google的Word2Vector工具(COW模型)得到的结果,但是会在训练过程中被
Fine tuned; - CNN-multichannel: CNN-static和CNN-non-static的混合版本,即两种类型的输入;
博主自己下载了论文作者的实现程序(Github地址),最终在MR数据集上的运行结果如下:
- CNN-rand: 0.7669
- CNN-static: 0.8076
- CNN-non-static: 0.8151
和论文中的结果差不多。
5. 结论
CNN-static较与CNN-rand好,说明pre-training的word vector确实有较大的提升作用(这也难怪,因为pre-training的word vector显然利用了更大规模的文本数据信息);CNN-non-static较于CNN-static大部分要好,说明适当的Fine tune也是有利的,是因为使得vectors更加贴近于具体的任务;CNN-multichannel较于CNN-single在小规模的数据集上有更好的表现,实际上CNN-multichannel体现了一种折中思想,即既不希望Fine tuned的vector距离原始值太远,但同时保留其一定的变化空间。
值得注意的是,static的vector和non-static的相比,有一些有意思的现象如下表格:
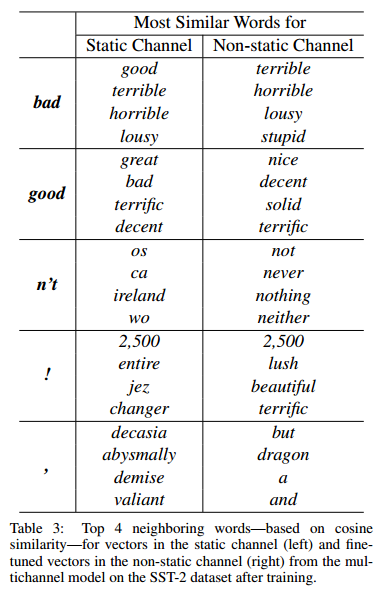
- 原始的word2vector训练结果中,
bad对应的最相近词为good,原因是这两个词在句法上的使用是极其类似的(可以简单替换,不会出现语句毛病);而在non-static的版本中,bad对应的最相近词为terrible,这是因为在Fune tune的过程中,vector的值发生改变从而更加贴切数据集(是一个情感分类的数据集),所以在情感表达的角度这两个词会更加接近; - 句子中的
!最接近一些表达形式较为激进的词汇,如lush等;而,则接近于一些连接词,这和我们的主观感受也是相符的。
Kim Y的这个模型很简单,但是却有着很好的性能。后续Denny用TensorFlow实现了这个模型的简单版本,可参考这篇博文;以及Ye Zhang等人对这个模型进行了大量的实验,并给出了调参的建议,可参考这篇论文。
下面总结一下Ye Zhang等人基于Kim Y的模型做了大量的调参实验之后的结论:
- 由于模型训练过程中的随机性因素,如随机初始化的权重参数,mini-batch,随机梯度下降优化算法等,造成模型在数据集上的结果有一定的浮动,如准确率(accuracy)能达到1.5%的浮动,而AUC则有3.4%的浮动;
- 词向量是使用word2vec还是GloVe,对实验结果有一定的影响,具体哪个更好依赖于任务本身;
- Filter的大小对模型性能有较大的影响,并且Filter的参数应该是可以更新的;
- Feature Map的数量也有一定影响,但是需要兼顾模型的训练效率;
- 1-max pooling的方式已经足够好了,相比于其他的pooling方式而言;
- 正则化的作用微乎其微。
Ye Zhang等人给予模型调参者的建议如下:
- 使用
non-static版本的word2vec或者GloVe要比单纯的one-hot representation取得的效果好得多; - 为了找到最优的过滤器(Filter)大小,可以使用线性搜索的方法。通常过滤器的大小范围在
1-10之间,当然对于长句,使用更大的过滤器也是有必要的; Feature Map的数量在100-600之间;- 可以尽量多尝试激活函数,实验发现
ReLU和tanh两种激活函数表现较佳; - 使用简单的
1-max pooling就已经足够了,可以没必要设置太复杂的pooling方式; - 当发现增加
Feature Map的数量使得模型的性能下降时,可以考虑增大正则的力度,如调高dropout的概率; - 为了检验模型的性能水平,多次反复的交叉验证是必要的,这可以确保模型的高性能并不是偶然。