
python通过urllib.request.urlopen("https://www.baidu.com")访问网页


实战,去网站上下载一只猫的图片
import urllib.request response = urllib.request.urlopen('http://placekitten.com/g/500/600') cat_img = response.read() with open('cat_500_600', 'wb') as f: f.write(cat_img)
或者:
import urllib.request req = urllib.request.Request('http://placekitten.com/g/500/600') response = urllib.request.urlopen(req) cat_img = response.read() with open('cat_500_600', 'wb') as f: f.write(cat_img)
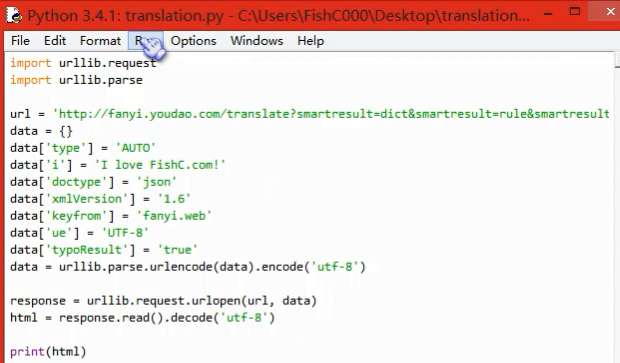
爬虫百度翻译和有道翻译
直接方法(它们都有反爬虫,所以失败了),f12,可以获得url和from data获得data字典
url='https://fanyi.baidu.com/v2transapi' data={} data['from']='en' data['to']='zh' data['query']='I love typing code' data['transtype']='translang' data['simple_means_flag']='3' data['sign']='94582.365127' data['token']='ad3ea2606fa89004bad50bbd15aa045b' data = urllib.parse.urlencode(data).encode('utf-8') response = urllib.request.urlopen(url, data) html = response.read().decode('utf-8') print(html)
通过网上的大神解决了的代码
import urllib.request import urllib.parse import json content = input('请输入要翻译的句子: ') youdao_url = 'http://fanyi.youdao.com/translate?smartresult=dict&smartresult=rule' baidu_url = 'http://fanyi.baidu.com/basetrans' data = {} data2 = {} data['i']= content data['from'] = 'AUTO' data['to'] = 'AUTO' data['smartresult'] = 'dict' data['client'] = 'fanyideskweb' data['salt'] = '1525141473246' data['sign'] = '47ee728a4465ef98ac06510bf67f3023' data['doctype'] = 'json' data['version'] = '2.1' data['keyfrom'] = 'fanyi.web' data['action'] = 'FY_BY_CLICKBUTTION' data['typoResult'] = 'false' data = urllib.parse.urlencode(data).encode('utf-8') data2['from'] = 'zh' data2['to'] = 'en' data2['query'] = content data2['transtype'] = 'translang' data2['simple_means_flag'] = '3' data2['sign'] = '94582.365127' data2['token'] = 'ec980ef090b173ebdff2eea5ffd9a778' data2 = urllib.parse.urlencode(data2).encode('utf-8') headers = {"User-Agent":"Mozilla/5.0 (Linux; Android 5.1.1; Nexus 6 Build/LYZ28E) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.84 Mobile Safari/537.36"} youdao_response = urllib.request.urlopen(youdao_url, data) baidu_re = urllib.request.Request(baidu_url, data2, headers) baidu_response = urllib.request.urlopen(baidu_re) youdao_html = youdao_response.read().decode('utf-8') baidu_html = baidu_response.read().decode('utf-8') target = json.loads(youdao_html) target2 = json.loads(baidu_html) print('【有道】翻译为: %s'%(target['translateResult'][0][0]['tgt'])) print('【百度】翻译为: %s'%(target2['trans'][0]['dst']))