本作业博客链接[https://edu.cnblogs.com/campus/fzu/Grade2016SE/homework/2138]
队友博客链接[http://www.cnblogs.com/fleur1025/p/9767647.html]
github链接[https://github.com/Fleurrr/pair-project/tree/master/Cplusplus]
1.具体的分工
-
蔡文斌:完成爬取论文信息和附加题部分(尽量)
-
所使用的语言:C++,python -
预计完成时间:9.30号之前
-
-
黄泽:完成词频统计和单元测试
-
所使用的语言:C++ -
预计完成的时间:10.7号之前
-
-
剩余时间两人合力完成博客以及对代码的测试和完善
2.【PSP】
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
| Planning | 计划 | 90 | 120 |
| •Estimate | •估计这个任务需要多少时间 | 500 | 730 |
| Development | 开发 | 40 | 30 |
| •Analysis | •需求分析 (包括学习新技术) | 150 | 200 |
| •Design Spec | •生成设计文档 | 30 | 20 |
| •Design Review | •设计复审 | 20 | 15 |
| •Coding Standard | •代码规范(为目前的开发制定合适的规范) | 10 | 20 |
| •Design | •具体设计 | 10 | 20 |
| •Coding | •具体编码 | 150 | 300 |
| •Code Review | •代码复审 | 30 | 30 |
| •Test | •测试(自我测试,修改代码,提交修改) | 20 | 20 |
| Reporting | 报告 | 30 | 20 |
| •Test Repor | •测试报告 | 20 | 15 |
| •Size Measurement | •计算工作量 | 40 | 20 |
| •Postmortem & Process Improvement Plan | •事后总结, 并提出过程改进计划 | 30 | 20 |
| 合计 | 580 | 730 |
3. 解题思路描述与设计实现说明
3.1爬虫使用部分
-
方法一:使用python语言。
使用python语言来写爬虫的话,首先想到的可能都是分析网站的HTML代码,然后根据正则表达式去匹配相应的标签进行爬取。但是正则表达式的话使用起来不方便,需要记忆多条规则,用起来不是很熟练,刚开始用python写的时候就是用这种方法,吃了不少苦头。后来发现python中的beautifulsoup是一个强大的爬虫利器,所以就该用beautifulsoup来写这个爬虫。
这里附上一个关于beautifulsoup详细介绍的博客网址https://www.cnblogs.com/zhaof/p/6930955.html -
方法二:使用c++语言
在用python爬完之后,想到用听说用java或者c++写有加分,谁不会心动啊是不是,于是抱着尝试一把的心态用c++写了一下。用c++写的话主要就是利用socket模块,主要的思路如下:
1.先把连接服务器的结构搭建好(作为客户端)
2.向服务器发送获取资源命令
3.接收数据并过滤不需要的信息
4.写入指定文件
3.2代码组织与内部实现设计(类图)
3.2.1类图:

3.2.2详细说明:
- 单词/词组结构体cube,包含属性:单词/词组内容,长度,词频
struct cube{char wordtype[1000],int lenth,int frequency=0}
- tools类 用于存储读入的字符串,以及各类函数
class tools{
public:tools(string liner){line = liner;}
int wordcounter(int &kind,cube type[],int &weight,int &group);
int linecounter();
int charcounter();
void wordprinter(int &kind,cube type[],int print[],int pront[],int &number);
private:
string line;
};
- tools:: wordcounter(int &kind,cube type[],int &weight,int &group)
单词统计器,并将词频和单词/词组内容赋给cube单词/词组结构体 - tools::linecounter( ) 行数统计器,返回行数值
- tools::charcounter( ) 字符统计器,返回字符值
- tools::wordprinter(int &kind,cube type[],int print[],int pront[],int &number) 单词/词组输出器
- int main(int argc, char*argv[]) main函数,用于实现控制台自定义输入输出,以及文本读入输出
3.3说明算法的关键与关键实现部分流程图
这次作业相较于上一次个人项目二,需要我们新增控制台输入输出功能、权重选择功能、控制单词词组输出个数功能、词组功能。前三项功能实现较为简单,这里展示本次代码的关键部分——单词判断与词组判断的流程图。
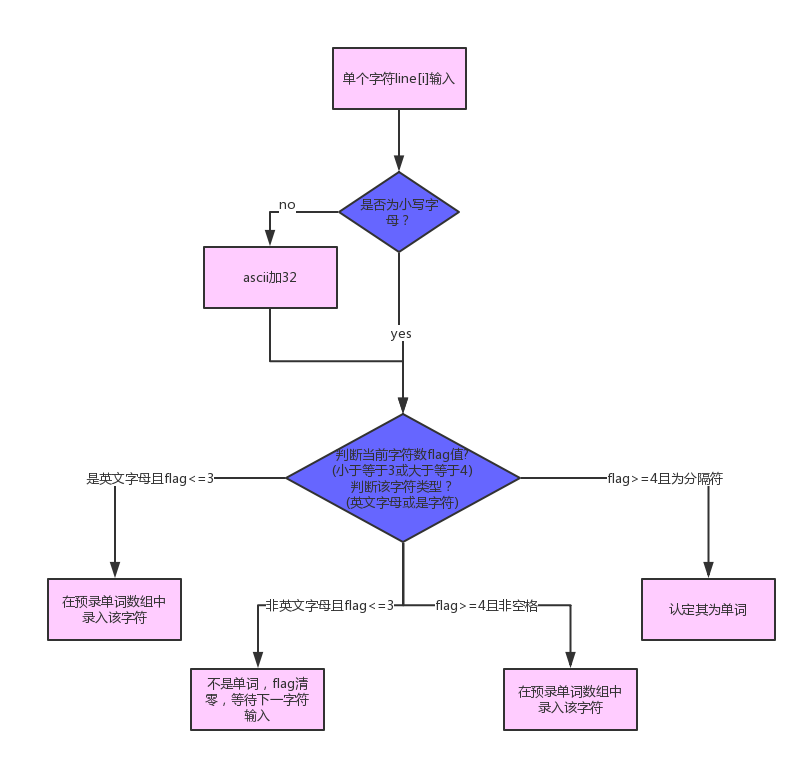
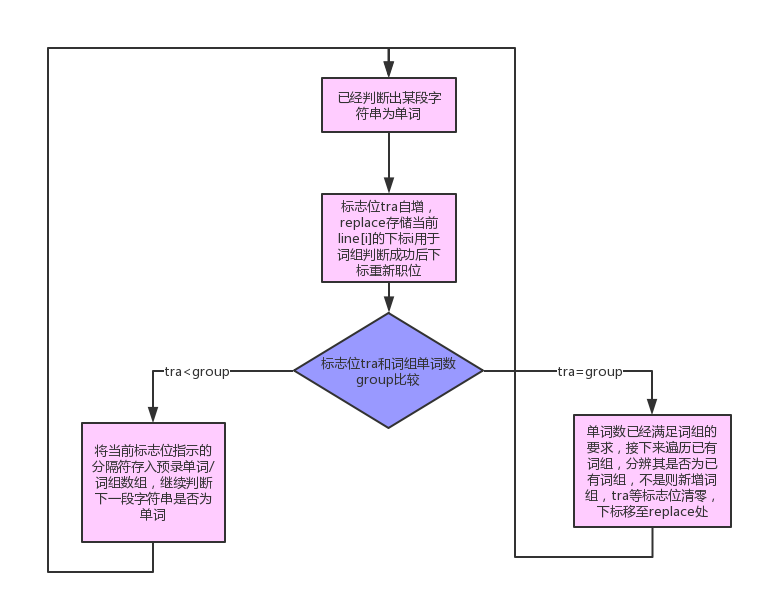
4.附加题设计与展示
- (1)爬取论文的作者,思路跟爬取论文摘要一样,也是利用beautifulsoup进行爬取。附上代码
import requests
from urllib.request import urlopen
from bs4 import BeautifulSoup
txt = open (r'D:/result_1.txt','w',encoding = 'utf-8')
#i = 0
def getPaper (newsUrl):
global ws
res = requests.get(newsUrl)
res.encoding = 'utf-8'
soup = BeautifulSoup(res.text,'html.parser')
Authors = soup.select('i')[0].text.strip()
print(Authors,file = txt)
return
sUrl = 'http://openaccess.thecvf.com/CVPR2018.py'
resl = requests.get(sUrl)
resl.encoding = 'utf-8'
soupl = BeautifulSoup(resl.text,'html.parser')
for titles in soupl.select('.ptitle'):
t = 'http://openaccess.thecvf.com/' + titles.select('a')[0]['href']
#print(i,file = txt)
getPaper(t)
#i = i + 1
成果展示

- (2)用python写词云,我是随便截取了一段摘要作为文档来形成词云,利用python的Wordcloud和jieba这两个功能进行指定文档生成以指定图片为背景形状的词云。附上代码。
from os import path
from PIL import Image
import numpy as np
import matplotlib.pyplot as plt
import jieba
from wordcloud import WordCloud, STOPWORDS,ImageColorGenerator
###当前文件路径
d = path.dirname(__file__)
file = open(path.join(d, "D:/test.txt")).read()
##进行分词
#刚开始是分完词放进txt再打开却总是显示不出中文很奇怪
default_mode =jieba.cut(file)
text = " ".join(default_mode)
# 图片
alice_mask = np.array(Image.open(path.join(d, "D:/qq.jpg")))
stopwords = set(STOPWORDS)
stopwords.add("said")
fontname = path.join(d, 'C:/Windows/Fonts/SimSun-ExtB.ttf')
wc = WordCloud(
#设置字体,不指定就会出现乱码,这个字体文件需要下载
#font_path = fontname,
background_color="white",
max_words=2000,
mask=alice_mask,
stopwords=stopwords)
wc.generate(text)
image_colors = ImageColorGenerator(alice_mask)
# store to file
wc.to_file(path.join(d, "D:/qq_result.jpg"))
# show
plt.imshow(wc, interpolation='bilinear')
plt.axis("off")
plt.figure()
成果展示

- (3) 对数据进行简单的可视化处理,形成作者的人物关系图。
这时候就要强烈安利一下python的pyecharts模块了,这是一个基于python的数据可视化工具,可以绘制很多种可视化图像。
分享一篇关于pyecharts文章:https://wenku.baidu.com/view/efb3dfbe29ea81c758f5f61fb7360b4c2e3f2af3.html
附上代码:https://pan.baidu.com/s/1zrHBitAmA-0MWI_3vLG8tw
成果展示:
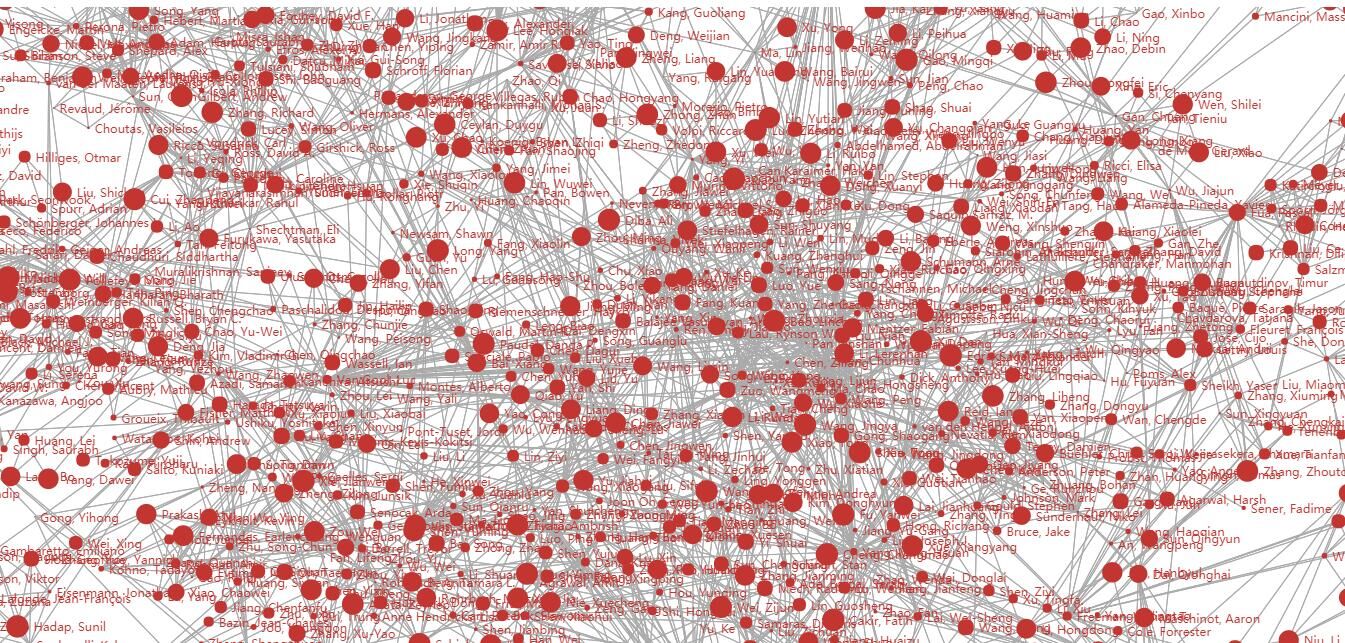
5.关键代码解释
5.1爬虫部分的关键代码(只解释C++的做法)
void GetHttpRespons(char * &response, string source)
{
//使用GET请求,得到相应
string host, resource;
host = "openaccess.thecvf.com";
resource = source;
struct hostent * hp = gethostbyname(host.c_str());
if (hp == NULL)
{
cout << "can not find host address"<<endl;
exit(0);
}
//建立socket
SOCKET sock = socket(AF_INET, SOCK_STREAM, IPPROTO_TCP);
if (sock == -1 || sock == -2) {
cout << "Can not create sock." << endl;
exit(0);
}
//建立服务器地址
SOCKADDR_IN sa;
sa.sin_family = AF_INET;
sa.sin_port = htons(80);
memcpy(&sa.sin_addr, hp->h_addr, 4);
//建立连接
if (0 != connect(sock, (SOCKADDR*)&sa, sizeof(sa))) {
cout << "can not connet" << endl;
closesocket(sock);
exit(0);
}
//connect(sock, (SOCKADDR*)&sa, sizeof(sa));
//准备发送数据
string request = "GET " + resource + " HTTP/1.1
Host:" + host + "
Connection:Close
";
//发送数据
send(sock, request.c_str(), request.size(), 0);
if (SOCKET_ERROR == send(sock, request.c_str(), request.size(), 0)) {
cout << "send error" << endl;
closesocket(sock);
exit(0);
}
//接收数据
int m_nContentLength = DEFAULT_PAGE_BUF_SIZE;
int bytesRead = 0;
int ret = 1;
char *pageBuf = (char *)malloc(m_nContentLength);
memset(pageBuf, 0, m_nContentLength);
//分配内存
while (ret > 0)
{
ret = recv(sock, pageBuf + bytesRead, m_nContentLength - bytesRead, 0);
if (ret > 0)
{
bytesRead += ret;
}
if (m_nContentLength - bytesRead < 100)
{
m_nContentLength *= 2;
pageBuf = (char*)realloc(pageBuf, m_nContentLength);
}
}
pageBuf[bytesRead] = '�';
response = pageBuf;
closesocket(sock);
}
该函数是用来与服务器进行连接的,主要用到的是c++的socket模块。
(1)创建套接字socket()
(2)用gethostbyname()函数解析主机名
(3)用connect()函数进行与服务器进行连接
(4)用send()函数发送数据
(5)最后接收数据,关闭套接字closesocket()
5.2词频统计部分(只对部分关键代码进行说明)
1.实现控制台输入输出部分
for (i = 1; i < argc; i++)//用于控制台输入
{
if (strcmp(argv[i], "-i") == 0)
{
i++;
fileinname = argv[i];
}//自定义输入,-i后接输入文本名,文本名赋给fileinname
if (strcmp(argv[i], "-m") == 0)
{
i++;
group = argv[i][0] - 48;//字符类型转数字类型
}//-m后接自定义词组长
if (strcmp(argv[i], "-n") == 0)
{
i++;
number = 0;
int sum;
for (q = 0; q < strlen(argv[i]); q++)
{
sum = argv[i][q] - 48;
for (p = 1; p <= strlen(argv[i]) - q - 1; p++)
{
sum = sum * 10;
}
number = number + sum;
}
} //自定义输出单词数
if (strcmp(argv[i], "-w") == 0)
{
i++;
if (argv[i][0] - 48 == 1)
{
weight = 1;
}
if (argv[i][0] - 48 == 0)
{
weight = 0;
}
}//权重定义
if (strcmp(argv[i], "-o") == 0)
{
i++;
fileoutname = argv[i];
;
}//自定义输出,-o后接输出文本名 ,赋值给fileoutname
}
2.实现单词词组权值判别存储功能(示例为title行内)
if (lines % 5 == 2)//识别为title行内
{
if (weight == 1)
{
add = 10;
}//在title行内,如果设置权重即weight=1,则自增值改为10
line[line.size()] = ' ';//因为判定单词方式的关系,增加一个空格至该行最后
for (i = 7; i <= line.size(); i++)//跳过“title: ” 从下标7开始
{
ptr = 0;
if (line[i] >= 'A'&&line[i] <= 'Z')
{
line[i] = line[i] + 32;//大写转小写
}
if (line[i] >= 'a'&&line[i] <= 'z'&&flag <= 3)
{
testword[flagalter + flag] = line[i];
flag++;
ptr = 1;//如果在前四个字符中未出现非字符,将字符存入当前待定词组testword中
}
if ((line[i]<'a' || line[i]>'z') && flag <= 3)
{
flag = 0;
flagalter = 0;
tra = 0;//如果在前四个字符中出现非字符,所有标志位置为零
}
if (flag >= 4 && (line[i] >= '0'&&line[i] <= '9' || line[i] >= 'a'&&line[i] <= 'z') && ptr == 0)
{
testword[flagalter + flag] = line[i];//如果前四个字符已经是字母,后续只要不是分隔符都录入testword
flag++;
}
if (flag >= 4 && (line[i]<'0' || line[i]>'9'&&line[i]<'a' || line[i]>'z') && ptr == 0)//前四个字符已经是字母,后续出现分隔符 ,判定为单词
{
words++; //单词数自增
tra++;
if (tra == 1 && tra != group)
{
replace = i;//用于后期下标重新置位
words=words-group+1;
}
if (tra < group)//已经判断有tra个单词组成词组,如果 tra小于要求的词组单词数,将分隔符录入,各标志位更改,准备录入下一个单词
{
testword[flagalter + flag] = line[i];
flag++;
flagalter = flag + flagalter;
flag = 0;
}
if (tra == group)//如果词组单词数已经满足,与之前已有比较词组是否已经存在该词组
{
flag = flagalter + flag;
for (p = 1; p <= kind; p++)
{
for (j = 0; j < flag; j++)
{
if (testword[j] != type[p].wordtype[j])
{
p++;
j = 0;
break;
}
if (j == flag - 1)//若为已有词组,该词组结构体中的词频增加
{
type[p].frequency = type[p].frequency + add;
p = kind;
temp = 1;
break;
}
}
}
if (temp == 0)//若为新词组,进行添加
{
kind++;
for (k = 0; k < flag; k++)
{
type[kind].wordtype[k] = testword[k];
}
type[kind].lenth = flag;
type[kind].frequency = type[kind].frequency + add;
}
if (group != 1)//下标重新置位
{
i = replace;
}
tra = 0;
flag = 0;
temp = 0;
flagalter = 0;
}
}
}
}
6.性能分析与改进
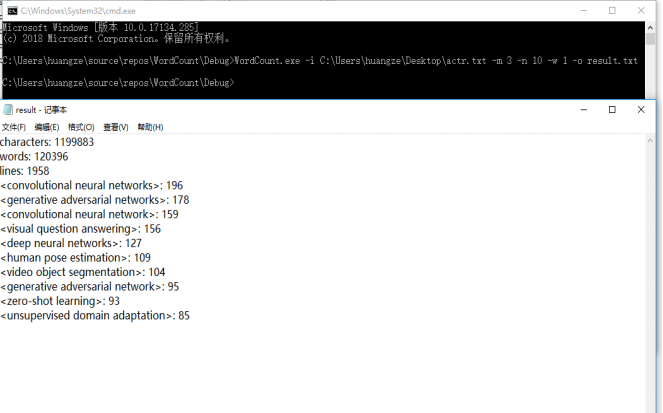
测试样本使用的是我们用爬虫工具爬取下来的论文,选用词组长为3,权重值为1,输出个数为10,输出至result.txt进行测试,命令行输入及测试结果如下图所示
性能分析图如下:
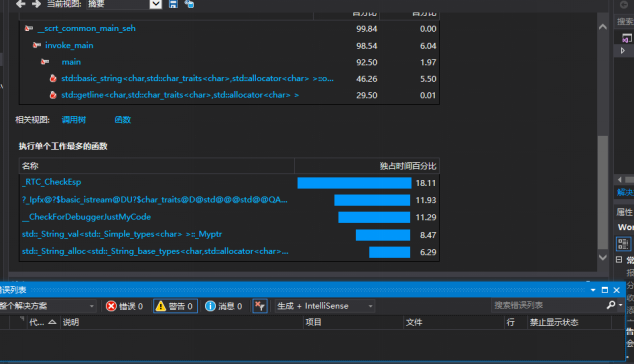
我在本来消耗时间的"判断是否为已有单词"的部分之前加了一个判断,可以使时间缩短
for (p = 1; p <= kind; p++)
{
if (flag != type[p].lenth)
{
continue;
}
for (j = 0; j < flag; j++)
{
if (testword[j] != type[p].wordtype[j])
{
p++;
j = 0;
break;
}
if (j == flag - 1)
{
type[p].frequency = type[p].frequency + add;
p = kind;
temp = 1;
break;
}
}
}
更换了优先度最大词组判断方式,时间复杂度为m*o(n),m为需要输出的个数
for (j = 1; j <= kind; j++)
{
if (type[j].frequency == max)
{
for (k = 0; k < min(type[j].lenth, len); k++)
{
if (type[j].wordtype[k] < type[tra].wordtype[k])
{
tra = j;
len = type[j].lenth;
break;
}
if (type[j].wordtype[k] > type[tra].wordtype[k])
{
break;
}
if (k == min(type[j].lenth, len) - 1)
{
if (type[j].lenth < len)
{
tra = j;
len = type[j].lenth;
}
}
}
}
if (type[j].frequency > max)
{
max = type[j].frequency;
tra = j;
}
}
print[i] = type[tra].frequency;
pront[i] = tra;
type[tra].frequency = 0;
len = 100000;
max = 0;
其余的暂时没有想到更好的办法
7.单元测试(这里只展示部分有代表性的输出文件)
- 打开错误的文件
- 当文件为空时
- Abstract或Title为空
- 缺少-i指令
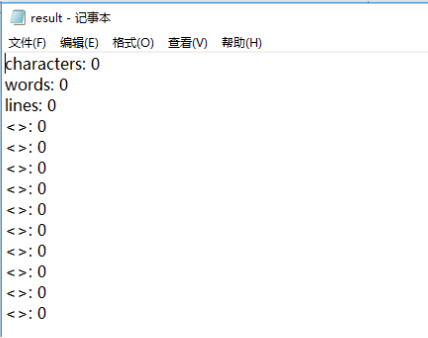
三者皆会输出如图所示的空文本 - 缺少-m指令
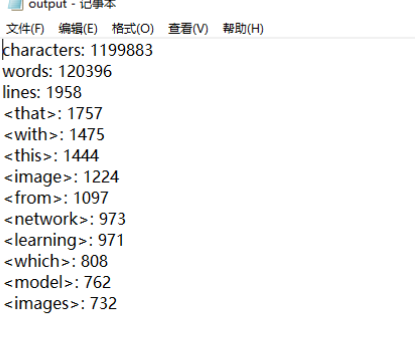
m有默认值为1,因此输出词组为1的结果 - 输入两个-i指令
输出后面那个-i 所指向的地址 - 输入-i,-o,-w,-m,-n五个指令时
- 同一行内词组的长度均比-m的参数小
- 当-w的参数为2时
会避开错误,w采用默认值0,因此为权重0输出的值 - 传入同一个正确的文件,改变-n的参数
正常输出
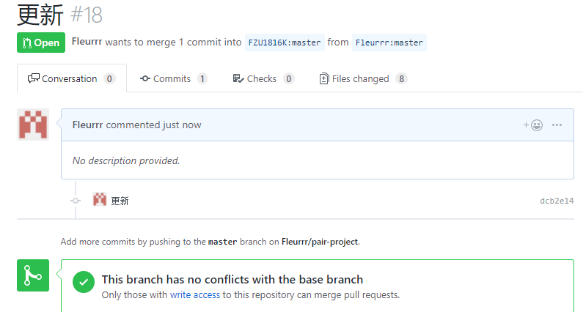
8.贴出Github的代码签入记录

9.遇到的代码模块异常或结对困难及解决方法
(1)在写爬虫的时候,刚开始是往用正则表达式去考虑的,但是后来发现正则表达式难以理解,至少我感觉我到现在还没有弄清楚,所以导致在这个地方卡了好久,后来改用beautifulsoup模块来写,代码简洁,也比较好理解。
(2)在写词频统计功能模块的时候,由于题目的要求比较多,刚开始的时候考虑不周全,回过头来再思考的时候又会发现新的问题,又得改代码,浪费了很多时间,这也是一个教训,下次应该两人一起审题,先商量讨论好了再敲代码。
还有就是因为这次的代码比较繁琐,在自己的写法中设计的标志位相当多,在写代码的时候遇到了忘记了这些标志位作用的情况,下次要记得给标志位取一些简单易懂的名字,防止自己忘记。
10. 评价你的队友
-
蔡文斌对黄泽的评价:
- 对待任务近乎痴迷的程度,看到他这么刚,可以想象到他以后秃头的样子。认真负责的态度还是很感染人的,有时候自己做得感觉很烦的时候,大都是被他所带动的,不会的东西乐于去研究,会执着于一个bug老半天,所以这个对友,我只能给满分了,多一分怕他骄傲。至于改进的地方可能更多的出现在我自己身上,这次的作业我只专注于完成自己的部分,对小泽泽的那一part没有太多深入的了解,导致他有时候跟我讨论他所遇到的问题的时候,我不能够给出有效的建议,这是我觉得对不起他的地方。但是我会争取改进的。也希望我的对友不要嫌弃我,继续带我飞。
-
黄泽对蔡文斌的评价:
- 这次结对作业我负责代码的完善然后蔡文斌负责爬虫的制作。最开始在了解题目的时候我有尝试过自己写一个爬虫,我记得是成功爬取了新浪某个博客的内容,但是爬取cvpr官网的内容失败了,因此成功将锅甩给了蔡文斌。但是到最后几天交流分享的时候,我被他的成果惊艳到了,从对爬虫一无所知到熟练掌握爬虫并深入优化,蔡文斌只用了短短一个多星期的时间,我被他的强大的学习能力深深的震撼了,这点是我所不具备的。如果说硬要找出些什么值得改进的地方的话,就是希望他不要在假期时间在家里躺尸颓废吧(因为他国庆回去了三天好像啥也没干)。
11.学习进度条
- 蔡文斌
| 第N周 | 本周学习消耗时(小时) | 累计学习消耗时(小时) | 重要成长 |
| 5,6 | 20 | 28 | 学习python语言,可以简单的爬取网页的一些东西,对HTML语言也有了一丢丢的了解,可以对数据进行简单的一些可视化处理 |
- 黄泽
| 第N周 | 本周学习消耗时(小时) | 累计学习消耗时(小时) | 重要成长 |
| 5,6 | 24 | 32 | 在个人项目的基础上进行拓展,对于字符串的处理更加熟练,对文本的输入输出流掌握的更加牢固 |
12.心得体会
这次做作业的过程中,更多遇到的是技术上的难题,更加意识到自己能力的不足,自己所欠缺的东西还有好多。完成同样一件事,所要花费的时间却要比别人多。还有就是要调整好自己的心态,因为这次我们两个都差点被代码搞疯了,调整好心态还是很重要的,我们两个也会互相鼓劲,毕竟是绑在一起的人了。这次相比之前,两个人之间的分工更加的明确,这也考验两人之间的配合。两个人之间的交流显得更加重要。