一、关于NOSQL
要理解redis,首先得理解其归属于----NOSQL。
1、什么是NOSQL
NoSQL,泛指非关系型的数据库。随着互联网web2.0网站的兴起,传统的关系数据库在应付web2.0网站,特别是超大规模和高并发的SNS类型的web2.0纯动态网站已经显得力不从心,暴露了很多难以克服的问题,而非关系型的数据库则由于其本身的特点得到了非常迅速的发展。NoSQL数据库的产生就是为了解决大规模数据集合多重数据种类带来的挑战,尤其是大数据应用难题。
-------百度百科
2、从时代背景下考虑,为什么要使用NOSQL
说到数据存储,1)刚开始时单机的MySQL环境,因为大多是静态页面,页面访问量并不大。随着访问量的增多,数据交互频繁,2)便出现了Memcached+MySQL+垂直分布。由于缓存只能缓解读压力,当数据较多时,MySQL还是存在写的压力,3)于是MySQL出现了主从读写分离。而后,高并发的环境,4)水平表分库+水平拆分+MySQL集群成为了一种趋势。但是这些还是不能满足大数据时代需要,虽然关系型数据库十分强大,但是它扩展性能较差。MySQL还是存在一些瓶颈。而NoSQL数据库的产生就是为了解决大规模数据集合多重数据种类带来的挑战,尤其是大数据应用难题,包括超大规模数据的存储。
3、区分传统数据库与非关系型数据库特性
MYSQL:原子性,一致性,独立性,持久性
NOSQL:强一致性,可用性,分区容错性
二、什么是Redis
Redis(Remote Dictionary Server:远程字典服务器)是一个key-value存储系统。和Memcached类似,它支持存储的value类型相对更多,包括string(字符串)、list(链表)、set(集合)、zset(sorted set --有序集合)和hash(哈希类型)。这些数据类型都支持push/pop、add/remove及取交集并集和差集及更丰富的操作,而且这些操作都是原子性的。在此基础上,redis支持各种不同方式的排序。与memcached一样,为了保证效率,数据都是缓存在内存中。区别的是redis会周期性的把更新的数据写入磁盘或者把修改操作写入追加的记录文件,并且在此基础上实现了master-slave(主从)同步。
--------百度百科
三、Redis特性
1、 Redis支持数据持久化。以往将数据存储在内存中有个致命的问题就是当程序退出后内存中的数据会丢失,但是redis支持数据持久化,能将内存中的数据异步写入硬盘中。
2、支持复杂的数据类型。redis不仅支持以键值对(key-value)形式的数据,还支持list、set、zset、hash等数据类型
四、如何开启Redis
1、下载相关jar包:下载
2、解压并安装
先利用tar命令进行解压,进入解压后的文件,执行make命令,执行完毕执行make install命令
3、修改配置文件,启动后台运行功能
先拷贝其配置文件redis.conf,防止后期改动不影响原配置文件(最好将拷贝的文件放在新建的一个文件夹下),并在拷贝的文件中修改redis.conf文件将里面的daemonize no 改成 yes,让服务在后台启动。

3、启动redis
[oracle@localhost myredis]$ redis-server redis.conf 2533:C 29 May 11:10:32.669 # oO0OoO0OoO0Oo Redis is starting oO0OoO0OoO0Oo 2533:C 29 May 11:10:32.671 # Redis version=4.0.9, bits=64, commit=00000000, modified=0, pid=2533, just started 2533:C 29 May 11:10:32.672 # Configuration loaded [oracle@localhost myredis]$ redis-cli -p 6379 127.0.0.1:6379> ping PONG
4、验证
如果ping命令显示pong表示成功
5、关闭
127.0.0.1:6379> shutdown
(error) ERR Errors trying to SHUTDOWN. Check logs.
127.0.0.1:6379> exit
五、关于Redis初别
1、Redis是单进程模型来处理客户端的请求。对读写等事件的响应通过epoll函数进行包装做到的。
2、Redis总共有16个库,默认下标从0开始,可通过select命令进行切换
3、可通过dbsize查看当前数据库key的数量
4、清除数据库的两种方法:flushdb(清空当前数据库);flushall(清空所有数据库,慎用)
5、默认端口为6379
六、Redis相关数据类型命令
1.String
Dbsize:查看当前数据库的key的数量
set: 设置键值对,如 set jia haha 表示为键jia设置值为haha,注意:后面设置的能够覆盖前面的值
Keys * :查看当前数据库的所有的key
get :精确获取某个key ,如果没有会报空
key k?:表示获取以k开头的键
flusthdb:清空当前数据库
flushAll:清空所有的数据库
exists key:判断某个键是否存在 ,存在返回1,不存在返回0 如:exists k1
move key 下标值:将键转移到某个数据库:如 move k3 2 表示将k3转移到3号库中
Expire key time:表示为指定键设置存活时间(防止某个不常用的数据常据内存)如:expire k2 10 表示为k2设置存活时间为10秒
ttl:表示查看某个值的存活时间:-1表示永远不消失-2 表示已经消失,过期,无法访问
del key:表示删除指定的key(redis语句执行成功为1,失败为0)
type key:表示查看指定key的数据类型
clear:(不属于redis命令)用于清除以上所有的编辑数据记录,用于长时间的编辑
append key value:用于在原有的字符串中叠加数据
Strlen key :查看指定的key的长度
incr key :每执行一次,key值增加1(注意:该key值必须 为int型)
decr: 与上相反
incrby key number:每执行一次 ,为指定的key增长指定的值
Decrby key number:与上相反
getrange key number number:获得指定key的指定范围内的值,如getrange k1 0 3
setrange key number number: 将指定key的指定范围位置的覆盖成指定的内容
Setex key number :设置指定的key存活时间 ,如 setex k1 10 v4表示创建k1并且设置k1存活时间为10秒
Setnx key value:先判断key是否存在,存在此语句无效;不存在就创建ky并赋值
mset key value key value..:给多个key赋值
mget key key key:同时查看多个key的值
Msetnx:同时设置一个或者多个key-value,当且仅当所有给定key都不存在,即使只有一个给定key已经存在,msetnx也会拒绝执行所有给定key的设置操作
2、List
lpush list value value..:创建一个list的集合并向他左侧压入值,如:lpuh list01 1 2 3 4 5
lrange list01 0 -1 :(表示查看01集合,0表示从首位置查,-1表示到结尾 )
Rpush list value value:创建一个list的集合并向他右侧压入值
lrange list number number:从左侧遍历指定范围的list集合
Lpop list:左出栈第一个值,出栈后集合不存在该值
rpop list:右出栈第一个值,出栈后集合不存在该值
lindex number 集合:从左开始遍历并获得指定下表的值,没有返回空
llen list:查看指定list长度
Lrem list number value:删除指定集合的指定数量的值:如lrem list01 2 3 :表示删除list01集合中的两个3
Ltrim list number number:截取指定集合的指定范围内的值,原来的集合被截取的集合所取代
Rpoplpush list list:将第一个集合的最右的一个数压入第二个集合的最左边
Lset key index value:从左开始修改指定位置的值
LINSERT list after value01 value02:在value01前插入指定的内容value02
Set:(方法与list相似,只是不允许有重复的值出现)
Lset list number value:将指定集合的指定位置修改为指定值
Linsert list before value:在指定集合的指定值之前插入指定值
3、Set
注意:向set集合添加的数据都是非重复的
Sadd set(集合) value:创建集合,压入值 如:sadd set01 1 2 3
Smembers set(集合):遍历集合的元素并返回出来
Scard set(集合): 获取集合中的有多少个元素
srem set(集合) value:删除集合中的指定元素
srandmember set(集合) number:在指定集合中随机抽取指定个数的元素
Spop set(集合):随机出栈,个数为一
Smove set(集合) set(集合) value:将第一个集合中的制定个值转移到第二个集合中
Sdiff set(集合) set(集合) :取在第一个集合里面而不在后面任何一个sest里面的项
Sinter set(集合)set(集合) :去集合的交集
Sunion set(集合)set(集合 ):去集合的并集
4、Hash
hash 是个键值对的模式,其中k-v中的v是个键值对
hset:创建一个hashset并赋值 如:hset user id 11 这里的v为 id-11,其中k为id,value
为11
Hget: 获得hashset的值,如:hget user id
Hmset::给hashset多重赋值,如:hmset customer id 11 name lisi age 26
Hmget:查看hashset的多个值,如:hmget customer id name age
Hgetall : 获取一个key中所有值(键值对) 如:hgetall customer
Hdel :删除指定key中的指定值(键值对)如:hdel user name
Hlen : 查看指定键的值的长度,如:hlen user
Hexists : 查看指定键是否存在指定值 如:hexists user name
Hkeys :查看指定键中的所有值(键值对)中的键,如:hkeys user
Hvals :查看指定键中的所有值(键值对)中的值,如:hvals user
Hincrby :每执行一次为指定键中的值中指定的值增加指定的整数 如:hincrby user age 2 每执行一次,年龄增加2
Hincrbyfloat:每执行一次为指定键中的值中指定的值增加指定的小数
Hsetnx: 若不存在,为指定的键设置指定的值,否则执行失败
5、Zset
有序set集合,在set的基础上,加上了一个score的值,根据score值的大小达到排序
Zadd:将一个或多个 member 元素及其 score 值加入到有序集 key 当中。如果某个 member 已经是有序集的成员,那么更新这个 member 的 score 值,并通过重新插入这个 member 元素,来保证该 member 在正确的位置上。score 值可以是整数值或双精度浮点数。如果 key 不存在,则创建一个空的有序集并执行 ZADD 操作。当 key 存在但不是有序集类型时,返回一个错误
如:zadd zset01 60 v1 70 v2 80 v3 90 v4 100 v5
表示创建zset01集合,并压入了v1 v2 v3 v4 v5键
Zrange :查看指定集合中的键 如 zrange zset01 0 -1
补充:zrange zset01 0 -1 withscores 返回携带分数的键
Zrangebyscore key :查找指定分数范围内的键 如:zrangebyscore zset01 60 90
补充:分数中间加个“(”表示不包含,如:zrangebyscore zset01 60 (90 表示大于等于60小于90
zrangebyscore zset01 (60 (90 表示大于60小于90
Zrangebyscore zset01 60 90 limit 2 2 :表示在获得60 到90范围内的数中从下表值为2开始抽取两个数
Zrem :删除指定的key 如:zrem zset01 v5
Zcard:统计key的个数 如:zcard zset01
Zcount:统计指定分数范围内的key个数 如:zcount zset01 60 80
Zrank:返回有序集合key中成员member的排名
Zscore:返回指定集合中的key的指定分数 如:zscore zset01 v4
Zrevrank:将指定的key反转,并返回反转后的下标值 如:zrevrank zset v4
Zrevrange:将指定的集合中的key反转,并将它们遍历出来:如 :zrevrange zset01 0 -1
zrevrangeByScore:将指定的集合的分数反转:如 zrevrangeByScore zset01 90 60
七、Redis之配置文件详解
1、Units单位
1)配置大小单位,开头定义了一些基本的度量单位,支持bytes,不支持bit
2)对大小写不敏感
# Note on units: when memory size is needed, it is possible to specify # it in the usual form of 1k 5GB 4M and so forth: # # 1k => 1000 bytes # 1kb => 1024 bytes # 1m => 1000000 bytes # 1mb => 1024*1024 bytes # 1g => 1000000000 bytes # 1gb => 1024*1024*1024 bytes
2、绑定本地地址与开启自摸保护机制
Redis绑定了本定地址:127.0.0.1并且开启了保护机制,此保护机制可防止远程客户端访问,如果想要取消该机制需要将默认值改为no
bind 127.0.0.1
protected-mode yes
3、默认端口号为6379
# Accept connections on the specified port, default is 6379 (IANA #815344). # If port 0 is specified Redis will not listen on a TCP socket. port 6379
4、在高并发环境下你需要一个高backlog值来避免慢客户端连接问题。注意Linux内核默默地将这个值减小
# TCP listen() backlog. # # In high requests-per-second environments you need an high backlog in order # to avoid slow clients connections issues. Note that the Linux kernel # will silently truncate it to the value of /proc/sys/net/core/somaxconn so # make sure to raise both the value of somaxconn and tcp_max_syn_backlog # in order to get the desired effect. tcp-backlog 511
5、Redis默认不是以守护进程的方式运行,可以通过该配置项修改,使用yes启用守护进程
################################# GENERAL ##################################### # By default Redis does not run as a daemon. Use 'yes' if you need it. # Note that Redis will write a pid file in /var/run/redis.pid when daemonized. daemonize no
6、当Redis以守护进程方式运行时,Redis默认会把pid写入/var/run/redis——6379.pid文件,可以通过pidfile指定
# If a pid file is specified, Redis writes it where specified at startup # and removes it at exit. # # When the server runs non daemonized, no pid file is created if none is # specified in the configuration. When the server is daemonized, the pid file # is used even if not specified, defaulting to "/var/run/redis.pid". # # Creating a pid file is best effort: if Redis is not able to create it # nothing bad happens, the server will start and run normally. pidfile /var/run/redis_6379.pid
7、指定日志记录级别,Redis总共支持四个级别:debug、verbose、notice、warning,默认为notice
# Specify the server verbosity level. # This can be one of: # debug (a lot of information, useful for development/testing) # verbose (many rarely useful info, but not a mess like the debug level) # notice (moderately verbose, what you want in production probably) # warning (only very important / critical messages are logged) loglevel notic
8、日志记录方式,默认为标准输出,如果配置Redis为守护进程方式运行,而这里又配置为日志记录方式为标准输出,则日志将会发送给/dev/null
# Specify the log file name. Also the empty string can be used to force # Redis to log on the standard output. Note that if you use standard # output for logging but daemonize, logs will be sent to /dev/null logfile ""
9、指定数据库个数
databases 16
10、Redis快照机制。
指定在多长时间内,有多少次更新操作,在指定的时间间隔内将内存中的数据集快照写入磁盘,可以多个条件配合(重点掌握),其三个条件能触发同步,单位是秒即每1分钟写1万次或者5分钟写10次或者没15分钟写1次都可触发同步
# save "" save 900 1 save 300 10 save 60 10000
11、序列化的时候是否停止写操作
stop-writes-on-bgsave-error yes
12、指定存储至本地数据库时是否压缩数据,默认为yes,Redis采用LZF压缩,如果为了节省CPU时间,可以关闭该选项,但会导致数据库文件变的巨大
rdbcompression yes
13、通过消耗CPU资源对rdb数据进行校验,默认为yes
rdbchecksum yes
14、每次触发同步条件时所生成的文件名
# The filename where to dump the DB
dbfilename dump.rdb
15、设置当本机为slav服务时,设置master服务的IP地址及端口,在Redis启动时,它会自动从master进行数据同步
当master服务设置了密码保护时,slav服务连接master的密码
# slaveof <masterip> <masterport>
# masterauth <master-password>
17、当 slaves 和 master 失去联系或者 复制数据工作仍然在进行。这个适合slave 会有两种选择
当配置 yes(默认的) 意味着slave 会反馈 客户端的请求
当配置 no 客户端会反馈一个error "SYNC with master in progress" ,如果master 无法连接上,则会报"MASTERDOWN Link with MASTER is down and slave-serve- stale-data is set to 'no'."
slave-serve-stale-data yes
18、保护slave ,不让它暴露在不受信任的客户端上。一般用来当做保护层,尤其在果断的client的时候。
当配置yes(默认)的时候,意味着客户端没法给slave 节点写入数据,一写就会报错"READONLY You can't write against a read only slave."
当配置成 no 的时候,任何客户端都可以写入
slave-read-only yes
11、从主机的优先级,如果当主主机挂了的时候,将从从主机中选取一个作为其他从机的主,首先优先级的数字最低的将成为主,0是一个特殊的级别,0将 永远不会成为主。默认值是100.
slave-priority 100
12、设置Redis连接密码,如果配置了连接密码,客户端在连接Redis时需要通过AUTH <password>命令提供密码,默认关闭
################################## SECURITY ################################### # Require clients to issue AUTH <PASSWORD> before processing any other # commands. This might be useful in environments in which you do not trust # others with access to the host running redis-server. # # This should stay commented out for backward compatibility and because most # people do not need auth (e.g. they run their own servers). # # Warning: since Redis is pretty fast an outside user can try up to # 150k passwords per second against a good box. This means that you should # use a very strong password otherwise it will be very easy to break. # # requirepass foobared
13、设置同一时间最大客户端连接数,默认无限制,Redis可以同时打开的客户端连接数为Redis进程可以打开的最大文件描述符数,如果设置 maxclients 0,表示不作 限制。当客户端连接数到达限制时,Redis会关闭新的连接并向客户端返回max number of clients reached错误信息
# maxclients 10000
14、指定Redis最大内存限制,Redis在启动时会把数据加载到内存中,达到最大内存后,Redis会先尝试清除已到期或即将到期的Key,当此方法处理 后,仍然到达最 大内存设置,将无法再进行写入操作,但仍然可以进行读取操作。Redis新的vm机制,会把Key存放内存,Value会存放在swap区
# In short... if you have slaves attached it is suggested that you set a lower # limit for maxmemory so that there is some free RAM on the system for slave # output buffers (but this is not needed if the policy is 'noeviction'). # # maxmemory <bytes>
15、这是redis4.0新增的功能默认情况是以阻塞方式删除对象,如果想手动更改,代替以非阻塞的方式释放内存,比如断开链接已被调用,使用以下配置指令
lazyfree-lazy-eviction no lazyfree-lazy-expire no lazyfree-lazy-server-del no slave-lazy-flush no
16、指定是否在每次更新操作后进行日志记录,Redis在默认情况下是异步的把数据写入磁盘,如果不开启,可能会在断电时导致一段时间内的数据丢失。因为 redis本身同步数据文件是按上面save条件来同步的,所以有的数据会 在一段时间内只存在于内存中。默认为no;指定更新日志文件名,默认为appendonly.aof
appendonly no
appendfilename "appendonly.aof"
17、redis内存淘汰策略
# is reached. You can select among five behaviors: # # volatile-lru -> Evict using approximated LRU among the keys with an expire set. # allkeys-lru -> Evict any key using approximated LRU. # volatile-lfu -> Evict using approximated LFU among the keys with an expire set. # allkeys-lfu -> Evict any key using approximated LFU. # volatile-random -> Remove a random key among the ones with an expire set. # allkeys-random -> Remove a random key, any key. # volatile-ttl -> Remove the key with the nearest expire time (minor TTL) # noeviction -> Don't evict anything, just return an error on write operations. # # LRU means Least Recently Used # LFU means Least Frequently Used # # Both LRU, LFU and volatile-ttl are implemented using approximated # randomized algorithms. # # Note: with any of the above policies, Redis will return an error on write # operations, when there are no suitable keys for eviction. # # At the date of writing these commands are: set setnx setex append # incr decr rpush lpush rpushx lpushx linsert lset rpoplpush sadd # sinter sinterstore sunion sunionstore sdiff sdiffstore zadd zincrby # zunionstore zinterstore hset hsetnx hmset hincrby incrby decrby # getset mset msetnx exec sort # # The default is: # # maxmemory-policy noeviction
八、Redis之安全机制
redis默认没有设置密码,每个库的密码保持一致。之所以这样是因为redis设计的初衷是在linux环境下运行,其环境是安全的,并且它最初只是用来做缓存的。但是并不代表它不能设置密码。
127.0.0.1:6379> config get requirepass #查看当前密码 1) "requirepass" 2) "" #显示空说明默认没有 127.0.0.1:6379> config set requirepass "123456" #设置密码 OK 127.0.0.1:6379> ping #验证 (error) NOAUTH Authentication required. #显示此信息说明密码设置成功 127.0.0.1:6379> auth 123456 #用密码登录 OK 127.0.0.1:6379> ping #验证 PONG
九、Redis之内存淘汰策略
Redis内存淘汰指的是用户存储的一些键被可以被Redis主动地从实例中删除,从而产生读miss的情况。此是Redis一个重要特征。其中:
1) volatile-lru :使用LRU算法移除Key,只针对设置可过期时间的键
2) allKeys-lru :使用LRU算法移除Key
3) volatile-random:在过期集合中移除随机的key,只针对设置了过期时间键
4) allKeys-random:移除随机的key
5) volatile-ttl:移除那些TTL(time-to-live)值最小的Key,即那些最近要过期的key
6) noeviction:不进行移除。针对写操作,只是返回错误信息
7) volatile-lfu:使用LFU移除Key,只针对设置可过期时间的键
8) allKeys-lfu :使用LFU算法移除Key
默认淘汰机制是不过期,即noeivtion,配置文件如下:
# The default is: # # maxmemory-policy noeviction
十、关于SNAPSHOTTING快照(持久化)
Redis持久化包含RDB和AOF
1、RDB:在指定的时间间隔内将内存中的数据集快照写入磁盘,配置文件每次当数据1分钟改了1万次,或者5分钟改了10次或者15分钟改了1此就会触发保存,将信息保存到dump.rdb文件(注意:此文件在哪个目录下启动redis,就在哪个目录下生成dump.rdb文件)
2、RDB之模仿事故配置文件备份
环境:因为手误清空了数据库,模拟数据恢复,注意真实环境中数据读写和数据备份不在同一台机器,这里是在同台机器上演示。
1) 先将配置文件中其中一个触发保存条件将5分钟内更改十次换成1分钟更改10次
save 900 1 save 300 10 save 60 10
2) 开启两个终端,其中一个用来启动redis,另外一个用来查看当前目录下生成的dump.rdb文件
3) 在redis当前数据库中创建11个数据,且这些操作需要在1分钟内完成,此时刷新查看当前目录就能看到新生成的dump.rdb
-rw-r--r-- 1 root root 186 5月 28 21:53 dump.rdb
4) 拷贝dump.rdb文件,命名为copydum.rdb(命名除了“dump.rdb”之外,随意)
-rw-r--r-- 1 root root 186 5月 29 13:56 copydump.rdb
-rw-r--r-- 1 root root 186 5月 28 21:53 dump.rdb
5) 清空数据库,模仿事务,并关闭数据库
6) 再次启动redis,发现数据库中的数据是空的,原因是当flushall或者shutdown关闭数据库时都会会进行数据保存,生成新的dum.rdb来替换新的dum.rdb, 此时的dum.rdb是保存的没有数据的文件,所以当重启数据库,从dum.rdb中拿取的数据时空的。
7) 恢复数据:删除dum.rdb,将原先拷贝的文件进行拷贝,并且命名为dum.rdb(因为源码解释说数据库默认从dum.rdb中抽取数据)
8) 此时重启动redis,数据便恢复了。如果想将数据马上备份,可以使用save命令
如何关闭快照RDB功能:redis -cli config set save “”
3、AOF:以日志的形式来记录每个写操作,将Redis执行过的所有写指令记录下来(读操作不记录),只许追加文件但不可以改写文件,redis启动之初会读取该文件重新构建数据,换言之,redis重启的话就根据日志文件的内容将写指令从前到后执行一次以完成数据的恢复工作(记录每个写的操作,以日志的形式,但不记录读操作)
4、开启AOF功能
redis默认是关闭aof功能的,因为边写边拷贝不止消耗内存,也消耗cpu。但是却保证了数据的完整性。可更改配置文件原配置将no改为yes
appendonly yes
5、模拟事故之AOF数据恢复(正常恢复)
1) 修改配置文件,开启aof配置生效
2) 打开数据库,此时在目录中会生成appendonly.aof文件
-rw-r--r-- 1 root root 1802 5月 28 10:29 appendonly.aof
3) 新建几条数据,并flushall,shutdown数据库,此时目录中会生成dum.rdb文件,我们要删除它,防止其影响数据备份,因为它是份空的文件
4) 编辑appendonly.aof文件,可以看到所有新建的数据记录都写在了此文件中,当然最后的“flushall”语句也记录在里面了,要将此举删除,否则当数据库 调用此日志进行数据备时又会执行此句将数据删除
5) 重启数据库,数据重新备份了
扩展:
环境:模拟事故之数据书写一般突然电源关闭导致记录了错误语法的日志(异常恢复)
分析:当appendonly.aof中如果含有错误语法的语句,数据库将不能启动,在刚生成的appendonly.aof文件中随便添加几个字符(模拟数据写到一半因为 网络延时或 者电源关闭导致数据备份时记录了错误语法的语句)
1) 关闭数据库,此时会生成dum.rdb文件,重启数据库,数据库将不能启动,说明当aof开启时并且appendonly.aof和dump.rdb文件同时存在时,会默认先执行 appendonly.aof文件。
2) 此时需修复appendonly.aof文件。在当前目录(启动redis目录)下,有redis.check-aof命令
3) 执行redis-check-aof,它会修复appendonly.aof备份文件
Redis-check-aof --fix appendonly.aof
4) 重启数据,数据库启动成功,数据成功备份
6、aof数据追加(Appendfsync)分为Always(每次数据变化就追加记录,不推荐,性能不高,默认关闭)和Everysec(每秒追加,异步操作,推荐,默认开启)
# appendfsync always
appendfsync everysec
7、AOF之重写
分析:AOF采用文件追加方式,文件会越来越大为避免出现此种情况,新增了重写机制,当AOF文件的大小超过所设定的阈值时,Redis就会启动 AOF文件的内容压缩,只保留可以恢复数据的最小指令集.可以使用命令bgrewriteaof
原理:
AOF文件持续增长而过大时,会fork出一条新进程来将文件重写(也是先写临时文件最后再rename),遍历新进程的内存中数据,每条记录有一条的Set语 句。重写aof文件的操作,并没有读取旧的aof文件,而是将整个内存中的数据库内容用命令的方式重写了一个新的aof文件,这点和快照有点类似触发机 制:Redis会记录上次重写时的AOF大小,默认配置是当AOF文件大小是上次rewrite后大小的一倍且文件大于64M时触发
auto-aof-rewrite-percentage 100
auto-aof-rewrite-min-size 64mb
8、RDB和AOF优缺点
RDB:
优点:RDB 是一个非常紧凑(compact)的文件,它保存了 Redis 在某个时间点上的数据集。 这种文件非常适合用于进行备份。RDB 可以最大化 Redis 的性能:父进程在保存 RDB 文件时唯一要做的就是 fork 出一个子进程,然后这个子进程就会处理接下来的所有保存工作,父进程无须执行任何磁盘 I/O 操作。RDB 在恢复大数据集时的速度比 AOF 的恢复速度要快。
缺点:如果注重数据完整性,如果机器发生故障停机, 有可能会丢失好几分钟的数据。
AOF:
优点:使用 AOF 持久化会让 Redis 变得非常耐久,能保证数据的完整性。AOF 的默认策略为每秒钟 fsync 一次,在这种配置下,Redis 仍然可以保持良好的性能,并且就算发生故障停机,也最多只会丢失一秒钟的数据。
缺点:对于相同的数据集来说,AOF 文件的体积通常要大于 RDB 文件的体积。
十一、Redis之事务
1、相关命令
MULTI #标记一个事务的开始
WATCH Key #监视一个或多个键,若在事务执行之前被监视的key改动,那么事务将被打断
EXEC #执行所有事务快内命令
UNWATCH #取消监视
DISCARD #取消事务,放弃执行事务快内命令
2、命令使用
开启事务 127.0.0.1:6379> MULTI OK 127.0.0.1:6379> set k1 v1 QUEUED 127.0.0.1:6379> set k2 v2 QUEUED 127.0.0.1:6379> EXEC 1) OK 2) OK 127.0.0.1:6379> KEYS * 1) "k3" 2) "k2" 3) "k1" 放弃事务 127.0.0.1:6379> MULTI OK 127.0.0.1:6379> set k1 bb QUEUED 127.0.0.1:6379> set k2 ss QUEUED 127.0.0.1:6379> DISCARD OK 127.0.0.1:6379> KEYS * 1) "k3" 2) "k2" 3) "k1" 一条语法出错,其他无法执行 127.0.0.1:6379> MULTI OK 127.0.0.1:6379> set k2 v2 QUEUED 127.0.0.1:6379> setget k1 (error) ERR unknown command 'setget' 127.0.0.1:6379> getset k3 (error) ERR wrong number of arguments for 'getset' command 127.0.0.1:6379> set k4 v4 QUEUED 127.0.0.1:6379> EXEC (error) EXECABORT Transaction discarded because of previous errors. 127.0.0.1:6379> KEYS * (empty list or set) 冤头债主(哪条执行不合乎语意,但不是语法错误,能入列,不报错,则只有它不执行) K1为字符串 127.0.0.1:6379> MULTI OK 127.0.0.1:6379> INCR k1 QUEUED 127.0.0.1:6379> set k4 v4 QUEUED 127.0.0.1:6379> EXEC 1) (error) ERR value is not an integer or out of range 2) OK 127.0.0.1:6379> get k4 "v4" 127.0.0.1:6379> KEYS * 1) "k1" 2) "k4"
3、悲观锁与乐观锁
悲观所:预测操作时会出错,将整张表给锁起来,防止其他操作者操作此表,直到解锁。并发性差,一致性好
乐观锁:不锁整张表,在每条记录下加个version版本号(数字),在操作该记录后将版本号增加1,当其他操作者在同一时间操作同条数据时,会因为版本号的不同导致提交失败。并发性高,一致性也高
4、事务监控
在执行执行事务之前监控变量,在多并发情况下可以监控变量,事务会因为版本号的不同导致事务提交失败
用法:
第一个客户端:设置余额和消费
127.0.0.1:6379> clear 127.0.0.1:6379> set balance 100 OK 127.0.0.1:6379> ste dept 0 (error) ERR unknown command 'ste' 127.0.0.1:6379> set dept 0 OK 127.0.0.1:6379> WATCH balance OK 127.0.0.1:6379> MULTI OK 127.0.0.1:6379> DECRBY balance 20 QUEUED 127.0.0.1:6379> INCRBY dept 20 QUEUED
第二个客户端
127.0.0.1:6379> get balance "80" 127.0.0.1:6379> set balance 800 #将balance变为800 OK 127.0.0.1:6379>
第一个客户端
127.0.0.1:6379> exec
(nil) #因为中途有人更改过值,事务执行失败
此时客户端一只能执行unwatch命令后重新监视balance对数据进行操作
十二、Redis之发布订阅
1、发布订阅是指一个端口号监听到另一个端口号后(如同订阅),被监听的机器发布消息,订阅的能及时接收到发布的消息
2、常用命令
PSUBSCRIBE pattern [pattern..] #订阅一个或多个符合给定模式的频道
PUBSUB subcommand [argument [argument..]] #查看订阅与发布系统状态
PUBLISH channel message #将信息发送到指定的频道
PUNSUBSCRIBE [pattern[pattern..]] #退订所有给定模式的频道
SUBSCRIBE channel [channel..] #订阅给定的一个或多个频道的信息
UNSUBBSCRIBE [channel[channel]] #指退订给的频道
3、用法
1) 同时开启两个客户端。其中一个客户端用来订阅消息,另一个用来发送消息,订阅消息的客户端能够接受发送端发过的消息
2) 订阅端先订阅消息
127.0.0.1:6379> SUBSCRIBE c1 c2 c3 #模拟订阅了c1,c2,c3频道 Reading messages... (press Ctrl-C to quit) 1) "subscribe" 2) "c1" 3) (integer) 1 1) "subscribe" 2) "c2" 3) (integer) 2 1) "subscribe" 2) "c3" 3) (integer) 3
3)发送端发送消息
127.0.0.1:6379> PUBLISH c2 hello-redis
(integer) 1
4)此时订阅端能接收到发送端发送的消息
2) "c2" 3) "hello-redis"
扩展,可以用“*”模糊匹配订阅多个消息
如订阅端
127.0.0.1:6379>PSUBSCIBE new*
发送端
127.0.0.1:6379> PUBLISH new1 redis2015
(integer) 1
十三、Redis的复制机制
1、什么是redis的复制
也就是我们所说的主从复制,主机数据更新后根据配置和策略,自动同步到备机的master/slaver机制,Master以写为主,Slave以读为主
2、能干嘛?
读写分离 容灾恢复
用法
1) 同时开启三个终端,并且分别命名为79,80,81端口
2) 复制redis的配置文件,并且命名为redis79.conf;redis80.conf;redis;81.conf
3) 更改三个配置文件的内容
3.1)pidfile /var/run/redis6379.pid //命名根据指定的端口号为准,如80端口就是 redis_6380.pid
3.2)port 6379 //命名根据指定的端口号为准,如80端口就是6380
3.3)logfile "6379.log"
3.4)dbfilename dump6379.rdb
4) 重用三招
4.1)一主二仆
1.启动三台终端的redis,注意启动时的端口号
redis-server redis80.conf //如启动80端口的客户端
redis-cli -p 6380
2.三台redis同时输入 info replication,此时三者角色的身份都是master
3.如果要想玩主从复制,将79端口定义为主(master),80和81端口的定义为从(slave),主具有读写权限,而从只有读权限,每次主更新了内容,从都能遍历到主更新的内容
4.设置
79端口:不做处理
80端口:SLAVEOF 127.0.0.1 6379 //监听79端口
81端口:SLAVEOF 127.0.0.1 6379 //监听79端口
此时79端口身份还是master,80和81端口身份变成了slave
每次79端口set一个新值,80和81端口都可以get这个新值
但是80和81端口不能set新值
注意:每次与master断开之后,都需要重新连接然后监听主机端口,除非你配置进redis.conf文件,但是主机断开没事,只要从机没关,主机重新登录后从机继续监听主机
4.2)薪火相传
一主二仆的缺点是当主机挂时,其他从机就只能等待主机重新连接上才能运作
分析:将79端口作为主机,80端口还是监听79端口,但是81端口不再监听79端口,而是80端口,此时80端口角色相对于79端口是slave,相对于81端口却是master,
虽然81端口监听的是80端口,但是依然能接收到来自79端口新存进的值
如果79端口关闭,由80端口作为新主机(master)。
79端口:不做处理
80端口:SLAVEOF 127.0.0.1 6379
81端口:SLAVEOF 127.0.0.1 6380
上一个Slave可以是下一个slave的Master,Slave同样可以接收其他
slaves的连接和同步请求,那么该slave作为了链条中下一个的master,
可以有效减轻master的写压力
中途变更转向:会清除之前的数据,重新建立拷贝最新的
4.3)反客为主
1、使当前数据库停止与其他数据库的同步,转成主数据库(也就是说此时环境是80端口和81端口同时监听79端口,当主机79端口断开后,80端口反客为主,将自己身份设置为主机替代79端口)
2、做法
环境开始前:
79端口:不做处理
80端口:SLAVEOF 127.0.0.1 6379
81端口:SLAVEOF 127.0.0.1 6379
环境开始:
79端口:shutdown
80端口:SLAVEOF no one
81端口:SLAVEOF 127.0.0.1 6380 //此时81端口有两个选择,1选择等待主机号开 启,2是重新选择主机号。此时80端口有写的 权限,80端口更新值后81端口可以遍历到
十四、redis的哨兵模式(sentinel)
1、分析:反客为主确实能解决主机挂断后替补问题,但是采用手动方式还是显得有点笨重不方便。而哨兵模式便是自动方式。它是反客为主的自动版,能够后台监控主机是否故障,如果故障了根据投票数自动将从库转换为主库。
2、用法
1)环境:80端口和81端口同时监听79端口
2)在启动redis目录下新建sentinel.conf文件,名字绝不能错
[root@localhost myredis]# touch sentinel.conf
3) 编辑sentinel.conf文件,配置现在主机为79端口号,当主机端口端口时采用 投票方式重新选取主机
sentinel monitor host6379 127.0.0.1 6379 1 #最后一个数字1,表示主机挂掉后salve投票看让谁接替成为主机,得票数多少后成为主机
4) 开启哨兵模式
[root@localhost myredis]# redis-sentinel sentinel.conf
5) 此时关闭79端口号,哨兵会监控到79挂失,重新选取新的主机号,选取方式采 用投票方式,不能认为控制
此时可以看到81端口号被选举为主机,80端口不再监控79端口(即使79端口重启),监听81端口号
十五、Jedis
Jedis是java原生操作redis,通过java代码操作redis数据库中的数据
1、部署环境
1)先引入maven依赖
<!--引入java访问redis客户端:Jedis--> <dependency> <groupId>redis.clients</groupId> <artifactId>jedis</artifactId> <version>2.7.3</version> </dependency>
2) 编写测试类,测试连通性
Jedis jedis=new Jedis("127.0.0.1",6379); System.out.println(jedis.ping());
若不显示PONG,错误分析如下
- Connection refused
分析原因:这是因为redis默认启动的是保护措施,绑定了127.0.0.1,并且开启了保护措施
1)编辑redis.Conf文件Vim redis.conf
2)注销掉127.0.0.1 #127.0.0.1
将protected-mode yes改为no
2、Connect time out分析原因:连接时间超时,是因为防火墙没开放此端口号,解决方式要么关闭防火墙(不推荐),要么在iptables中配置6379端口号,并重启防火墙
1) vim /etc/sysconfig/iptables
#reids -A INPUT -p TCP --dport 6379 -j ACCEPT -
[root@localhost myredis]#service iptables restart
2、测试Jedis API
测试一、
Jedis jedis=new Jedis("127.0.0.1",6379); jedis.set("k1","v1"); jedis.set("k2","v2"); jedis.set("k3","v3"); System.out.println(jedis.get("k3")); Set<String> set=jedis.keys("*"); System.out.println(set.size());
测试二、
public class Test02{ public static void main(String[] args){ Jedis jedis = new Jedis("127.0.0.1",6379); //key Set<String> keys = jedis.keys("*"); for (Iterator iterator = keys.iterator(); iterator.hasNext();) { String key = (String) iterator.next(); System.out.println(key); } System.out.println("jedis.exists====>"+jedis.exists("k2")); System.out.println(jedis.ttl("k1")); //String //jedis.append("k1","myreids"); System.out.println(jedis.get("k1")); jedis.set("k4","k4_redis"); System.out.println("----------------------------------------"); jedis.mset("str1","v1","str2","v2","str3","v3"); System.out.println(jedis.mget("str1","str2","str3")); //list System.out.println("----------------------------------------"); //jedis.lpush("mylist","v1","v2","v3","v4","v5"); List<String> list = jedis.lrange("mylist",0,-1); for (String element : list) { System.out.println(element); } //set jedis.sadd("orders","jd001"); jedis.sadd("orders","jd002"); jedis.sadd("orders","jd003"); Set<String> set1 = jedis.smembers("orders"); for (Iterator iterator = set1.iterator(); iterator.hasNext();) { String string = (String) iterator.next(); System.out.println(string); } jedis.srem("orders","jd002"); System.out.println(jedis.smembers("orders").size()); //hash jedis.hset("hash1","userName","lisi"); System.out.println(jedis.hget("hash1","userName")); Map<String,String> map = new HashMap<String,String>(); map.put("telphone","13811814763"); map.put("address","atguigu"); map.put("email","abc@163.com"); jedis.hmset("hash2",map); List<String> result = jedis.hmget("hash2", "telphone","email"); for (String element : result) { System.out.println(element); } //zset jedis.zadd("zset01",60d,"v1"); jedis.zadd("zset01",70d,"v2"); jedis.zadd("zset01",80d,"v3"); jedis.zadd("zset01",90d,"v4"); Set<String> s1 = jedis.zrange("zset01",0,-1); for (Iterator iterator = s1.iterator(); iterator.hasNext();) { String string = (String) iterator.next(); System.out.println(string); } } }
测试事务
Jedis jedis=new Jedis("127.0.0.1",6379); //开启事务 Transaction transaction=jedis.multi(); transaction.set("k4", "v44"); transaction.set("k5", "v55"); // transaction.exec(); //放弃事务 transaction.discard();
测试事务监控
public boolean transMethod() throws InterruptedException{ Jedis jedis=new Jedis("127.0.0.1",6379); int balance;//余额 int debt;//欠额 int amtToSubtract=10;//实刷额度 jedis.watch("balance");//加入监控 //模拟异常时,将屏蔽的代码打开 //Thread.sleep(7000); //模拟网络拥堵 //在拥堵过期间,在redis客户端将balance的值设置为7,模拟两人同时操作一个资源 balance=Integer.parseInt(jedis.get("balance")); if(balance<amtToSubtract){ jedis.unwatch(); System.out.println("modify");//已经有人修改 return false;//提交失败,必须得重新获得版本号,重新设置事务并且进行提交 }else{ System.out.println("**************transaction"); Transaction transaction=jedis.multi(); transaction.decrBy("balance", amtToSubtract);//消费 transaction.incrBy("debt", amtToSubtract);//欠下 transaction.exec();//提交,进行批处理 balance=Integer.parseInt(jedis.get("balance")); debt=Integer.parseInt(jedis.get("debt")); System.out.println("******"+balance); System.out.println("******"+debt); return true; } } /** * 通俗的讲,watch命令就是标记一个键,如果标记了一个键 * 在提交事务前如果该键被别人标记修改过,那事务就会失败,这种情况通常可以再程序中 * 重新尝试 * 首先标记了键balance,然后检查余额是否只够,不足取消标记,并不做扣减; * 足够的话,就启动事务进行更行操作 * 如果在此期间 键balance被其他人修改过,那么在提交 事务(执行exec)时就会报错 * 程序中通常可以捕获这类错误再重新执行一次,直到成功。 * @throws InterruptedException * */ public static void main(String[] args) throws InterruptedException{ TestDemoTX test=new TestDemoTX(); boolean retValue=test.transMethod(); System.out.println("main retValue----"+retValue); }
测试主从复制
Jedis jedis_M=new Jedis("127.0.0.1",6379); Jedis jedis_S=new Jedis("127.0.0.1",6380); jedis_S.slaveof("127.0.0.1", 6379); jedis_M.set("class", "1122"); String result=jedis_S.get("class"); System.out.println(result );
测试Jedis_Pool
将new Jedis的操作交给jedis_Pool,减少内存损耗 /** * Jedis工具类,利用单列模式懒汉模式 * @author Administrator * */ public class JedisPoolUtil { //一旦一个共享变量(类的成员变量、类的静态成员变量)被volatile修饰之后,那么就具备了两层语义: //1)保证了不同线程对这个变量进行操作时的可见性,即一个线程修改了某个变量的值,这新值对其他线程来说是立即可见的。 //2)禁止进行指令重排序。 private static volatile JedisPool jedisPool=null; private JedisPoolUtil(){} public static JedisPool getJedisPoolInstance(){ if(null==jedisPool){ synchronized (JedisPoolUtil.class) { if(null==jedisPool){ JedisPoolConfig poolConfig=new JedisPoolConfig(); poolConfig.setMaxActive(1000);//设置最大连接数 poolConfig.setMaxIdle(32);//设置最大空闲数 poolConfig.setMaxWait(100*1000);//最大的等待时间,如果超过等待时间,则直接抛出JedisConnectionException poolConfig.setTestOnBorrow(true);//设置是否检查连接成功 jedisPool=new JedisPool(poolConfig,"127.0.0.1",6379); } } } return jedisPool; } public static void release(JedisPool jedisPool,Jedis jedis){ if(null!=jedis){ jedisPool.returnResourceObject(jedis); } } } /** * 测试应用连接池工具 * @author Administrator * */ public class TestConnect { public static void main(String[] args){ JedisPool jedisPool=JedisPoolUtil.getJedisPoolInstance(); Jedis jedis=null; try{ jedis=jedisPool.getResource(); jedis.set("aa","bb"); }catch(Exception e){ e.printStackTrace(); }finally{ JedisPoolUtil.release(jedisPool, jedis); } } }
十六、高并发环境下秒杀相关代码之引用redis案例
当缓存中没有数据,从(关系型)数据库中拿取数据,然后放进缓存,有就直接从缓存中拿取
1、引入jedis依赖
<!--引入java访问redis客户端:Jedis--> <dependency> <groupId>redis.clients</groupId> <artifactId>jedis</artifactId> <version>2.7.3</version> </dependency>
2、引入序列化依赖(此依赖是个高效的序列化,相对于类继承seriliazible,它更高效)
<!--使用开源社区高效序列化插件--> <!--protostuff序列化依赖--> <!-- https://mvnrepository.com/artifact/com.dyuproject.protostuff/protostuff-core --> <dependency> <groupId>com.dyuproject.protostuff</groupId> <artifactId>protostuff-core</artifactId> <version>1.0.8</version> </dependency> <!-- https://mvnrepository.com/artifact/com.dyuproject.protostuff/protostuff-runtime --> <dependency> <groupId>com.dyuproject.protostuff</groupId> <artifactId>protostuff-runtime</artifactId> <version>1.0.8</version> </dependency>
3、创建redis dao层
public class RedisDao { private JedisPool jedisPool; //自定义序列化(推荐用类实现serilazible,因为性能不高),此需要加入protostuff private RuntimeSchema<Seckill> schema=RuntimeSchema.createFrom(Seckill.class); public RedisDao(String ip,int port){ jedisPool=new JedisPool(ip,port); } //获取秒杀对象 public Seckill getSeckill(long seckillId){ //redis操作逻辑 try{ Jedis jedis=jedisPool.getResource(); try { //快速生成try/catch:Ctr+Alt+T String key="seckill:"+seckillId; //redis对于类的操作并没有实现内部序列化操作,它存储的都是一个二进制数组,必须通过反序列化将二进制转化为类 // 思路:1.seckill实现serilizable(不高效,jdk内部方法);2.采用开源社区较高效的 //get->byte[] ->反序列化->Object(Seckill) //采用自定义序列化 byte[] bytes=jedis.get(key.getBytes()); if(bytes!=null){ //空对象 Seckill seckill=schema.newMessage(); //将数据传送到空对象中 ProtobufIOUtil.mergeFrom(bytes,seckill,schema); //seckill被序列化 return seckill; } }finally { jedis.close(); } }catch(Exception e){ e.printStackTrace(); } return null; } //将seckill对象存进redis中,存取秒杀对象 public String putSeckill(Seckill seckill){ //set Object(Seckill) -->序列化-->byte[]-->redis try { Jedis jedis=jedisPool.getResource(); try { String key="seckill:"+seckill.getSeckillId(); //LinkedBuffer缓存器,当数据较大时会有一定缓存 byte[] bytes=ProtobufIOUtil.toByteArray(seckill,schema, LinkedBuffer.allocate(LinkedBuffer.DEFAULT_BUFFER_SIZE)); //超时缓存 int timeout=60*60;//缓存一个小时 //返回结果,如果错误返回错误信息,正确则返回“ok” String result=jedis.setex(key.getBytes(),timeout,bytes); return result; } finally { jedis.close(); } } catch (Exception e) { e.printStackTrace(); } return null; } }
4、注入dao层
<!--注入RedisDao-->
<bean id="redisDao" class="org.seckill.dao.cache.RedisDao">
<!--配置该Dao层的构造方法中的两个参数,否则无法使用-->
<!--配置IP-->
<constructor-arg index="0" value="localhost"/>
<!--配置port端口号,redis端口号默认为6379-->
<constructor-arg index="1" value="6379"/>
</bean>
5、编写测试类
@RunWith(SpringJUnit4ClassRunner.class) @ContextConfiguration({"classpath:spring/spring-dao.xml"}) public class RedisDaoTest{ private long id=1001; @Autowired private RedisDao redisDao; @Autowired private SeckillDao seckillDao; @Test public void testSeckill() throws Exception { //get and put Seckill seckill=redisDao.getSeckill(id); if(seckill==null){ //如果缓存没有,从数据库中拿取数据 seckill=seckillDao.queryById(id); if(seckill!=null){ //将数据库中拿取的数据放进缓存中 String result=redisDao.putSeckill(seckill); System.out.println(result); seckill=redisDao.getSeckill(id); System.out.println(seckill); } } }
其架构图为:
读多写少用缓存,读少写多用队列

十七、客户端与Redis
1、哨兵功能:
告诉客户端,哪台redis服务器可以用
维护redis主从,当主服务器挂失,主从自动切换,将从变成主
哨兵沟通渠道:主redis上面的专属通讯
命令:subscribe_sentinel_:hello
Master挂掉:
sdown 主观的认为master挂掉(挂掉的哨兵)
odown 客观的认为master,超过半数的哨兵认为master挂掉了
意思是一台哨兵挂掉不一定认为挂掉,需要和其他哨兵沟通,如果都认为挂掉了,那就是挂掉了
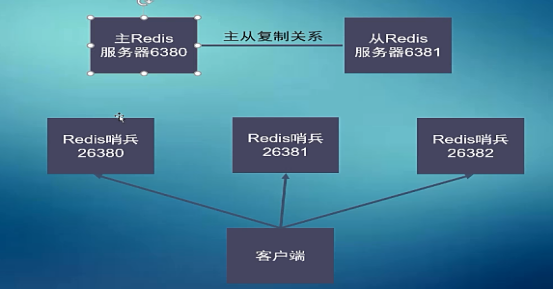
2、哨兵启动原理
配置哨兵需要sentinel.conf文件
此配置文件需要告诉哨兵哪个是主
当主挂失,文件会自动更新内容,哨兵能自动更改配置
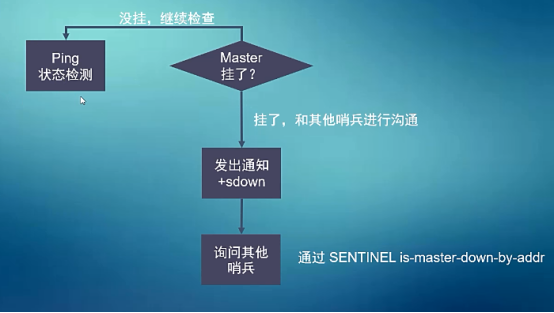
3、哨兵原理:Redis状态检测
4、哨兵模式客户端
每个1秒中访问一次redis
可以手动停掉其中一台机器挂失,查看打印的信息
当主机挂失后再次启动,它已经变成了从,无法执行写 操作,只有读操作
public class TestDemo { public static void main(String[] args) { Set<String> set=new HashSet<String>(); set.add("192.168.174.130:6379"); set.add("192.168.174.130:6380"); set.add("192.168.174.130:6381"); JedisSentinelPool pool=new JedisSentinelPool("myMaster", set); //没隔1秒,访问一次redis while(true){ Jedis jedis=null; try { jedis=pool.getResource(); String value=jedis.get("hello"); System.out.println(System.currentTimeMillis()+"-从redis中抽取的结果-"); Thread.sleep(1000L); } catch (InterruptedException e) { // TODO Auto-generated catch block e.printStackTrace(); }finally{ if(jedis!=null){ jedis.close(); } } } } }
5、哨兵原理--选举leader过程
1、自己先选一个最小的,RunID,再看别人选的是什么
相关代码:SENTINEL is-master-down-by-addr 查询其他哨兵的选举结果/查询master状况
2、官方文档显示:
Disconnection time from the master
Slave priority
Replication offset processed
Run ID

6、哨兵原理--选举master
1、选择非挂失
2、选择优先级高的(在redis.conf文件中有优先级设置slave-priority)
3、同步情况
4、最小run id
7、关于Redis客户端底层
客户端和Redis交互,其实就是Socket编程
代码一:手写客户端与Redis交互底层原理
/** * Redis客户端底层 * 底层就是Socket编程 * @author Administrator * */ public class RedisClient { public static void main(String[] args) throws Exception { Socket client=new Socket("192.168.174.133",6379); /*发送语句一: * 发包 表示一段数据的结束(不配置否则会报错) * 结果:-ERR unknown command 'hello-redis'(因为语法,需要遵守redis相关协议) client.getOutputStream().write("hello-redis ".getBytes());*/ /*发送语句二: * 结果::10 */ client.getOutputStream().write("dbsize ".getBytes()); //接受redis server响应 byte[] response=new byte[1024]; client.getInputStream().read(response); System.out.println(new String(response)); } }
代码二:手写客户端存储数据于Redis底层原理
/** * 手写客户端 * * @author Administrator * */ public class RedisClient2 { // 每段数据 分隔 // *数组 // $多行字符串 // +单行信息 // -错误信息 // :整形数字 private OutputStream writer; private InputStream reader; public RedisClient2(String host, int port) throws Exception { Socket client = new Socket(host, port); writer = client.getOutputStream(); reader = client.getInputStream(); } // set key value public String set(String Key, String value) throws Exception { // 组装一个请求报文 -RESP StringBuffer command = new StringBuffer(); command.append("*3").append(" ");// 开头,报文包含几个部分 command.append("$3").append(" ");// 第一部分命令的类型是多行字符串,长度为3 command.append("set").append(" ");// 第一部分命令的数据值 // 为什么要转为字节数组因为要将中文转化为字节数组才能识别 command.append("$").append(Key.getBytes().length).append(" ");// 第二部分数据的长度 command.append(Key).append(" ");// 第二部分数据的值 command.append("$").append(value.length()).append(" ");// 第二部分数据的长度 command.append(value).append(" ");// 第二部分数据的值 // 发送一个命令报文到redis服务器 writer.write(command.toString().getBytes()); // 接受redis执行结果 byte[] response = new byte[1024]; reader.read(response); return new String(response); } // get key public String get(String key) throws Exception { // 组成一个请求报文RESP StringBuffer command = new StringBuffer(); command.append("*2").append(" "); command.append("$3").append(" "); command.append("get").append(" "); command.append("$").append(key.getBytes().length).append(" "); command.append(key).append(" "); // 发送一个命令报文到redis服务器 writer.write(command.toString().getBytes()); // 接受redis执行结果 byte[] response = new byte[1024]; reader.read(response); return new String(response); } public static void main(String[] args) throws Exception { RedisClient2 redis = new RedisClient2("192.168.174.133", 6379); String info = redis.set("liyiling", "iloveu"); System.out.println(info);// 结果:+OK String result=redis.get("liyiling"); System.out.println(result);//结果:$6 iloveu } }
代码三:手写订阅消息底层
/** * 订阅机制的实现 * @author Administrator * */ public class Subscribe { private OutputStream writer; private InputStream reader; //支持订阅的程序 public Subscribe(OutputStream writer,InputStream reader){ this.writer=writer; this.reader=reader; } //订阅一个消息频道 public void news(String myNew) throws Exception{ //和redis-server通信 //subscribe channel //组装一个请求报文 -RESP StringBuffer command = new StringBuffer(); command.append("*2").append(" "); command.append("$9").append(" "); command.append("subscribe").append(" "); command.append("$").append(myNew.getBytes().length).append(" "); command.append(myNew).append(" "); writer.write(command.toString().getBytes()); //实现实时接收 while(true){ byte[] dontai=new byte[1024]; reader.read(dontai); System.out.println(myNew+"订阅的消息有动态了"); System.out.println(new String(dontai)); } } public static void main(String[] args) throws Exception { RedisClient2 redis = new RedisClient2("192.168.174.133", 6379); Subscribe subscribe=redis.subscribe(); subscribe.news("liyiling"); } }
此时可以再redis一台机器中发布一个消息
127.0.0.1:6379> publish liyiling smile
(integer) 1
控制台能显示接受到的消息

十八、Redis扩展
以下是在网上找到的一些资源
1、Redis 管道(pipeline)
在插入多条数据时,使用Redis管道能够增快redis执行速度。redis的pipeline(管道)功能在命令行中没有,但是redis是支持管道的,在java的客户端(jedis)中是可以使用的。
测试如下:
1) 不使用管道,执行时间为372
long currentTimeMills=System.currentTimeMillis(); Jedis jedis=new Jedis("192.168.174.133",6379); for(int i=0;i<1000;i++){ jedis.set("test"+i,"test"+i); } long endTimeMills=System.currentTimeMillis(); System.out.println(endTimeMills-currentTimeMills);
2) 使用管道,执行时间为83
long currentTimeMills=System.currentTimeMillis(); Jedis jedis=new Jedis("192.168.174.133",6379); Pipeline pipeline=jedis.pipelined(); for(int i=0;i<1000;i++){ pipeline.set("test"+i,"test"+i); } pipeline.sync(); long endTimeMills=System.currentTimeMillis(); System.out.println(endTimeMills-currentTimeMills);
2、Redis应用场景
限制网站访客访问频率
进行各种数据统计的用途是非常广泛的,比如想知道什么时候封锁一个IP地址。INCRBY命令让这个变得很容易,通过原子递增保持计数;GETSET用来重置计数器;过期expire用来确定一个关键字什么时候应该删除。
代码如下:
public class TestDemo2 { String host="192.168.174.133"; int port=6379; Jedis jedis=new Jedis(host,port); /** * 限制网站访问频率,一分钟之内最多访问10次 */ public void test3() throws Exception{ //模拟用户频繁请求 for(int i=0;i<20;i++){ boolean result=testLogin("192.168.174.133"); if(result){ System.out.println("正常访问"); }else{ System.out.println("访问受限制"); } } } public boolean testLogin(String ip){ String value=jedis.get(ip); if(value==null){ //初始化时设置IP访问此时 jedis.set(ip,"1"); //设置IP的生存时间为60秒,60秒内IP的访问次数由程序控制 jedis.expire(ip,60); }else{ int parsetInt=Integer.parseInt(value); //如果60秒内IP的访问次数超过10,返回false,实现了超过10次禁止分的功能 if(parsetInt>10){ return false; }else{ //如果没有10次。可以自增 jedis.incr(ip); } } return true; } public static void main(String[] args) throws Exception { TestDemo2 t=new TestDemo2(); t.test3(); } }
执行结果

3、Redis经典面试题
MySQL里有2000w数据,redis中只存20w的数据,如何保证redis中的数据都是热点数据
相关知识:redis 内存数据集大小上升到一定大小的时候,就会施行数据淘汰策略。redis 提供 6种数据淘汰策略:
voltile-lru:从已设置过期时间的数据集(server.db[i].expires)中挑选最近最少使用的数据淘汰
volatile-ttl:从已设置过期时间的数据集(server.db[i].expires)中挑选将要过期的数据淘汰
volatile-random:从已设置过期时间的数据集(server.db[i].expires)中任意选择数据淘汰
allkeys-lru:从数据集(server.db[i].dict)中挑选最近最少使用的数据淘汰
allkeys-random:从数据集(server.db[i].dict)中任意选择数据淘汰
no-enviction(驱逐):禁止驱逐数据