| 这个作业属于哪个课程 | 2021春软件工程实践|W班(福州大学) |
|---|---|
| 这个作业要求在哪里 | 寒假作业2/2 |
| 这个作业的目标 | 阅读《构建之法》并提问,完成词频统计个人作业 |
| 其他参考文献 | 《构建之法现代软件工程第3版》 《码出高效_阿里巴巴Java开发手册》 |
目录
part1:阅读《构建之法》并提问
I.I 问题1
为什么要在个人开发流程中需要花费精力制作PSP表格?
关于第2章的2.3个人开发流程中有这么一段内容:“PSP依赖于数据。需要工程师输入数据,记录工程师的各项活动,这本身就需要不小的时间代价。” 在填写PSP中的预估时间时,由于没有一定的参考标准的话,我发现自己很难去预估各个阶段所要花费的时间。而且在实际开发过程中,我也很难详细地记录我在各个计划段内所用时间,因为有时会多个计划段并行。所以我不是很理解在个人开发中花费精力去制作一个并不是很准确PSP表格的意义。
I.II 问题2
个人开发中是否可以省略代码复审的环节?
关于第4章的4.4代码复审中有这么一段内容:“用同伴复审的标准来要求自己。不一定最有效,因为开发者对自己总是过于自信。如果能持之以恒,则对个人有很大好处”。如果只是进行个人开发,其实个人在编码和测试的时候代码就已经处在不断复审之中,那么代码复审其实是可以作为与编码和测试并行的阶段而被省略的。
I.III 问题3
两个程序员差距过大时结对编程是否意义不大?
关于第4章的4.5结对编程中有这么一段内容:“在结对编程中,因为有随时的复审和交流,程序各方面的质量取决于一对程序员中各方面水平较高的那一位。这样,程序中的错误就会少得多,程序的初始质量会高很多,这样会省下很多以后修改、测试的时间。”诚然,如果两个程序员差距不大的时候是有助于相互促进和提高的。但是如果差距过大,结对编程将变成水平较低的一方看着水平较高的一方进行编程,虽说对于水平较低的一方来说也有学习意义,但这时的结对编程是约等于个人编程的。
I.IV 问题4
如何根据实际开发选择合适团队模式?
关于第5章的团队和流程(的讲义)中有这么一段内容:“回过头想想学生在小学中学的学习过程, 虽然大家在一个班集体, 但是大部分工作都是以“非团队”的形式完成的。大家津津乐道的“团队精神”,“集体主义” 得到了多少锻炼?”中小学的班集体也不是没有好的团队,之所以称其为“非团队”,在我看来只是缺乏好的团队模式。而在软件开发过程中,又该如何选择合适的团队模式?
根据相关资料的阅读,在我看来,团队模式的选择,首先取决于这个团队的人员组成。要根据团队人员的性格、能力来进行模式的选择,性格上整体偏向沉稳还是活跃,能力上是平均水准还是有个别出众的。其次取决于用户对团队的开发需求,如果用户需要长期稳定bug少的软件,那么团队可以选择交响乐团模式;如果用户需要富有创意的软件,那么团队可以选择爵士乐模式······团队模式在开发过程也可能不会一成不变,会根据不同情况做出相应的调整,以适应不同需求。
I.V 问题5
敏捷流程是否万能?
关于第6章的敏捷流程中有这么一段内容:“软件项目中常常有一些比较艰难和底层的任务, 完成这些任务需要超过sprint 所计划的时间, 这时候我们怎么安排呢? 在我的经验中, 这些任务往往在短周期的迭代中得不到应有的重视, 一直拖着。 ”敏捷流程对于长期任务的完成上是有局限性的,但这类问题并不单单出在敏捷流程上,只是敏捷流程的sprint放大了这个问题。在我看来,敏捷流程的“万能”应该是限定在一定范围内的,它的“万能性”更多是体现在思想上,毕竟敏捷流程中应用了好几种开发的方法论。如果只是流于形式,敏捷流程很可能失去意义,变得不再“万能”。
II.冷知识和故事
为什么有win 7、win 8、win 10,却没有win 9?
自称为"cranbourne"的微软开发人员在社交新闻网站Reddit称:“内部传闻显示,早期测试结果显示,大量第三方开发者用下面这样的代码来判断Windows 95和98:if(version.StartsWith("Windows 9")) { /* 95 and 98 */ } else {”也就是说,开发人员在使用:“如果版本号始于Windows 9时,就将其视为Windows 95、98或其他。”这意味着,下一代操作系统如果被称为“Windows 9”,则可能被第三方软件识别为Windows 95或98。同时,第三方软件还可能无法正常运行。为避免出现这种不稳定因素,微软只好将下一代Windows命名为“Windows 10”。
https://zhidao.baidu.com/question/2076106787795468188.html
认识:代码应尽可能做到向前兼容。如果第三方考虑到之后版本会有Windows 9,都用if(version.StartsWith("Windows 95")||version.StartsWith("Windows 98"))来判断Windows 95和98的话,说不定现在市面上就有Windows 9了。
(为什么叫)Windows10,因为7 8 9,即seven eight(ate) nine,意为7把9吃掉了
为什么没有win9?其实是因为它去斩华雄了!(win9斩华雄)
(详见《旋风管家》第一季21话。微软看了这话,吓得跳过win9直接win10了)
part2:WordCount编程
I.Github项目地址
II.PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 60 | 45 |
| • Estimate | • 明确需求和其他因素,估计这个任务需要多少时间 | 60 | 45 |
| Development | 开发 | 1320 | 1215 |
| • Analysis | • 需求分析 (包括学习新技术) | 150 | 120 |
| • Design Spec | • 生成设计文档 | 90 | 45 |
| • Design Review | • 设计复审 | 90 | 90 |
| • Coding Standard | • 代码规范 (为目前的开发制定合适的规范) | 45 | 45 |
| • Design | • 具体设计 | 180 | 90 |
| • Coding | • 具体编码 | 315 | 390 |
| • Code Review | • 代码复审 | 135 | 105 |
| • Test | • 测试(自我测试,修改代码,提交修改) | 315 | 330 |
| Reporting | 报告 | 120 | 140 |
| • Test Repor | • 测试报告 | 40 | 60 |
| • Size Measurement | • 计算工作量 | 20 | 20 |
| • Postmortem & Process Improvement Plan | • 事后总结, 并提出过程改进计划 | 60 | 60 |
| 合计 | 1500 | 1400 |
III.解题思路描述
1、统计文件的字符数
通过FileReader按字符读取文件,并且过滤非ASCII码字符。
2、统计文件的单词总数
先统一将字母变为大写或小写,再通过正则表达式判断合法单词,并将单词和出现次数存储在map容器中。
3、统计文件的有效行数
通过BufferedReader按行读取文件,并通过正则表达式判断该行是否含非空白字符。
将每一行的字符串分离出来,再通过正则表达式判断每个字符串中是否含非空白字符。
4、统计文件中各单词的出现次数
通过sort函数和Comparator比较器对map容器中的单词进行字典序排序。
IV.代码规范制定链接
V.设计与实现过程
1、组织设计:
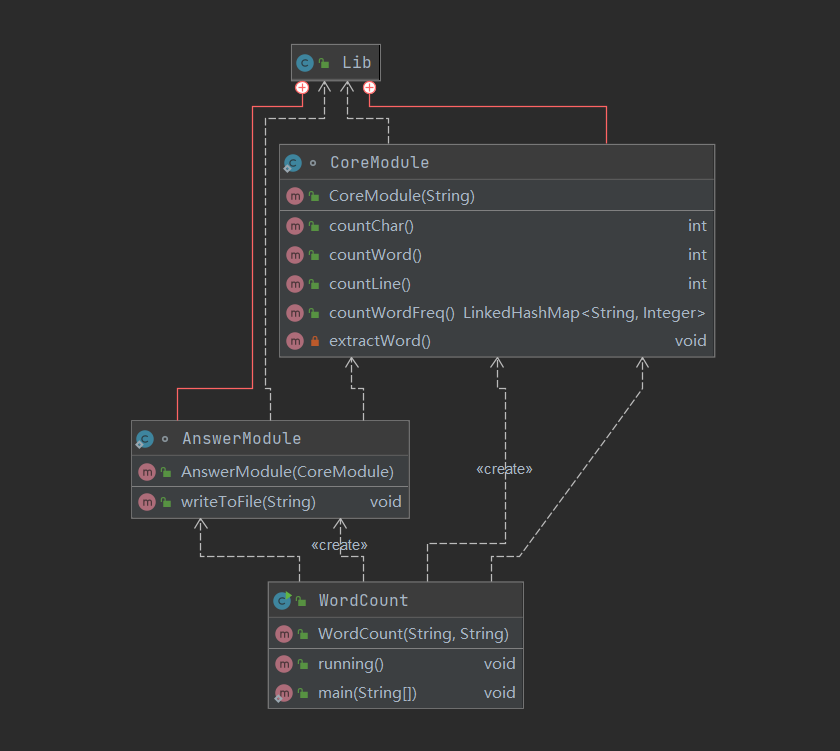
程序分为WordCount和Lib两部分。WordCount部分接收命令行参数,并通过创建Lib库的静态类对象去调用相应方法。Lib库里建立了静态类CoreModule和AnswerModule,其中CoreModule只负责计算和返回计算结果,AnswerModule只负责调用CoreModule得到计算结果将结果写入文件。CoreModule的4个功能可按不同顺序执行,并且可以很方便地独立出来进行单元测试。
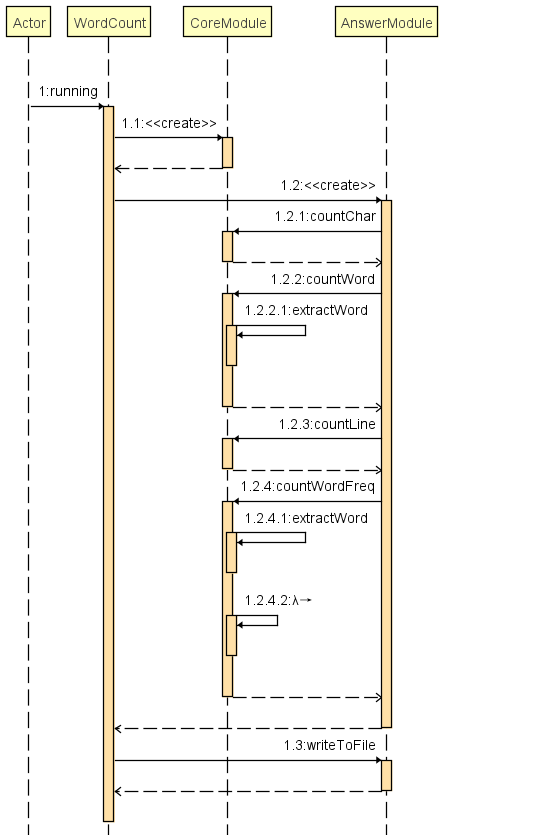
类层次结构图:
顺序图:
2、统计文件的字符数
通过BufferedReader按字符读取文件,若读取的字符编码在0~127之间则字符数+1。
BufferedReader bufferedReader = new BufferedReader(new FileReader(INPUT_FILE));
int fileChar;
int charNum = 0;
while((fileChar = bufferedReader.read()) != -1) {
if (fileChar <= 127) {
charNum++;
}
}
return charNum;
3、提取单词
先统一将文件中的字母变为小写,然后通过正则表达式[a-z]{4}[a-z0-9]*匹配合法单词,匹配成功的单词根据是否出现过进行不同的词频计算。
BufferedReader bufferedReader = new BufferedReader(new FileReader(INPUT_FILE));
StringBuilder strBuilder = new StringBuilder();
String fileStr;
while ((fileStr = bufferedReader.readLine()) != null) {
strBuilder.append(fileStr.toLowerCase()).append("
");
}
Matcher matcher = WORD_PATTERN.matcher(strBuilder.toString());
while(matcher.find()) {
if(WORD_FREQ.containsKey(matcher.group(0))) {
WORD_FREQ.put(matcher.group(0),(WORD_FREQ.get(matcher.group(0)) + 1));
} else {
WORD_FREQ.put(matcher.group(0),1);
}
}
4、统计文件的单词总数
累计各单词出现的次数,将结果返回。
int wordNum = 0;
for(int value : WORD_FREQ.values()) {
wordNum += value;
}
return wordNum;
5、统计文件的有效行数
通过BufferedReader按行读取文件读取,并通过正则表达式^.*[^s]+.*$判断该行是否含非空白字符。
BufferedReader bufferedReader = new BufferedReader(new FileReader(INPUT_FILE));
String lineStr;
int lineNum = 0;
while ((lineStr = bufferedReader.readLine()) != null) {
if(NON_BLACK_PATTERN.matcher(lineStr).matches()) {
lineNum++;
}
}
return lineNum;
但是BufferedReader的readLine()会把"
"作为行分隔符,而对于以"
"作为换行的文件来说"
"也属于一行当中的字符,所以只得对原方法进行调整。先通过FileInputStream读取整个文件字符串并将其中的"
"替换成空格,然后以"
"作为分隔符将文件字符串分割成字符串数组,再用正则表达式^.*[^s]+.*$判断数组中每个的字符串是否含非空白字符。(该commit由于超时已撤回,事后测试发现该程序才是正确的)
FileInputStream fileInputStream = new FileInputStream(INPUT_FILE);
int strSize = fileInputStream.available();
byte[] strBuffer = new byte[strSize];
//noinspection ResultOfMethodCallIgnored
fileInputStream.read(strBuffer);
String fileStr = new String(strBuffer,StandardCharsets.UTF_8);
String[] strArr = fileStr.replace("
"," ").split("
");
int lineNum = 0;
for(String str : strArr){
if(NON_BLACK_PATTERN.matcher(str).matches()) {
lineNum++;
}
}
6、统计文件中各单词的出现次数
借助ArrayList对Map里的单词及词频进行字典序排序,并将排在前10的单词及词频有序地put进入LinkedHashMap并返回。(LinkedHashMap保存了记录的插入顺序)
if(!isCountWordFreq) {
extractWord();
isCountWordFreq = true;
}
ArrayList<Map.Entry<String,Integer>> wordList = new ArrayList<>(WORD_FREQ.entrySet());
LinkedHashMap<String,Integer> mostFreqWord = new LinkedHashMap<>();
wordList.sort((map1,map2) -> {
if (map1.getValue().equals(map2.getValue())) {
return map1.getKey().compareTo(map2.getKey());
} else {
return map2.getValue().compareTo(map1.getValue());
}
});
int count = 0;
for(Map.Entry<String,Integer> mapping:wordList) {
mostFreqWord.put(mapping.getKey(),mapping.getValue());
count++;
if(count == WORD_FREQ_LIMIT) {
break;
}
}
return mostFreqWord;
VI.性能改进
项目性能测试的构造:
long startTime = System.currentTimeMillis();
for(int i=0;i<10000;i++) {
wordCount.running();
}
long endTime = System.currentTimeMillis();
System.out.println("程序运行时间:" + (endTime - startTime) + "ms");
改进思路:
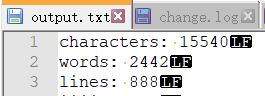
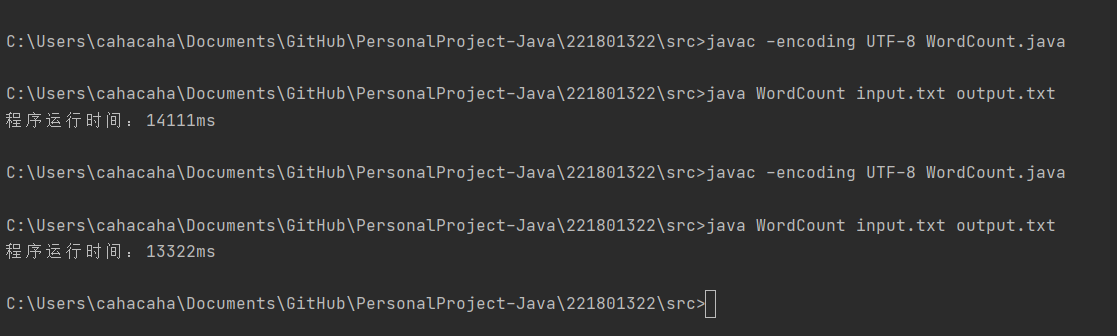
对于程序中的低级流FileReader和FileWriter,使用缓冲流BufferedReader和BufferedWriter进行封装,每次读到缓冲区满再一次性写出。可以加快输入输出速度,提高I/O效率。(对大文件读写时尤为有效)
不使用缓冲流读取大文件和使用缓冲流读取大文件的时间对比:
VII.单元测试
1、选取一段普通文本进行基本测试:

测试结果:
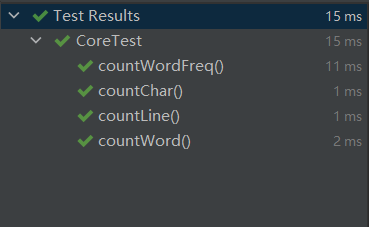
2、测试统计字符数功能:
测试数据:构造含空格、
、
、 、字母、数字、符号的字符串。
测试函数:
void countChar() throws IOException {
BufferedWriter bw = new BufferedWriter(new FileWriter("src/input1.txt"));
String str = "hello
123 [,.
@#]
%^ !~
";
bw.write(str);
bw.close();
Assertions.assertEquals(str.length(),core.countChar());
}
测试结果:
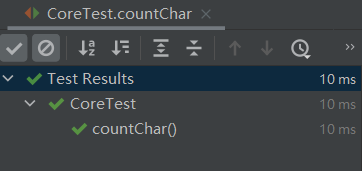
3、测试统计单词数功能:
测试数据:构造含1个hello、2个world、3个Good123的字符串。其中混杂着空白字符、其他符号和非法单词(如hel123)。
测试函数:
@Test
void countWord() throws IOException {
BufferedWriter bw = new BufferedWriter(new FileWriter("src/input1.txt"));
String str = "hello world
Good123]world Good123
Good123@#]hel123!~123Goo";
for(int i=0;i<100;i++){
bw.write(str);
}
bw.close();
Assertions.assertEquals(6,core.countWord());
}
测试结果:

4、测试统计词频功能:
测试数据:构造含10个单词的字符串,部分单词含多种大小写形式。其中混杂着空白字符、其他符号和非法单词(如hel123)。
测试函数:
@Test
void countWordFreq() throws IOException {
BufferedWriter bw = new BufferedWriter(new FileWriter("src/input1.txt"));
StringBuilder sb = new StringBuilder("helLo World
Good123]woRld goOd123
GooD123@#]hel123!~Goo");
sb.append("
aaaa daac19 aaab1 dacc19 aaab5 aaac19 aaac15
");
for(int i=0;i<100;i++) {
bw.write(sb.toString());
}
bw.close();
LinkedHashMap<String,Integer> expectedMap = new LinkedHashMap<>();
...
for(Map.Entry<String,Integer> entry : core.countWordFreq().entrySet()) {
int valueA = entry.getValue();
int valueE = expectedMap.get(entry.getKey());
Assertions.assertEquals(valueA,valueE);
}
}
测试结果:
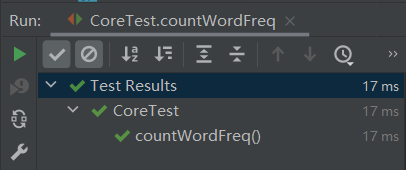
5、测试总结:
总代码覆盖率:

说明:类覆盖率和方法覆盖率均达到100%,行覆盖率由于使用try/catch进行处理导致一些损失。
VIII.异常处理说明
1、命令行参数不足的异常处理:
实现代码:
try {
if (args.length < 2) {
throw new Exception();
}
} catch (Exception e) {
System.out.println("命令行参数个数不足2个!");
e.printStackTrace();
return ;
}
对应场景:

2、文件I/O的异常处理:
本来是对IOException和FileNotFoundException分开处理,然后在IDEA编辑器的提醒下,将对两种异常的处理统一成对IOException进行处理。
对应场景:

IX.心路历程与收获
1、在实践过程中,发现单元测试特别是进行自动测试是很有意义的。在对代码进行小修小补之后,可以通过单元测试得知代码完整性是否被破坏,是否仍能完成基本功能。
2、学会使用在Git上完成代码的提交,感觉到了使用github进行代码管理时的方便快捷。
3、复习了java的相关知识,同时也学习了正则表达式的使用,感受到正则表达式在字符串处理上是十分简洁的。