变量可分为名义型变量、有序型变量或者连续型变量。名义型变量是没有顺序之分的类别变量,如糖尿病类型Diabetes(Type1、Type2),即使在数据中Type1编码为1而Type2编码为2,这也并不表示二者有序。有序变量表示一种顺序关系,而非数量关系,如病情S Status(poor、improved、excellent),显然病情为poor(较差)的病人的状态不如improved(病情好转)的病人,但我们并不知道相差多少。连续型变量可以呈现为某个范围内的任意值,并同时表示了顺序和数量,例如年龄,他能够表示14或者30这样的值以及期间的其他任意值,很清楚15岁的人比14岁的人年长1岁。
类别(名义型)变量和有序类别(有序型)变量在R中称为因子(factor)。因子在R中非常重要,它决定了数据的分析方式及如何进行视觉呈现。
函数factor()以一个整数向量的形式存储类别值,取值范围是[1...k](其中k是名义型变量中唯一值的个数),同时一个由字符串(原始值)组成的内部向量将映射到这些整数上,例如:
> diabetes<-c("Type1","Type2","Type1","Type2")
> diabetes<-factor(diabetes)
> diabetes
[1] Type1 Type2 Type1 Type2
Levels: Type1 Type2
语句diabetes<-factor(diabetes)将向量存储为(1,2,1,1),并在内部将其关联为1=Type1,和2=Type2(具体赋值顺序根据字母顺序而定)。针对向量diabetes 进行的任何分析都会将其作为名义型变量对待,并自动选择适合这一测量尺度的统计方法。
若果要表示有序向量,则需要为函数factor()指定参数ordered=TRUE。给定向量:
> status<-c("Poor","Improved","Excellent","Poor")
> status<-factor(status,ordered = T)
> status
[1] Poor Improved Excellent Poor
Levels: Excellent < Improved < Poor
语句status<-factor(status,ordered = T)将此向量编码为(3,2,1,3),并在内部将其关联为1=Excellent、2=Improved以及3=Poor。但这里对于字符型向量,因自水平默认以字母顺序创建,这对于因子status是有意义的,因为“Excellent”“Improved”“Poor”的排序方式恰好与逻辑顺序一致。如果“Poor”被编码为“Ailing”则顺序将为“Ailing”“Excellent”“Improved”,与逻辑不符;如果理想中的顺序是“Poor”“Improved”“Excellent”,则会出现类似问题。因此可以通过制定levels选项来覆盖默认排序。例如:
> status<-factor(status,ordered = T,levels=c("Poor","Improved","Excellent"))
> status
[1] Poor Improved Excellent Poor
Levels: Poor < Improved < Excellent
数值型变量可用levels和labels参数来编码成因子。如果男性编码被编码成1,女性被编码成2,则代码如下:
> sex<-c(1,2)
> sex<-factor(sex,levels=c(1,2),labels = c("Male","Female"))#注意标签的顺序必须与水平一致
> sex
[1] Male Female
Levels: Male Female
以下代码显示了普通因子与有序因子的不同是如何影响数据分析的
> patientID<-c(1,2,3,4)
> ge<-c(25,34,28,52)
> diabetes<-c("Type1","Type2","Type1","Type1")
> status<-c("Poor","Improved","Excellent","Poor")
> diabetes<-factor(diabetes)
> status<-factor(status,ordered = T)
> patientdata<-data.frame(patientID,age,diabetes,status)
> str(patientdata)#显示对象的结构
'data.frame': 4 obs. of 4 variables:
$ patientID: num 1 2 3 4
$ age : num 25 34 28 52
$ diabetes : Factor w/ 2 levels "Type1","Type2": 1 2 1 1
$ status : Ord.factor w/ 3 levels "Excellent"<"Improved"<..: 3 2 1 3
> summary(patientdata)#显示对象的统计概要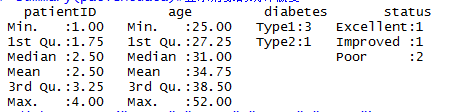
> diabetes2<-c("Type1","Type2","Type1","Type1")
> status2<-c("Poor","Improved","Excellent","Poor")
> patientdata2<-data.frame(patientID,age,diabetes2,status2)
> str(patientdata2)#显示对象的结构
'data.frame': 4 obs. of 4 variables:
$ patientID: num 1 2 3 4
$ age : num 25 34 28 52
$ diabetes2: Factor w/ 2 levels "Type1","Type2": 1 2 1 1
$ status2 : Factor w/ 3 levels "Excellent","Improved",..: 3 2 1 3
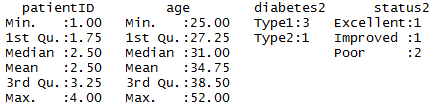
> summary(patientdata2)#显示对象的统计概要
> status<-factor(status,ordered = T,levels=c("Poor","Improved","Excellent"))
> patientdata<-data.frame(patientID,age,diabetes,status)
> str(patientdata)#显示对象的结构
'data.frame': 4 obs. of 4 variables:
$ patientID: num 1 2 3 4
$ age : num 25 34 28 52
$ diabetes : Factor w/ 2 levels "Type1","Type2": 1 2 1 1
$ status : Ord.factor w/ 3 levels "Poor"<"Improved"<..: 1 2 3 1
> summary(patientdata)#显示对象的统计概要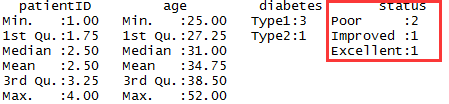
首先,以向量形式输入数据;然后,将diabetes和status分别指定为一个普通因子和一个有序型因子;最后,将数据合并为一个数据框。函数str(object)可以提供R中的某个对象(本例为数据框)的信息,它清楚的显示diabetes是一个因子,而status是一个有序型因子,以及此数据框在内部是如何进行编码的。函数summary()会区别对待各个变量,它显示了连续型变量age的最小值、最大值、均值和四分位数,并显示了类别型变量diabetes和status(各水平)的频数值。