JVM 内存共分为虚拟机栈、堆、方法区、程序计数器、本地方法栈五个部分。
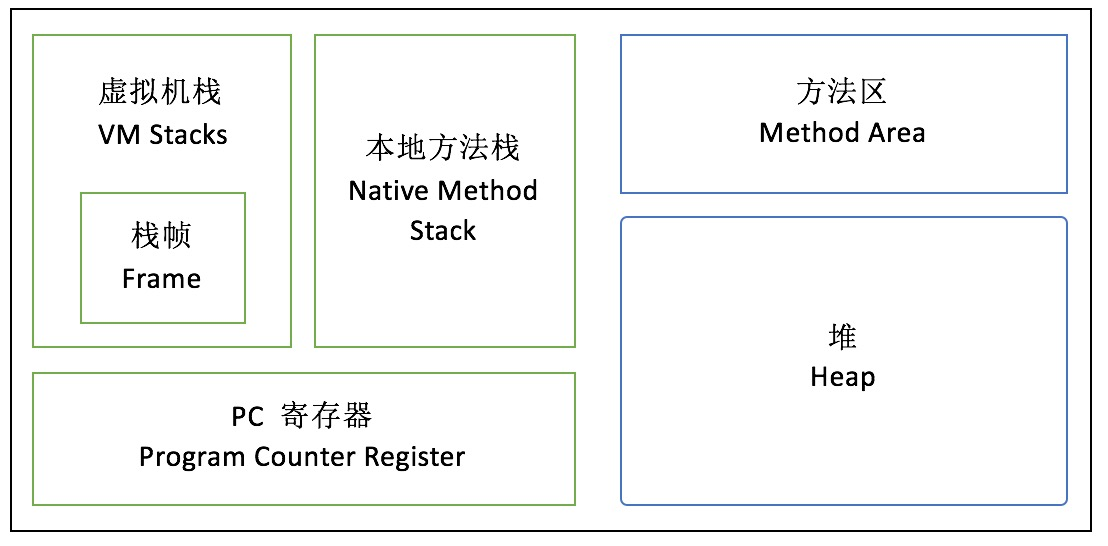
程序计数器(Program Counter Register): 是一块较小的内存空间,它可以看做是当前线程所执行的字节码的行号指示器。在虚拟机的概念里,字节码解释器工作时就是通过改变这个计数器的值来选取下一条需要执行的字节码指令,分支、循环、跳转、异常处理等基础功能都需要依赖这个计数器完成。
由于java虚拟机的多线程是通过多线程轮流切换并分配处理器执行时间的方式来实现的,在任何一个确定的时刻,一个处理器(对于多核处理器来说是一个内核)都只会执行一条线程中的指令。因此,为了线程切换后能恢复到正确的执行位置,每条线程多需要有一个独立的程序计数器,各条线程都需要有一个独立程序计数器,各条线程之间的计数器互不影响,独立存储,我们称这类存区域为"线程私有"的内存。
java虚拟机栈(Java Virtual Machine Stacks)线程私有的,它的生命周期与线程相同。虚拟机栈描述的是Java方法执行的内存模型:每个方法在执行的同时会创建一个栈帧(Stack Frame),栈帧是方法执行时的基础数据结构,用于存储局部变量表、操作数栈、动态链接、每一个方法执行的过程,就对应着一个栈帧在虚拟机栈中入栈到出栈的过程。这里简单说一下局部变量表,局部变量表存放了编译期可知的各种基本数据类型(boolean,byte,char,short,int,float,long,double)、对象引用(reference 类型,可能是指向对象的原始地址的应用指针,也可能是指向一个代表对象的句柄或其他于此对象相关的位置)和returnAddress类型(指向了一条字节码指令的地址).其中64位长度的long和double类型的数据会占用2个局部变量空间(slot),其余的数据类型只占用1个。局部变量表所需的内存空间在编译间完成分配,当进入一个方法时,这个方法需要栈帧中分配多大局部变量空间是完全确定的,在方法运行期间不会改变局部变量表的大小。注意:虚拟机栈会出现两种异常情况,如果线程请求的栈深度大于虚拟机所允许的深度,将抛出StackOverflowError异常,如果扩展时无法申请到足够的内存,就会抛出OutOfMeoryError异常。
本地方法栈(Native Method Stack):本地方法栈和虚拟机栈类似,虚拟机用到native方法。本地方法栈也会抛出StackOverflowError和OutOfMemoryError异常。当然也是线程私有的。
Java堆(Java Heap):是Java虚拟机所管理的内存最大的一块,java虚拟机是被所有线程共享的一块内存区域,在虚拟机启动时创建。GC收集也是主要针对java Heap上的数据进行收集。几乎所有的对象实例都在java heap上分配。如果堆中没有内存完成实例分配,并且堆也无法扩展时,将会抛出-Xmx和-Xms控制,通过-Xmx和-Xms控制.
方法区(Method Area):与java堆一样,是各个线程共享的内存区域,它用于存储内存已被虚拟机加载的类信息、常量、静态变量、即时编译器编译后的代码等数据。虽然Java虚拟机规范把方法区描述为堆的一个逻辑部分,但是它却又一个别名叫做Non-Heap(非堆),目的应该是与区分开来。在hotspot的实现中,方法区就是在堆中称为永久代的堆区域。几乎所有的对象/数组的内存空间都在堆上(有少部分在栈上)。在gc管理中,将虚拟机堆分为永久代、老年代、新生代。通过名字我们可以知道一个对象新建一般在新生代。经过几轮的gc。还存活的对象会被移到老年代。永久代用来保存类信息、代码段等几乎不会变的数据。堆中的所有数据是线程共享的。
- 新生代:应为gc具体实现的优化的原因。hotspot又将新生代划分为一个eden区和两个survivor区。每一次新生代gc时候。只用到一个eden区,一个survivor区。新生代一般的gc策略为mark-copy。
- 老年代:当新生代中的对象经过若干轮gc后还存活/或survisor在gc内存不够的时候。会把当前对象移动到老年代。老年代一般gc策略为mark-compact。
- 永久代:永久代一般可以不参与gc。应为其中保存的是一些代码/常量数据/类信息。在永久代gc。清楚的是类信息以及常量池。
当然从jdk1.7开始就java就已经打算去除永久代(Permanent Generation)代 了,当然还是保留了永久代了,通过-XX:Permsize,-XX:MaxPermsize来调节永久代的大小(从jdk1.8开始已经去掉了永久区,这两个参数已经没有用了)。jdk1.8用MetaSpace元空间代替Permanent Generation。下面我们看看具体的变化过程和区别:
其实,移除永久代的工作从JDK1.7就开始了。JDK1.7中,存储在永久代的部分数据就已经转移到了Java Heap或者是 Native Heap。但永久代仍存在于JDK1.7中,并没完全移除,譬如符号引用(Symbols)转移到了native heap;字面量(interned strings)转移到了java heap;类的静态变量(class statics)转移到了java heap,以下面的列子说明这个演变过程:
1 public class StringOomMock { 2 static String base = "string"; 3 public static void main(String[] args) { 4 List<String> list = new ArrayList<String>(); 5 for (int i=0;i< Integer.MAX_VALUE;i++){ 6 String str = base + base; 7 base = str; 8 list.add(str.intern()); 9 } 10 }
在jdk1.6:

出现了java.Lang.OutOfMemoryError:PermGen space 永久区出现异常。

jdk1.7已经java heap sapce 堆空间溢出,可见jdk1.7已经将字符串常量池移到java space中去了。但是还是存在永久代用来记录类相关的信息。
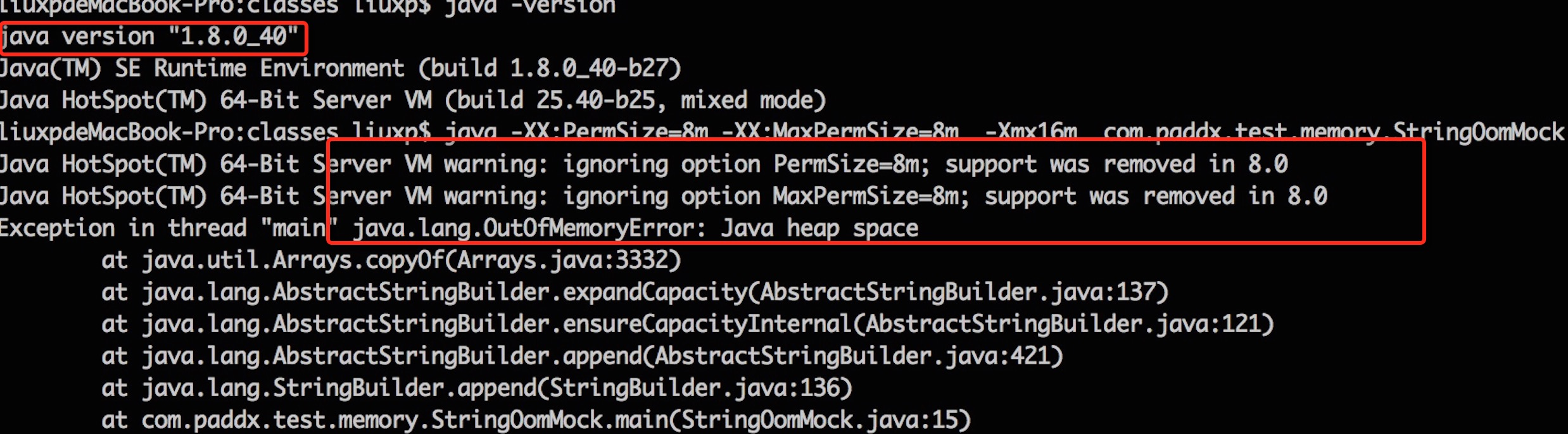
jdk1.8 也是java heap sapce 堆空间溢出,但是已经不支持PermSize,MaxPermSize参数,因为jdk1.8已经没有永久区了,取而代之的是MetaSpace元空间。
元空间的本质和永久代类似,都是对JVM规范中方法区的实现。不过元空间与永久代之间最大的区别在于:元空间并不在虚拟机中,而是使用本地内存。因此,默认情况下,元空间的大小仅受本地内存限制,但可以通过以下参数来指定元空间的大小:
-XX:MetaspaceSize,初始空间大小,达到该值就会触发垃圾收集进行类型卸载,同时GC会对该值进行调整:如果释放了大量的空间,就适当降低该值;如果释放了很少的空间,那么在不超过MaxMetaspaceSize时,适当提高该值。
-XX:MaxMetaspaceSize,最大空间,默认是没有限制的。
除了上面两个指定大小的选项以外,还有两个与 GC 相关的属性:
-XX:MinMetaspaceFreeRatio,在GC之后,最小的Metaspace剩余空间容量的百分比,减少为分配空间所导致的垃圾收集
-XX:MaxMetaspaceFreeRatio,在GC之后,最大的Metaspace剩余空间容量的百分比,减少为释放空间所导致的垃圾收集
我们执行一下这样的代码看看,类class信息是不是保留在元空间中:
1 public class JavaMethodAreaOOM { 2 3 public static void main(String[] args){ 4 while(true){ 5 Enhancer enhancer=new Enhancer(); 6 enhancer.setSuperclass(Test.class); 7 enhancer.setUseCache(false); 8 enhancer.setCallback(new MethodInterceptor() { 9 @Override 10 public Object intercept(Object obj, Method method, Object[] args, MethodProxy proxy) throws Throwable { 11 return proxy.invoke(obj,args); 12 } 13 }); 14 enhancer.create(); 15 } 16 17 } 18 19 20 } 21
jdk1.8方法区溢出爆出:Metaspace空间异常。
1 Caused by: java.lang.OutOfMemoryError: Metaspace 2 at java.lang.ClassLoader.defineClass1(Native Method) 3 at java.lang.ClassLoader.defineClass(ClassLoader.java:763) 4 ... 8 more
总结一下:
通过上面分析,大家应该大致了解了 JVM 的内存划分,也清楚了 JDK 8 中永久代向元空间的转换。不过大家应该都有一个疑问,就是为什么要做这个转换?所以,最后给大家总结以下几点原因:
1.字符串存在永久代中容易存在性能问题和内存溢出
2、类及方法的信息等比较难确定其大小,因此对于永久代的大小指定比较困难,太小容易出现永久代溢出,太大导致内存浪费。
3.永久代会为GC收集带来额外的复杂度,且回收效率低。
基于字符串常量池的问题,还可以引申出一个更有意思的印象:
1 public class RuntimeConstantPoolOOM { 2 public static void main(String[] args){ 3 String str1=new StringBuilder("计算机").append("软件").toString(); 4 System.out.println(str1.intern()==str1); 5 String str2=new StringBuilder("ja").append("va").toString(); 6 System.out.println(str2.intern()==str2); 7 } 8 }
jdk.16中运行会得到两个false,在jdk1.7和jdk1.8中会得到一个true,一个false.产生差异的原因是:在jdk1.6中,intern()方法会把首次遇到的字符串实例复制到永久代中,返回的也是一个永久代中这个字符串实例的引用,而由StringBuilder()创建的字符串实例在java堆上,所以必然不是同一个引用,将放回false.
jdk1.7和jdk1.8的inern()不会在复制实例,只是在常量池中记录首次出现的实例引用,因此inern()返回的引用和StringBu
ilder()创建的那个字符串实例是同一个。对str2比较返回false是因为"java"这个字符串在执行.toString之前已经在字符串常量池中,所以str2.inern()返回的字符串常量池中的引用,而str2则是堆中实列引用。所以返回false。
参考书籍:jvm虚拟机
关于字符串常量池、常量池、运行时常量池的区别看这篇博客:https://blog.csdn.net/zm13007310400/article/details/77534349