环境
虚拟机:VMware 10
Linux版本:CentOS-6.5-x86_64
客户端:Xshell4
FTP:Xftp4
jdk1.8
scala-2.10.4(依赖jdk1.8)
spark-1.6
一、output operation算子
1、foreachRDD:必须对抽取出来的RDD执行action类算子,代码才能执行。
(1.1)foreachRDD可以拿到DStream中的RDD
(1.2)foreachRDD call方法内,拿到的RDD的算子外的代码在Driver端执行。可以做到动态改变广播变量
package com.wjy.ss; import java.util.Arrays; import org.apache.spark.SparkConf; import org.apache.spark.SparkContext; import org.apache.spark.api.java.JavaPairRDD; import org.apache.spark.api.java.JavaSparkContext; import org.apache.spark.api.java.function.FlatMapFunction; import org.apache.spark.api.java.function.Function2; import org.apache.spark.api.java.function.PairFunction; import org.apache.spark.api.java.function.VoidFunction; import org.apache.spark.broadcast.Broadcast; import org.apache.spark.streaming.Durations; import org.apache.spark.streaming.api.java.JavaDStream; import org.apache.spark.streaming.api.java.JavaPairDStream; import org.apache.spark.streaming.api.java.JavaReceiverInputDStream; import org.apache.spark.streaming.api.java.JavaStreamingContext; import scala.Tuple2; public class SparkStreamingTest { public static void main(String[] args) { SparkConf conf = new SparkConf().setMaster("local[2]").setAppName("SparkStreamingTest"); JavaSparkContext sc = new JavaSparkContext(conf); sc.setLogLevel("WARN");//设置日志级别 不打印一堆无用的日志 //创建JavaStreamingContext 批次间隔为5秒 JavaStreamingContext jsc = new JavaStreamingContext(sc,Durations.seconds(5)); //监听134.32.123.101 9999端口 获取文本socket流 JavaReceiverInputDStream<String> socketTextStream = jsc.socketTextStream("134.32.123.101", 9999); //接下来进行wordcount JavaDStream<String> words = socketTextStream.flatMap(new FlatMapFunction<String, String>() { private static final long serialVersionUID = 1L; @Override public Iterable<String> call(String line) throws Exception { return Arrays.asList(line.split(" ")); } }); JavaPairDStream<String, Integer> pairWords = words.mapToPair(new PairFunction<String, String, Integer>() { private static final long serialVersionUID = 1L; @Override public Tuple2<String, Integer> call(String word) throws Exception { return new Tuple2<String, Integer>(word,1); } }); JavaPairDStream<String, Integer> reduceByKey = pairWords.reduceByKey(new Function2<Integer, Integer, Integer>() { private static final long serialVersionUID = 1L; @Override public Integer call(Integer v1, Integer v2) throws Exception { return v1+v2; } }); //print()可以加参数 表示多少时间打印一次 上面的transform只有调到print才会执行 //默认打印在此 DStream 中生成的每个 RDD 的前十个元素。加参数前num个元素 //reduceByKey.print(); /** * foreachRDD 可以拿到DStream中的RDD ,对拿到的RDD可以使用RDD的transformation类算子转换,要对拿到的RDD使用action算子触发执行,否则,foreachRDD不会执行。 * foreachRDD 中call方法内,拿到的RDD的算子外,代码是在Driver端执行。可以使用这个算子实现动态改变广播变量。 * */ reduceByKey.foreachRDD(new VoidFunction<JavaPairRDD<String,Integer>>() { private static final long serialVersionUID = 1L; @Override public void call(JavaPairRDD<String, Integer> rdd) throws Exception { //Driver端执行 System.out.println("Driver ......."); //获取SparkContext SparkContext context = rdd.context(); //创建JavaSparkContext JavaSparkContext javaSparkContext = new JavaSparkContext(context); //广播变量 这里可以读取一个文件 文件内容可变 就达到了动态改变广播变量的目的 Broadcast<String> broadcast = javaSparkContext.broadcast("hello wjy"); String value = broadcast.value(); System.out.println(value); JavaPairRDD<String, Integer> mapToPair = rdd.mapToPair(new PairFunction<Tuple2<String,Integer>, String,Integer>() { private static final long serialVersionUID = 1L; @Override public Tuple2<String, Integer> call(Tuple2<String, Integer> tuple) throws Exception { System.out.println("Executor ......."); return new Tuple2<String, Integer>(tuple._1+"~",tuple._2); } }); mapToPair.foreach(new VoidFunction<Tuple2<String,Integer>>() { private static final long serialVersionUID = 1L; @Override public void call(Tuple2<String, Integer> arg0) throws Exception { System.out.println(arg0); } }); } }); /* * * 执行结果: Driver ....... hello wjy Driver ....... hello wjy 19/04/22 17:26:46 WARN BlockManager: Block input-0-1555925206600 replicated to only 0 peer(s) instead of 1 peers 19/04/22 17:26:47 WARN BlockManager: Block input-0-1555925206800 replicated to only 0 peer(s) instead of 1 peers 19/04/22 17:26:47 WARN BlockManager: Block input-0-1555925207200 replicated to only 0 peer(s) instead of 1 peers Driver ....... hello wjy Executor ....... (ee~,1) Executor ....... (aa~,1) Executor ....... (ll~,1) Executor ....... (gg~,1) Executor ....... (dd~,1) Executor ....... (hh~,1) Executor ....... (wjy~,1) Executor ....... (kk~,1) Executor ....... (jj~,1) Executor ....... (ii~,1) Executor ....... (hello~,31) Executor ....... (tt~,1) Executor ....... (ff~,1) Executor ....... (bb~,1) Executor ....... (world~,17) Executor ....... (cc~,1) Driver ....... hello wjy */ //启动 jsc.start(); //监控:等待中断 jsc.awaitTermination(); //这里stop不会执行 我们在实际应用中根据触发条件执行 比如监控某个文件删除后就执行停止动作 jsc.stop(); } }
2、print
print()默认打印在此 DStream 中生成的每个 RDD 的前十个元素,print(num)可以加参数 打印前num个元素
3、saveAsTextFiles 、saveAsObjectFiles、saveAsHadoopFiles
package com.wjy.ss; import java.util.Arrays; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapred.TextOutputFormat; import org.apache.spark.SparkConf; import org.apache.spark.api.java.function.FlatMapFunction; import org.apache.spark.api.java.function.PairFunction; import org.apache.spark.streaming.Durations; import org.apache.spark.streaming.api.java.JavaDStream; import org.apache.spark.streaming.api.java.JavaPairDStream; import org.apache.spark.streaming.api.java.JavaStreamingContext; import org.apache.spark.streaming.dstream.DStream; import scala.Tuple2; /** * saveAsTextFiles(prefix, [suffix]): * 将此DStream的内容另存为文本文件。每批次数据产生的文件名称格式基于:prefix和suffix: "prefix-TIME_IN_MS[.suffix]". * * 注意: * saveAsTextFile是调用saveAsHadoopFile实现的 * spark中普通rdd可以直接只用saveAsTextFile(path)的方式,保存到本地,但是此时DStream的只有saveAsTextFiles()方法,没有传入路径的方法, * 其参数只有prefix, suffix * 其实:DStream中的saveAsTextFiles方法中又调用了rdd中的saveAsTextFile方法,我们需要将path包含在prefix中 * */ public class Operate_saveAsTextFiles { public static void main(String[] args) { SparkConf conf = new SparkConf().setMaster("local[2]").setAppName("Operate_saveAsTextFiles"); //创建JavaStreamingContext方式二 JavaStreamingContext jsc = new JavaStreamingContext(conf,Durations.seconds(5)); //监控本地目录data 监控该目录下文件原子性变化 监控不到文件内容变化 JavaDStream<String> textFileStream = jsc.textFileStream("./data1"); JavaDStream<String> flatmap = textFileStream.flatMap(new FlatMapFunction<String, String>() { private static final long serialVersionUID = 1L; @Override public Iterable<String> call(String line) throws Exception { return Arrays.asList(line.split(" ")); } }); //JavaDStream转换成DStream DStream<String> dstream = flatmap.dstream(); //保存在当前路径中savedata路径下,以prefix开头,以suffix结尾的文件。 dstream.saveAsTextFiles(".\savedata\mydate", "aaaa"); /* * saveAsObjectFiles(prefix, [suffix]): * 将此Dstream的内容保存为序列化的java 对象SequenceFiles , * 每批次数据产生的文件名称格式基于:prefix和suffix: "prefix-TIME_IN_MS[.suffix]". */ //保存在当前路径中savedata路径下,以prefix开头,以suffix结尾的文件。 //flatmap.dstream().saveAsObjectFiles(".\savedata\prefix", "suffix"); /* * saveAsHadoopFiles(prefix, [suffix]): * 将此DStream的内容另存为Hadoop文件。每批次数据产生的文件名称格式基于:prefix和suffix: "prefix-TIME_IN_MS[.suffix]". */ JavaPairDStream<String, Integer> mapToPair = flatmap.mapToPair(new PairFunction<String, String, Integer>() { private static final long serialVersionUID = 1L; public Tuple2<String, Integer> call(String t) throws Exception { return new Tuple2<String, Integer>(t.trim(), 1); } }); //存hdfs上路径示例: // mapToPair.saveAsHadoopFiles("hdfs://node1:9000/log/prefix", "suffix", Text.class, IntWritable.class, TextOutputFormat.class); //存本地路径示例: // mapToPair.saveAsHadoopFiles(".\savedata\prefix", "suffix", Text.class, IntWritable.class, TextOutputFormat.class); //也可以这样写: mapToPair.saveAsHadoopFiles("./savedata/prefix", "suffix", Text.class, IntWritable.class, TextOutputFormat.class); jsc.start(); jsc.awaitTermination(); jsc.stop(); } }
二、transformation类算子
1、transform
(1.1)对Dstream做RDD到RDD的任意操作。
(1.2)transform call方法内,在拿到的RDD的Transformation类算子外 代码是在Driver端执行的,可以使用transform做到动态改变广播变量
代码示例:
package com.wjy.ss; import org.apache.spark.SparkConf; import org.apache.spark.api.java.JavaRDD; import org.apache.spark.api.java.function.Function; import org.apache.spark.api.java.function.VoidFunction; import org.apache.spark.streaming.Durations; import org.apache.spark.streaming.api.java.JavaDStream; import org.apache.spark.streaming.api.java.JavaStreamingContext; public class Operate_transform { public static void main(String[] args) { SparkConf conf = new SparkConf().setMaster("local").setAppName("Operate_transform"); JavaStreamingContext jsc = new JavaStreamingContext(conf,Durations.seconds(5)); JavaDStream<String> textFileStream = jsc.textFileStream("./data1"); textFileStream.transform(new Function<JavaRDD<String>, JavaRDD<String>>() { private static final long serialVersionUID = 1L; @Override public JavaRDD<String> call(JavaRDD<String> rdd) throws Exception { rdd.foreach(new VoidFunction<String>() { private static final long serialVersionUID = 1L; @Override public void call(String t) throws Exception { System.out.println("*****************"+t); } }); return rdd; } }).print();; jsc.start(); jsc.awaitTermination(); jsc.close(); } }
2、updateStateByKey
(1)为SparkStreaming中每一个Key维护一份state状态,state类型可以是任意类型的,可以是一个自定义的对象,更新函数也可以是自定义的。
(2)通过更新函数对该key的状态不断更新,对于每个新的batch而言,SparkStreaming会在使用updateStateByKey的时候为已经存在的key进行state的状态更新。
(3)使用到updateStateByKey要开启checkpoint机制和功能,两种方式:
(3.1)SparkContext.setCheckpointDir..
(3.2)StreamingContext.checkpoint(....)
(4)多久向checkpoint中维护状态
(4.1)如果batchInterval设置的时间小于10秒,那么10秒写入磁盘一份。
(4.2)如果batchInterval设置的时间大于10秒,那么就会batchInterval时间间隔写入磁盘一份。
代码示例:
package com.wjy.ss; import java.util.Arrays; import java.util.List; import org.apache.spark.SparkConf; import org.apache.spark.api.java.function.FlatMapFunction; import org.apache.spark.api.java.function.Function2; import org.apache.spark.api.java.function.PairFunction; import org.apache.spark.streaming.Durations; import org.apache.spark.streaming.api.java.JavaDStream; import org.apache.spark.streaming.api.java.JavaPairDStream; import org.apache.spark.streaming.api.java.JavaStreamingContext; import scala.Tuple2; import com.google.common.base.Optional; /** * updateStateByKey: * 返回一个新的“状态”Dstream,通过给定的func来更新之前的每个状态的key对应的value值,这也可以用于维护key的任意状态数据。 * 注意:作用在(K,V)格式的DStream上 * * updateStateByKey的主要功能: * 1、Spark Streaming中为每一个Key维护一份state状态,state类型可以是任意类型的, 可以是一个自定义的对象,那么更新函数也可以是自定义的。 * 2、通过更新函数对该key的状态不断更新,对于每个新的batch而言,Spark Streaming会在使用updateStateByKey的时候为已经存在的key进行 * state的状态更新 * (对于每个新出现的key,会同样的执行state的更新函数操作), * 如果要不断的更新每个key的state,就一定涉及到了状态的保存和容错,这个时候就需要开启checkpoint机制和功能 * @author root * */ public class Operate_updateStateByKey { public static void main(String[] args) { SparkConf conf = new SparkConf().setMaster("local").setAppName("Operate_updateStateByKey"); JavaStreamingContext jsc = new JavaStreamingContext(conf,Durations.seconds(5)); //设置checkpoint jsc.checkpoint("./checkpoint"); JavaDStream<String> textFileStream = jsc.textFileStream("./data1"); /** * 实现一个累加统计word的功能 */ JavaPairDStream<String, Integer> mapToPair = textFileStream.flatMap(new FlatMapFunction<String, String>() { private static final long serialVersionUID = 1L; @Override public Iterable<String> call(String line) throws Exception { return Arrays.asList(line.split(" ")); } }).mapToPair(new PairFunction<String, String, Integer>() { private static final long serialVersionUID = 1L; @Override public Tuple2<String, Integer> call(String word) throws Exception { return new Tuple2<String, Integer>(word.trim(),1); } }); JavaPairDStream<String, Integer> updateStateByKey = mapToPair.updateStateByKey(new Function2<List<Integer>, Optional<Integer>, Optional<Integer>>() { private static final long serialVersionUID = 1L; /** * values:经过分组最后 这个key所对应的value [1,1,1,1,1] * state:这个key在本次之前之前的状态 */ @Override public Optional<Integer> call(List<Integer> values, Optional<Integer> state) throws Exception { Integer updateValue = 0; if (state.isPresent()) { updateValue = state.get(); } for (Integer t : values) { updateValue += t; } return Optional.of(updateValue); } }); updateStateByKey.print(); jsc.start(); jsc.awaitTermination(); jsc.stop(); } }
3、reduceByKeyAndWindow
(3.1)窗口操作
窗口操作理解图一:
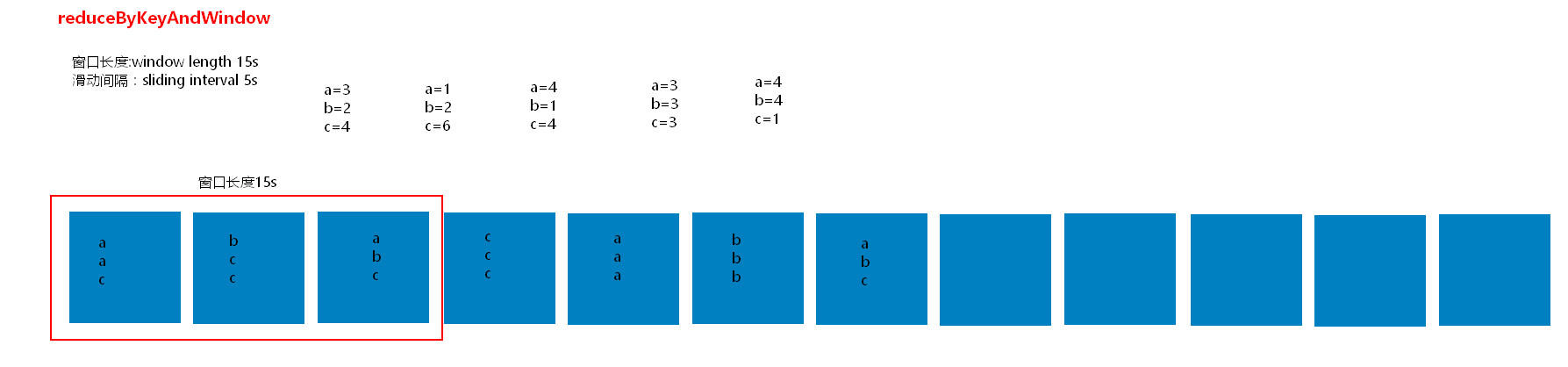
(3.1.1)每个滑动间隔 计算窗口长度内批次组成的DStream;
(3.1.2)窗口长度:window length;
(3.1.3)滑动间隔:sliding interval;
(3.1.4)普通机制不用设置checkpoint,优化机制需要设置checkpoint;
窗口操作理解图二:
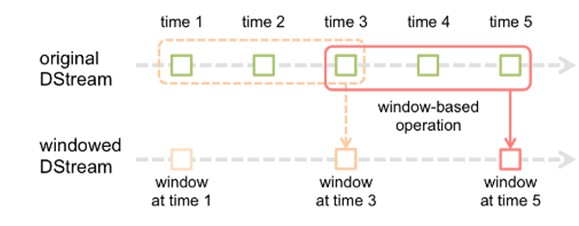
假设每隔5s 1个batch,上图中窗口长度为15s,窗口滑动间隔10s。
窗口长度和滑动间隔必须是batchInterval的整数倍,如果不是整数倍会检测报错。
代码示例:
package com.wjy.ss; import java.util.Arrays; import org.apache.spark.SparkConf; import org.apache.spark.api.java.function.FlatMapFunction; import org.apache.spark.api.java.function.Function2; import org.apache.spark.api.java.function.PairFunction; import org.apache.spark.streaming.Durations; import org.apache.spark.streaming.api.java.JavaDStream; import org.apache.spark.streaming.api.java.JavaPairDStream; import org.apache.spark.streaming.api.java.JavaStreamingContext; import scala.Tuple2; /** * reduceByWindow(func, windowLength, slideInterval): * 通过使用func在滑动间隔内通过流中的元素聚合创建返回一个新的单元素流。该函数是相关联的,以便它可以并行计算。 * * 窗口长度(windowLength):窗口的持续时间 * 滑动间隔(slideInterval):执行窗口操作的间隔 * * @author root * */ public class Operate_reduceByWindow { public static void main(String[] args) { SparkConf conf = new SparkConf().setMaster("local").setAppName("Operate_reduceByWindow"); JavaStreamingContext jsc = new JavaStreamingContext(conf,Durations.seconds(5)); JavaDStream<String> textFileStream = jsc.textFileStream("./data1"); JavaPairDStream<String, Integer> mapToPair = textFileStream.flatMap(new FlatMapFunction<String, String>() { private static final long serialVersionUID = 1L; @Override public Iterable<String> call(String line) throws Exception { return Arrays.asList(line.split(" ")); } }).mapToPair(new PairFunction<String, String, Integer>() { private static final long serialVersionUID = 1L; @Override public Tuple2<String, Integer> call(String word) throws Exception { return new Tuple2<String, Integer>(word.trim(),1); } }); JavaPairDStream<String, Integer> reduceByKeyAndWindow = mapToPair.reduceByKeyAndWindow(new Function2<Integer,Integer,Integer>(){ private static final long serialVersionUID = 1L; @Override public Integer call(Integer v1, Integer v2) throws Exception { return v1+v2; }}, Durations.seconds(15), Durations.seconds(5)); reduceByKeyAndWindow.print(); jsc.start(); jsc.awaitTermination(); jsc.stop(); } }
(3.2)优化后的window窗口操作示意图:
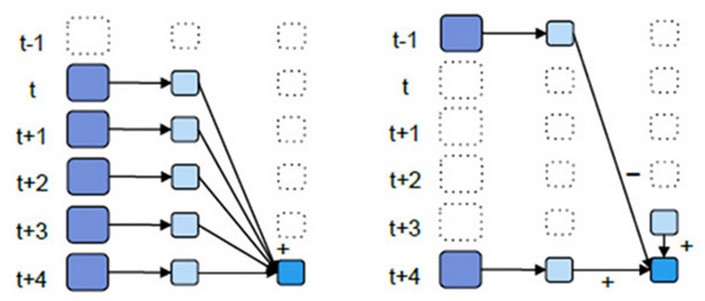
优化:只计算新加进来的批次(加)和出去的批次(减):
优化后的window操作要保存状态所以要设置checkpoint路径,没有优化的window操作可以不设置checkpoint路径。
示例代码:
package com.wjy.ss; import java.util.Arrays; import org.apache.spark.SparkConf; import org.apache.spark.api.java.function.FlatMapFunction; import org.apache.spark.api.java.function.Function2; import org.apache.spark.api.java.function.PairFunction; import org.apache.spark.streaming.Durations; import org.apache.spark.streaming.api.java.JavaDStream; import org.apache.spark.streaming.api.java.JavaPairDStream; import org.apache.spark.streaming.api.java.JavaStreamingContext; import scala.Tuple2; /** * reduceByKeyAndWindow(func, invFunc, windowLength, slideInterval, [numTasks]): * * 窗口长度(windowLength):窗口的持续时间 * 滑动间隔(slideInterval):执行窗口操作的间隔 * * 这是比上一个reduceByKeyAndWindow()更有效的版本, * 根据上一个窗口的reduce value来增量地计算每个窗口的当前的reduce value值, * 这是通过处理进入滑动窗口的新数据,以及“可逆的处理”离开窗口的旧数据来完成的。 * 一个例子是当窗口滑动时,“添加”和“减少”key的数量。 * 然而,它仅适用于“可逆的reduce 函数”,即具有相应“可逆的reduce”功能的reduce函数(作为参数invFunc)。 * 像在reduceByKeyAndWindow中,reduce task的数量可以通过可选参数进行配置。 * 请注意,使用此操作必须启用 checkpointing 。 * * 以上的意思就是 传一个参数的reduceByKeyAndWindow每次计算包含多个批次,每次都会从新计算。造成效率比较低,因为存在重复计算数据的情况 * 传二个参数的reduceByKeyAndWindow 是基于上次计算过的结果,计算每次key的结果,可以画图示意。 * @author root * */ public class Operate_reduceByKeyAndWindow_2 { public static void main(String[] args) { SparkConf conf = new SparkConf().setMaster("local").setAppName("Operate_reduceByKeyAndWindow_2"); JavaStreamingContext jsc = new JavaStreamingContext(conf,Durations.seconds(5)); jsc.checkpoint("./checkpoint"); JavaDStream<String> textFileStream = jsc.textFileStream("./data1"); JavaPairDStream<String, Integer> mapToPair = textFileStream.flatMap(new FlatMapFunction<String, String>() { private static final long serialVersionUID = 1L; @Override public Iterable<String> call(String line) throws Exception { return Arrays.asList(line.split(" ")); } }).mapToPair(new PairFunction<String, String, Integer>() { private static final long serialVersionUID = 1L; @Override public Tuple2<String, Integer> call(String word) throws Exception { return new Tuple2<String, Integer>(word.trim(),1); } }); /* * 第一个Function2函数用于相加新进入窗口的那批次数据 * 第二个Function2函数用于减去刚离开窗口的那批次数据 */ JavaPairDStream<String, Integer> reduceByKeyAndWindow = mapToPair.reduceByKeyAndWindow(new Function2<Integer, Integer, Integer>(){ private static final long serialVersionUID = 1L; /** * 这里的v1是指上一个所有的状态的key的value值(如果有出去的某一批次值,v1就是下面第二个函数返回的值),v2为本次的读取进来的值 * 返回值是下面函数的入参v1 */ @Override public Integer call(Integer v1, Integer v2) throws Exception { System.out.println("***********v1*************"+v1); System.out.println("***********v2*************"+v2); return v1+v2; } }, new Function2<Integer, Integer, Integer>(){ private static final long serialVersionUID = 1L; /** * 这里的这个第二个参数的Function2是在windowLength时间后才开始执行,v1是上面一个函数刚刚加上最近读取过来的key的value值的最新值, * v2是窗口滑动后,滑动间隔中出去的那一批值 * 返回的值又是上面函数的v1 的输入值 */ @Override public Integer call(Integer v1, Integer v2) throws Exception { System.out.println("^^^^^^^^^^^v1^^^^^^^^^^^^^"+v1); System.out.println("^^^^^^^^^^^v2^^^^^^^^^^^^^"+v2); return v1-v2; } }, Durations.seconds(15), Durations.seconds(5)); reduceByKeyAndWindow.print(); jsc.start(); jsc.awaitTermination(); jsc.stop(); } }
参考:
Spark