环境
虚拟机:VMware 10
Linux版本:CentOS-6.5-x86_64
客户端:Xshell4
FTP:Xftp4
jdk1.8
scala-2.10.4(依赖jdk1.8)
spark-1.6
一、SparkStreaming简介
SparkStreaming是流式处理框架,是Spark API的扩展,支持可扩展、高吞吐量、容错的实时数据流处理,实时数据的来源可以是:Kafka, Flume, Twitter, ZeroMQ或者TCP sockets,并且可以使用高级功能的复杂算子来处理流数据。例如:map,reduce,join,window 。最终,处理后的数据可以存放在文件系统,数据库等,方便实时展现。
二、SparkStreaming与Storm的区别
1、Storm是纯实时的流式处理框架(扶梯),SparkStreaming是准实时的处理框架(微批处理-电梯)。因为微批处理,SparkStreaming的吞吐量比Storm要高。
2、Storm 的事务机制要比SparkStreaming的要完善。
3、Storm支持动态资源调度。(spark1.2开始和之后也支持)
4、SparkStreaming擅长复杂的业务处理,Storm不擅长复杂的业务处理,擅长简单的汇总型计算。
整体而言速度比storm要快,目前新项目一般选择SparkStreaming多一些,具体选择还要看应用场景
三、SparkStreaming初始
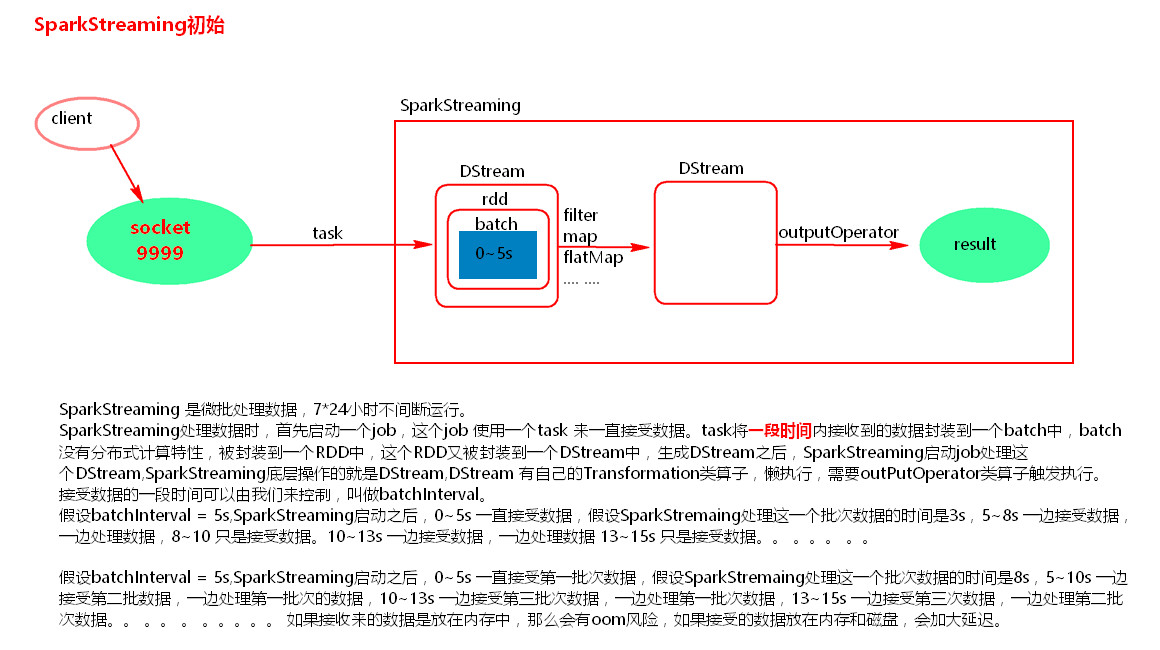
SparkStreaming示例代码:
package com.wjy.ss; import java.util.Arrays; import org.apache.spark.SparkConf; import org.apache.spark.api.java.JavaSparkContext; import org.apache.spark.api.java.function.FlatMapFunction; import org.apache.spark.api.java.function.Function2; import org.apache.spark.api.java.function.PairFunction; import org.apache.spark.streaming.Durations; import org.apache.spark.streaming.api.java.JavaDStream; import org.apache.spark.streaming.api.java.JavaPairDStream; import org.apache.spark.streaming.api.java.JavaReceiverInputDStream; import org.apache.spark.streaming.api.java.JavaStreamingContext; import scala.Tuple2; public class SparkStreamingTest { public static void main(String[] args) { SparkConf conf = new SparkConf().setMaster("local[2]").setAppName("SparkStreamingTest"); JavaSparkContext sc = new JavaSparkContext(conf); sc.setLogLevel("WARN");//设置日志级别 不打印一堆无用的日志 //创建JavaStreamingContext 批次间隔为5秒 JavaStreamingContext jsc = new JavaStreamingContext(sc,Durations.seconds(5)); //监听134.32.123.101 9999端口 获取文本socket流 JavaReceiverInputDStream<String> socketTextStream = jsc.socketTextStream("134.32.123.101", 9999); //接下来进行wordcount JavaDStream<String> words = socketTextStream.flatMap(new FlatMapFunction<String, String>() { private static final long serialVersionUID = 1L; @Override public Iterable<String> call(String line) throws Exception { return Arrays.asList(line.split(" ")); } }); JavaPairDStream<String, Integer> pairWords = words.mapToPair(new PairFunction<String, String, Integer>() { private static final long serialVersionUID = 1L; @Override public Tuple2<String, Integer> call(String word) throws Exception { return new Tuple2<String, Integer>(word,1); } }); JavaPairDStream<String, Integer> reduceByKey = pairWords.reduceByKey(new Function2<Integer, Integer, Integer>() { private static final long serialVersionUID = 1L; @Override public Integer call(Integer v1, Integer v2) throws Exception { return v1+v2; } }); //print()可以加参数 默认打印在此 DStream 中生成的每个 RDD 的前十个元素。加参数print(num)前num个元素 reduceByKey.print(); /* * ------------------------------------------- Time: 1555921465000 ms ------------------------------------------- 19/04/22 17:01:38 WARN BlockManager: Block input-0-1555923698400 replicated to only 0 peer(s) instead of 1 peers 19/04/22 17:01:38 WARN BlockManager: Block input-0-1555923698600 replicated to only 0 peer(s) instead of 1 peers ------------------------------------------- Time: 1555921470000 ms ------------------------------------------- (ee,1) (aa,1) (gg,1) (dd,1) (hh,1) (wjy,1) (kk,1) (jj,1) (ii,1) (hello,14) ... ------------------------------------------- Time: 1555921475000 ms ------------------------------------------- (ll,1) (hello,1) */ //启动 jsc.start(); //监控:等待中断 jsc.awaitTermination(); //这里stop不会执行 我们在实际应用中根据触发条件执行 比如监控某个文件删除后就执行停止动作 jsc.stop(); } }
以上使用print用来展示查看JavaPairDStream中数据,这是本机测试,实际应用是不会使用print的,这里需要我们通过foreachRDD来进行下一步的逻辑处理和触发:
package com.wjy.ss; import java.util.Arrays; import org.apache.spark.SparkConf; import org.apache.spark.SparkContext; import org.apache.spark.api.java.JavaPairRDD; import org.apache.spark.api.java.JavaSparkContext; import org.apache.spark.api.java.function.FlatMapFunction; import org.apache.spark.api.java.function.Function2; import org.apache.spark.api.java.function.PairFunction; import org.apache.spark.api.java.function.VoidFunction; import org.apache.spark.broadcast.Broadcast; import org.apache.spark.streaming.Durations; import org.apache.spark.streaming.api.java.JavaDStream; import org.apache.spark.streaming.api.java.JavaPairDStream; import org.apache.spark.streaming.api.java.JavaReceiverInputDStream; import org.apache.spark.streaming.api.java.JavaStreamingContext; import scala.Tuple2; public class SparkStreamingTest { public static void main(String[] args) { SparkConf conf = new SparkConf().setMaster("local[2]").setAppName("SparkStreamingTest"); JavaSparkContext sc = new JavaSparkContext(conf); sc.setLogLevel("WARN");//设置日志级别 不打印一堆无用的日志 //创建JavaStreamingContext 批次间隔为5秒 JavaStreamingContext jsc = new JavaStreamingContext(sc,Durations.seconds(5)); //监听134.32.123.101 9999端口 获取文本socket流 JavaReceiverInputDStream<String> socketTextStream = jsc.socketTextStream("134.32.123.101", 9999); //接下来进行wordcount JavaDStream<String> words = socketTextStream.flatMap(new FlatMapFunction<String, String>() { private static final long serialVersionUID = 1L; @Override public Iterable<String> call(String line) throws Exception { return Arrays.asList(line.split(" ")); } }); JavaPairDStream<String, Integer> pairWords = words.mapToPair(new PairFunction<String, String, Integer>() { private static final long serialVersionUID = 1L; @Override public Tuple2<String, Integer> call(String word) throws Exception { return new Tuple2<String, Integer>(word,1); } }); JavaPairDStream<String, Integer> reduceByKey = pairWords.reduceByKey(new Function2<Integer, Integer, Integer>() { private static final long serialVersionUID = 1L; @Override public Integer call(Integer v1, Integer v2) throws Exception { return v1+v2; } }); //print()默认打印在此 DStream 中生成的每个RDD 的前十个元素。加参数前num个元素 //reduceByKey.print(); /** * foreachRDD 可以拿到DStream中的RDD ,对拿到的RDD可以使用RDD的transformation类算子转换,要对拿到的RDD使用action算子触发执行,否则,foreachRDD不会执行。 * foreachRDD 中call方法内,拿到的RDD的算子外,代码是在Driver端执行。可以使用这个算子实现动态改变广播变量。 * */ reduceByKey.foreachRDD(new VoidFunction<JavaPairRDD<String,Integer>>() { private static final long serialVersionUID = 1L; @Override public void call(JavaPairRDD<String, Integer> rdd) throws Exception { //Driver端执行 System.out.println("Driver ......."); //获取SparkContext SparkContext context = rdd.context(); //创建JavaSparkContext JavaSparkContext javaSparkContext = new JavaSparkContext(context); //广播变量 这里可以读取一个文件 文件内容可变 就达到了动态改变广播变量的目的 Broadcast<String> broadcast = javaSparkContext.broadcast("hello wjy"); String value = broadcast.value(); System.out.println(value); JavaPairRDD<String, Integer> mapToPair = rdd.mapToPair(new PairFunction<Tuple2<String,Integer>, String,Integer>() { private static final long serialVersionUID = 1L; @Override public Tuple2<String, Integer> call(Tuple2<String, Integer> tuple) throws Exception { System.out.println("Executor ......."); return new Tuple2<String, Integer>(tuple._1+"~",tuple._2); } }); mapToPair.foreach(new VoidFunction<Tuple2<String,Integer>>() { private static final long serialVersionUID = 1L; @Override public void call(Tuple2<String, Integer> arg0) throws Exception { System.out.println(arg0); } }); } }); /* * * 执行结果: Driver ....... hello wjy Driver ....... hello wjy 19/04/22 17:26:46 WARN BlockManager: Block input-0-1555925206600 replicated to only 0 peer(s) instead of 1 peers 19/04/22 17:26:47 WARN BlockManager: Block input-0-1555925206800 replicated to only 0 peer(s) instead of 1 peers 19/04/22 17:26:47 WARN BlockManager: Block input-0-1555925207200 replicated to only 0 peer(s) instead of 1 peers Driver ....... hello wjy Executor ....... (ee~,1) Executor ....... (aa~,1) Executor ....... (ll~,1) Executor ....... (gg~,1) Executor ....... (dd~,1) Executor ....... (hh~,1) Executor ....... (wjy~,1) Executor ....... (kk~,1) Executor ....... (jj~,1) Executor ....... (ii~,1) Executor ....... (hello~,31) Executor ....... (tt~,1) Executor ....... (ff~,1) Executor ....... (bb~,1) Executor ....... (world~,17) Executor ....... (cc~,1) Driver ....... hello wjy */ //启动 jsc.start(); //监控:等待中断 jsc.awaitTermination(); //这里stop不会执行 我们在实际应用中根据触发条件执行 比如监控某个文件删除后就执行停止动作 jsc.stop(); } }
代码注意事项:
(2.1)启动socket server 服务器:nc –lk 9999
[root@PCS101 ~]# nc -lk 9999 hello world hello wjy hello tt hello aa hello bb hello cc hello dd hello ee hello ff hello gg hello hh hello ii hello jj hello kk hello ll
Linux中nc命令是一个功能强大的网络工具,全称是netcat。
语法:nc
-l 开启 监听模式,用于指定nc将处于监听模式。通常 这样代表着为一个 服务等待客户端来链接指定的端口。
-p<通信端口> 设置本地主机使用的通信端口。有可能会关闭
-k<通信端口>强制 nc 待命链接.当客户端从服务端断开连接后,过一段时间服务端也会停止监听。 但通过选项 -k 我们可以强制服务器保持连接并继续监听端口。
(2.2)receiver模式下接受数据,local的模拟线程必须大于等于2,一个线程用来receiver用来接受数据,另一个线程用来执行job。
(2.3)Durations时间设置就是我们能接收的延迟度。这个需要根据集群的资源情况以及任务的执行情况来调节。
(2.4)创建JavaStreamingContext有两种方式(SparkConf,SparkContext)
所有的代码逻辑完成后要有一个output operation类算子。
JavaStreamingContext.start() Streaming框架启动后不能再次添加业务逻辑。
JavaStreamingContext.stop() 无参的stop方法将SparkContext一同关闭,stop(false),不会关闭SparkContext。
JavaStreamingContext.stop()停止之后不能再调用start。
四、Driver HA(Standalone或者Mesos)
因为SparkStreaming是7*24小时运行,Driver只是一个简单的进程,有可能挂掉,所以实现Driver的HA就有必要(如果使用的Client模式就无法实现Driver HA ,这里针对的是cluster模式)。Yarn平台cluster模式提交任务,AM(AplicationMaster)相当于Driver,如果挂掉会自动启动AM。这里所说的DriverHA针对的是Spark standalone和Mesos资源调度的情况下。实现Driver的高可用有两个步骤:
第一:提交任务层面,在提交任务的时候加上选项 --supervise,当Driver挂掉的时候会自动重启Driver。
第二:代码层面,使用JavaStreamingContext.getOrCreate(checkpoint路径,JavaStreamingContextFactory)
Driver中元数据包括:
(1)创建应用程序的配置信息。
(2)DStream的操作逻辑。
(3)job中没有完成的批次数据,也就是job的执行进度。
package com.wjy.ss; import java.util.Arrays; import org.apache.spark.SparkConf; import org.apache.spark.api.java.function.FlatMapFunction; import org.apache.spark.api.java.function.Function2; import org.apache.spark.api.java.function.PairFunction; import org.apache.spark.streaming.Durations; import org.apache.spark.streaming.api.java.JavaDStream; import org.apache.spark.streaming.api.java.JavaPairDStream; import org.apache.spark.streaming.api.java.JavaStreamingContext; import org.apache.spark.streaming.api.java.JavaStreamingContextFactory; import scala.Tuple2; /** * * Spark standalone or Mesos with cluster deploy mode only: * 在提交application的时候 添加 --supervise 选项 如果Driver挂掉 会自动启动一个Driver * */ public class SparkStreamingOnHDFS { public static void main(String[] args) { SparkConf conf = new SparkConf().setMaster("local").setAppName("SparkStreamingOnHDFS"); //checkpoint目录可以设置为HDFS目录 也可以是本地目录 //final String checkpointDirectory = "hdfs://node1:9000/spark/SparkStreaming/CheckPoint2019"; final String checkpointDirectory = "./checkpoint"; //JavaStreamingContext工厂类 需要重写create方法 JavaStreamingContextFactory jscfactory = new JavaStreamingContextFactory(){ /** * 只有首次创建JavaStreamingContext 才会走这里 */ @Override public JavaStreamingContext create() { System.out.println("Creating new context"); JavaStreamingContext jsc = new JavaStreamingContext(conf,Durations.seconds(5)); jsc.sparkContext().setLogLevel("WARN"); /** * checkpoint 保存: * 1.配置信息 * 2.DStream操作逻辑 * 3.job的执行进度 * 4.offset */ jsc.checkpoint(checkpointDirectory); /** * 监控的是HDFS上的一个目录,监控文件数量的变化 文件内容如果追加监控不到。 * 只监控文件夹下新增的文件,减少的文件时监控不到的,文件的内容有改动也监控不到。 */ //JavaDStream<String> lines = jsc.textFileStream("hdfs://node1:9000/spark/sparkstreaming"); JavaDStream<String> lines = jsc.textFileStream("./data"); JavaPairDStream<String, Integer> counts = lines.flatMap(new FlatMapFunction<String, String>() { private static final long serialVersionUID = 1L; @Override public Iterable<String> call(String line) throws Exception { return Arrays.asList(line.split(" ")); } }).mapToPair(new PairFunction<String, String, Integer>() { private static final long serialVersionUID = 1L; @Override public Tuple2<String, Integer> call(String word) throws Exception { return new Tuple2<String, Integer>(word.trim(),1); } }).reduceByKey(new Function2<Integer, Integer, Integer>() { private static final long serialVersionUID = 1L; @Override public Integer call(Integer v1, Integer v2) throws Exception { return v1+v2; } }); counts.print(); return jsc; } }; /** * 获取JavaStreamingContext 先去指定的checkpoint目录中去恢复JavaStreamingContext * 如果恢复不到,通过factory创建 */ JavaStreamingContext jsc = JavaStreamingContext.getOrCreate(checkpointDirectory, jscfactory); jsc.start(); jsc.awaitTermination(); jsc.close();//jsc.stop(); } }
参考: