环境
虚拟机:VMware 10
Linux版本:CentOS-6.5-x86_64
客户端:Xshell4
FTP:Xftp4
jdk1.8
scala-2.10.4(依赖jdk1.8)
spark-1.6
一、什么是Spark
Apache Spark 是专为大规模数据处理而设计的快速通用的计算引擎。Spark是UC Berkeley AMP lab (加州大学伯克利分校的AMP实验室)所开源的类Hadoop MapReduce的通用并行计算框架,Spark拥有Hadoop MapReduce所具有的优点;但不同于MapReduce的是Job中间输出结果可以保存在内存中,从而不再需要读写HDFS,因此Spark能更好地适用于数据挖掘与机器学习等需要迭代的MapReduce的算法。
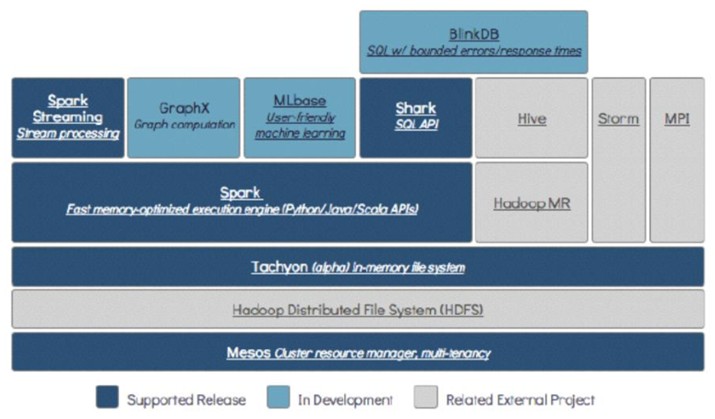
(1)Spark是Scala编写,方便快速编程。
(2)Spark与MapReduce的区别
都是分布式计算框架,Spark基于内存,MR基于HDFS;
Spark处理数据的能力一般是MR的十倍以上;
有DAG有向无环图来切分任务的执行先后顺序;
(3)Spark运行模式
Local:多用于本地测试,如在eclipse,idea中写程序测试等。
Standalone:Standalone是Spark自带的一个资源调度框架,它支持完全分布式。
Yarn:Hadoop生态圈里面的一个资源调度框架,Spark实现了AppalicationMaster接口,所以可以基于Yarn来计算的,国内用yarn的多。
Mesos:资源调度框架,国内用的少。
二、Spark-wordcount
1、java版
package com.wjy.wc; import java.util.Arrays; import org.apache.spark.SparkConf; import org.apache.spark.api.java.JavaPairRDD; import org.apache.spark.api.java.JavaRDD; import org.apache.spark.api.java.JavaSparkContext; import org.apache.spark.api.java.function.FlatMapFunction; import org.apache.spark.api.java.function.Function2; import org.apache.spark.api.java.function.PairFunction; import org.apache.spark.api.java.function.VoidFunction; import scala.Tuple2; public class JavaSparkWordCount { public static void main(String[] args) { /** * conf * 1.可以设置spark的运行模式 * 2.可以设置spark在webui中显示的application的名称。 * 3.可以设置当前spark application 运行的资源(内存+core) * * Spark运行模式: * 1.local --在eclipse ,IDEA中开发spark程序要用local模式,本地模式,多用于测试 * 2.stanalone -- Spark 自带的资源调度框架,支持分布式搭建,Spark任务可以依赖standalone调度资源 * 3.yarn -- hadoop 生态圈中资源调度框架。Spark 也可以基于yarn 调度资源 * 4.mesos -- 资源调度框架 */ SparkConf conf = new SparkConf(); conf.setMaster("local");//运行模式 conf.setAppName("JavaSparkWordCount");//webui中显示的application的名称 //SparkContext 是通往集群的唯一通道 JavaSparkContext sc = new JavaSparkContext(conf); //读取文件 返回的是一行一行的数据 JavaRDD<String> lines = sc.textFile("./data/words.txt"); /** * FlatMap 将一条数据转换为 一组数据 (迭代器),主要用于将一条记录转换为多条记录的场景,如对 每行文章中的单词进行切分,返回每行中所有单词。 * 对lines的每一条数据应用FlatMapFunction,然后返回一个迭代,然后把这个迭代里数据转化成一堆数据 * org.apache.spark.api.java.function.FlatMapFunction<T.R> * A function that returns zero or more output records from each input record. * T 是入参 R是出参 * public Iterable<R> call(T) * */ JavaRDD<String> words = lines.flatMap(new FlatMapFunction<String,String>(){ private static final long serialVersionUID = 1L; @Override public Iterable<String> call(String line) throws Exception { return Arrays.asList(line.split(" ")); } }); /** * MAP操作 * 在java中 如果想让某个RDD转换成K,V格式 使用xxxToPair * K,V格式的RDD:JavaPairRDD<String, Integer> * 对每一个单词 返回一个计数1 * org.apache.spark.api.java.function.PairFunction<T,K,V> * A function that returns key-value pairs (Tuple2<K, V>), and can be used to construct PairRDDs. * * public Tuple2<String, Integer> call(String T) * call方法的入参就是PairFunction的T * */ JavaPairRDD<String,Integer> pairwords = words.mapToPair(new PairFunction<String,String,Integer>() { private static final long serialVersionUID = 1L; //返回二元元组 @Override public Tuple2<String, Integer> call(String word) throws Exception { return new Tuple2<String,Integer>(word,1); } }); /** * reduce操作 * reduceByKey处理对象是key, value 形式的RDD,对相同key的数据进行处理,最终每个key只保留一条记录 * 1.先将相同的key分组 * 2.对每一组的key对应的value去按照你的逻辑去处理 * * org.apache.spark.api.java.function.Function2<T1,T2,R> * A two-argument function that takes arguments of type T1 and T2 and returns an R. * 使用两个参数的函数,T1和T2作为入参,返回R * public Integer call(Integer T1, Integer T2) * 上面T1 T2作为call的入参 */ JavaPairRDD<String,Integer> reduce = pairwords.reduceByKey(new Function2<Integer,Integer,Integer>() { private static final long serialVersionUID = 1L; @Override public Integer call(Integer T1, Integer T2) throws Exception { return T1+T2; } } ); //调个 按数量排序 JavaPairRDD<Integer, String> mapToPair = reduce.mapToPair(new PairFunction<Tuple2<String,Integer>,Integer,String>() { private static final long serialVersionUID = 1L; @Override public Tuple2<Integer, String> call(Tuple2<String, Integer> tuple) throws Exception { //使用构造方法 //return new Tuple2<Integer, String>(tuple._2,tuple._1); //使用换位方法 return tuple.swap(); } }); //排序 false降序排列 JavaPairRDD<Integer, String> sortByKey = mapToPair.sortByKey(false); //排完序之后 再调过来 JavaPairRDD<String, Integer> result = sortByKey.mapToPair(new PairFunction<Tuple2<Integer,String>,String,Integer>() { private static final long serialVersionUID = 1L; @Override public Tuple2<String, Integer> call(Tuple2<Integer, String> tuple) throws Exception { return tuple.swap(); } }); //遍历打印输出结果 result.foreach(new VoidFunction<Tuple2<String,Integer>>(){ private static final long serialVersionUID = 1L; @Override public void call(Tuple2<String, Integer> tuple) throws Exception { System.out.println(tuple); } }); sc.stop(); sc.close(); } }
2、scala版
package com.wjy import org.apache.spark.SparkConf; import org.apache.spark.SparkContext import org.apache.spark.rdd.RDD object ScalaWordCount { def main(args: Array[String]): Unit = { //spark配置 val conf = new SparkConf(); //设置集群模式 应用名 conf.setMaster("local").setAppName("ScalaWordCount"); //获取spark上下文 val sc = new SparkContext(conf); //使用上下文读取文件:一行一行的数据 val lines : RDD[String] = sc.textFile("./data/words.txt"); //将一行一行的数据转成一个个单词 val words :RDD[String] = lines.flatMap(line=>{ line.split(" ") }); //Map操作 val pairwords : RDD[(String,Int)] = words.map(word=>{ new Tuple2(word,1) }); //Reduce操作 val reduce:RDD[(String,Int)] = pairwords.reduceByKey((V1:Int,V2:Int)=>{ V1+V2 }); //排序打印出来 val rdd1:RDD[(Int,String)] = reduce.map(tuple=>{tuple.swap}); rdd1.sortByKey(false).map(tuple=>{tuple.swap}).foreach(tuple=>{ println(tuple) }); sc.stop(); } }
参考:
Spark:https://www.cnblogs.com/qingyunzong/category/1202252.html
Spark初识:https://www.cnblogs.com/qingyunzong/p/8886338.html
Spark2.3 HA集群的分布式安装:https://www.cnblogs.com/qingyunzong/p/8888080.html