环境
虚拟机:VMware 10
Linux版本:CentOS-6.5-x86_64
客户端:Xshell4
FTP:Xftp4
jdk8
hadoop-3.1.1
由于NameNode对于整个HDFS集群重要性,为避免NameNode单点故障,在集群里创建2个或以上NameNode(不要超过5个),保证高可用。
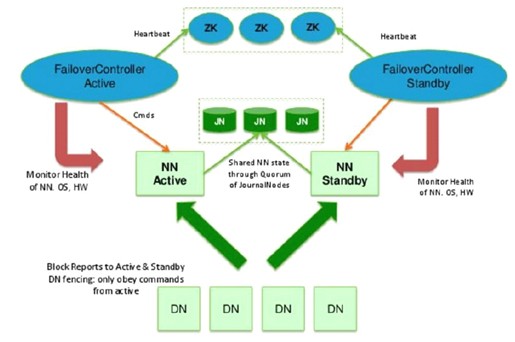
实现主备NameNode需要解决的问题:
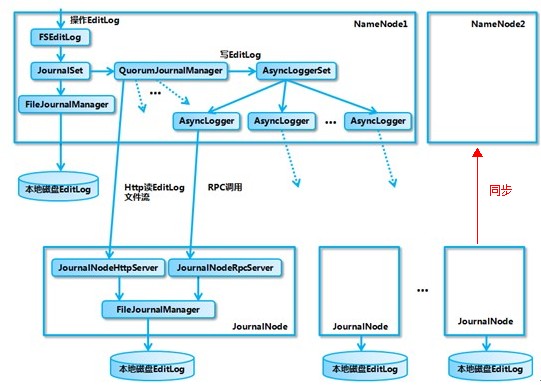
1、通过JournalNodes来保证Active NN与Standby NN之间的元数据同步
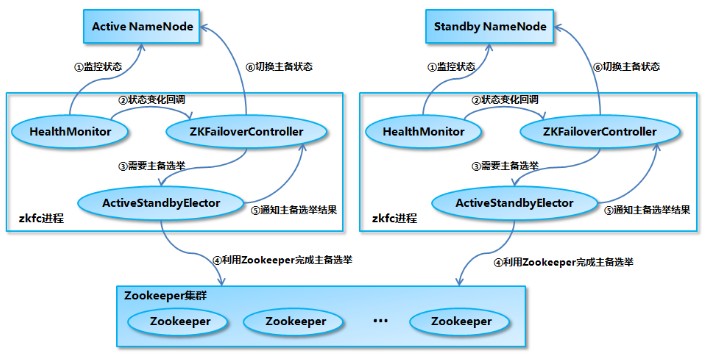
2、通过ZKFC来保证Active NN与Standby NN主备切换
3、DataNode会同时向Active NN与Standby NN上报数据块的位置信息
参考:
hdfs HA原理及安装
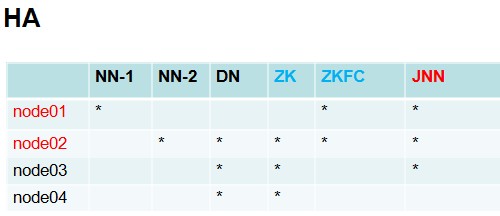
搭建HA集群部署节点清单:
一、平台软件环境
1、平台:GNU/Linux
2、软件:jdk+免密登录
3、JAVA和Hadoop环境变量以及主机名设置
参考:【Hadoop学习之三】Hadoop全分布式安装
二、配置(node1-node4采用相同配置)
1、hadoop-env.sh
export JAVA_HOME=/usr/local/jdk1.8.0_65 export HDFS_NAMENODE_USER=root export HDFS_DATANODE_USER=root #设置ZKFC角色用户 export HDFS_ZKFC_USER=root #设置JOURNALNODE角色用户 export HDFS_JOURNALNODE_USER=root
2、core-site.xml
<configuration> <!--主节点通讯设置--> <property> <name>fs.defaultFS</name> <value>hdfs://hdfscluster</value> </property> <!--元数据、Block存放目录--> <property> <name>hadoop.tmp.dir</name> <value>/data/ha</value> </property> <!--静态目录用户--> <property> <name>hadoop.http.staticuser.user</name> <value>root</value> </property> <!--zk集群--> <property> <name>ha.zookeeper.quorum</name> <value>node2:2181,node3:2181,node4:2181</value> </property> </configuration>
3、hdfs-site.xml
(1)dfs.nameservices:namenode服务逻辑名称
(2)dfs.ha.namenodes.[nameservice ID] namenode清单,逗号分隔
(3)dfs.namenode.rpc-address.[nameservice ID].[name node ID] HDFS Client通过RPC访问HDFS
(4)dfs.namenode.http-address.[nameservice ID].[name node ID] webUI管理界面主机和端口
(5)dfs.namenode.shared.edits.dir JournalNodes元数据共享目录集群地址
(6)dfs.client.failover.proxy.provider.[nameservice ID] 故障转移的代理类
(7)dfs.ha.fencing.methods 两个namenode的隔离方法,避免脑裂局面
(原来的Active NN 可能由于网络、进程阻塞等原因暂时中断,此时ZKFC将Standby NameNode提升为 Active NN,等原来的Active NN网络或进程恢复后,又继续提供服务,这样就出现脑裂局面。
所以必需采取强制措施将SNN变成ANN之前,先要将原来的ANN变成SNN)
(8)dfs.ha.fencing.ssh.private-key-files 配置ssh私钥免密登录原ANN节点进行降级处理
(9)dfs.journalnode.edits.dir 配置journalnode共享元数据存放位置
(10)dfs.ha.automatic-failover.enabled 配置true支持故障自动转移
<configuration> <!--副本数设置--> <property> <name>dfs.replication</name> <value>3</value> </property> <!--NN集群逻辑名称--> <property> <name>dfs.nameservices</name> <value>hdfscluster</value> </property> <!--NN集群节点清单--> <property> <name>dfs.ha.namenodes.hdfscluster</name> <value>node1,node2</value> </property> <!--与客户端通讯端口--> <property> <name>dfs.namenode.rpc-address.hdfscluster.node1</name> <value>node1:8020</value> </property> <property> <name>dfs.namenode.rpc-address.hdfscluster.node2</name> <value>node2:8020</value> </property> <!--WEBUI访问端口--> <property> <name>dfs.namenode.http-address.hdfscluster.node1</name> <value>node1:9870</value> </property> <property> <name>dfs.namenode.http-address.hdfscluster.node2</name> <value>node2:9870</value> </property> <!--journalnode地址--> <property> <name>dfs.namenode.shared.edits.dir</name> <value>qjournal://node1:8485;node2:8485;node3:8485/hdfscluster</value> </property> <!--故障转移代理类--> <property> <name>dfs.client.failover.proxy.provider.mycluster</name> <value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value> </property> <!--采用ssh隔离--> <property> <name>dfs.ha.fencing.methods</name> <value>sshfence</value> </property> <!--采用私钥进行免密登录--> <property> <name>dfs.ha.fencing.ssh.private-key-files</name> <value>/root/.ssh/id_rsa</value> </property> <!--journalnode共享元数据存放位置--> <property> <name>dfs.journalnode.edits.dir</name> <value>/data/ha/journal</value> </property> <!--故障自动转移--> <property> <name>dfs.ha.automatic-failover.enabled</name> <value>true</value> </property> </configuration>
4、workers DN节点
node2
node3
node4
将hadoop-env.sh、core-site.xml、hdfs-site.xml、workers分发至node2、node3、node4
[root@node1 hadoop]# scp hadoop-env.sh core-site.xml hdfs-site.xml workers node2:`pwd` [root@node1 hadoop]# scp hadoop-env.sh core-site.xml hdfs-site.xml workers node3:`pwd` [root@node1 hadoop]# scp hadoop-env.sh core-site.xml hdfs-site.xml workers node4:`pwd`
三、安装ZooKeeper
参考:zookeeper 安装以及集群搭建
四、启动
注意:启动HDFS之前一定要先启动ZK集群。
1、启动JournalNode守护程序
根据部署清单,在node1、node2、node3
[root@node1 hadoop]# hdfs --daemon start journalnode [root@node2 hadoop]# hdfs --daemon start journalnode [root@node3 hadoop]# hdfs --daemon start journalnode [root@node1 hadoop]# jps 2960 Jps 2921 JournalNode
关闭:hdfs --daemon stop journalnode
查看journalnode共享元数据存放位置配置的路径dfs.journalnode.edits.dir下,会出现这个目录
[root@node1 ha]# ls journal
2、格式化NameNode(集群首次搭建好之后需要格式化,只执行一次)
这里有两台NN,我们选择node1
[root@node1 /]# hdfs namenode -format
3、启动主NN
[root@node1 sbin]# hadoop-daemon.sh start namenode 或者 [root@node1 sbin]# hdfs --daemon start

4、备用NN 同步主NN信息
这里node2作为备机NN
[root@node2 sbin]# hdfs namenode -bootstrapStandby
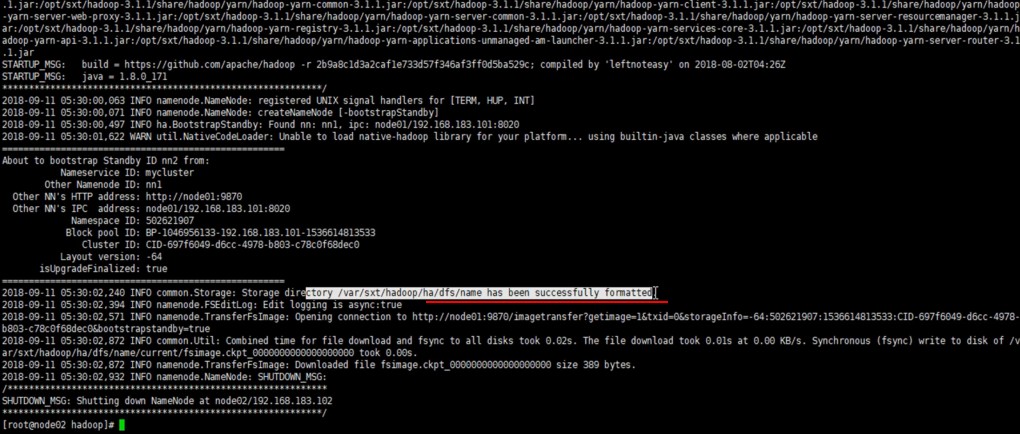
在hadoop.tmp.dir配置的目录下面会出现同步的目录:dfs
如果非HA转做HA时,需要在备机上执行:hdfs namenode -initializeSharedEdits 将主机原来的元数据信息同步到备机上
5、格式化ZK
在其中一台NN上执行命令:
[root@node1 sbin]# hdfs zkfc -formatZK
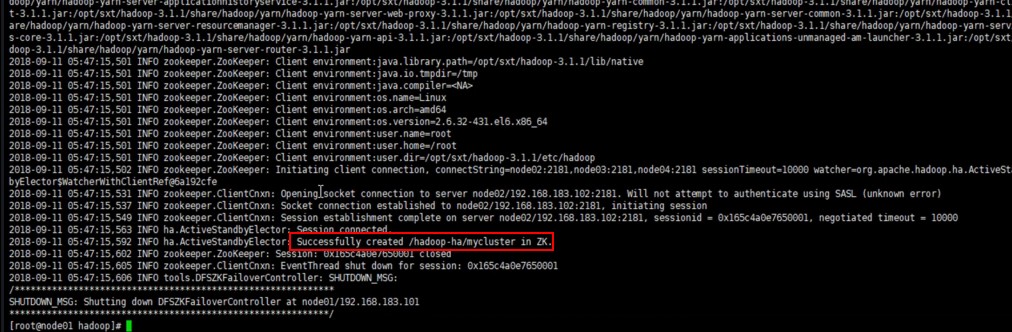
通过zkCli.sh客户端登录ZK集群,会看到生成了hadoop对应的集群节点
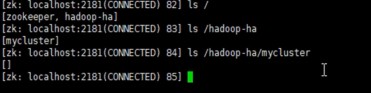
6、启动hadoop集群
在主节点NameNode启动集群,会在主和备NN上启动ZKFC守护进程(维护时,可以手动启动ZKFC:hdfs --daemon start zkfc)
[root@node1 sbin]# start-dfs.sh
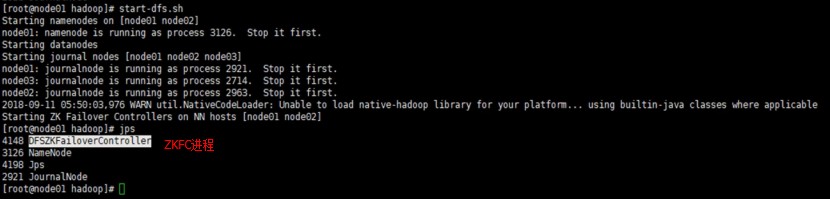
通过zkCli.sh查看节点:
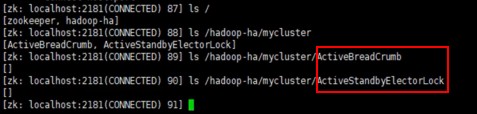
通过浏览器查看:
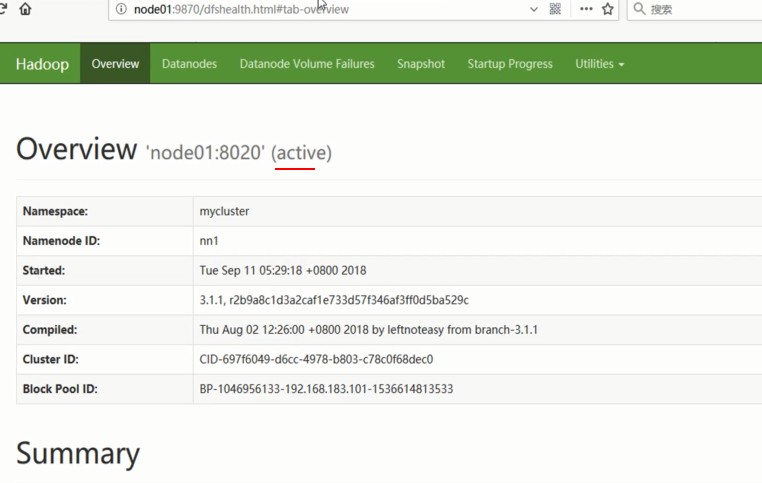
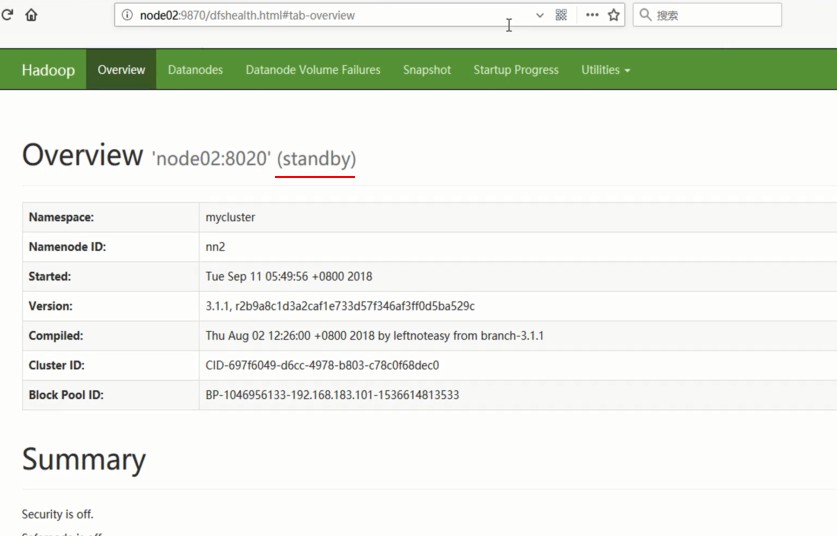
查看ZK中主节点抢占注册:
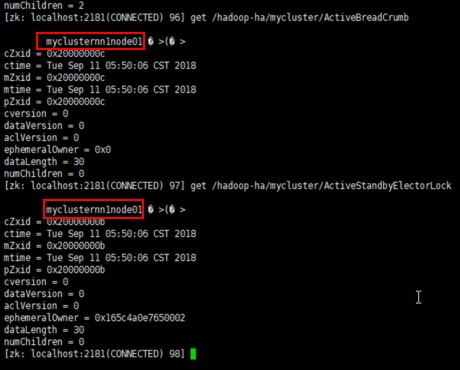
7、主备切换测试
(1)关闭Active NameNode
[root@node1 sbin]# hdfs --daemon stop namenode
关闭前:ANN:node1,SNN:node2
关闭后:ANN:node2,SNN:node1

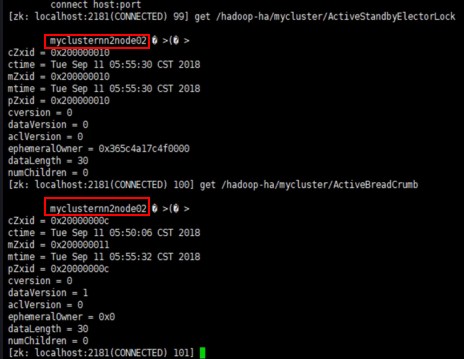
(2)启动刚才关闭的NameNode
[root@node1 sbin]# hdfs --daemon start namenode
启动前:ANN:node2,SNN:node1
启动后:ANN:node2,SNN:node1
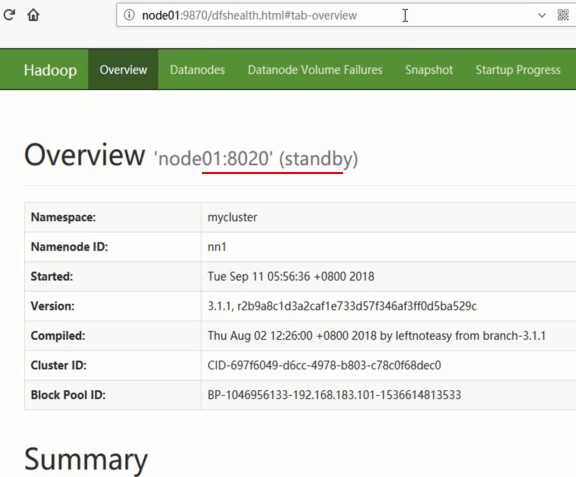
(3)关闭node2上的ZKFC
[root@node2 sbin]# hdfs --daemon stop zkfc
关闭前:ANN:node2,SNN:node1
关闭后:ANN:node1,SNN:node2
参考:
hadoop-3.1.1/hadoop-3.1.1/share/doc/hadoop/hadoop-project-dist/hadoop-hdfs/HDFSHighAvailabilityWithQJM.html