1.目标
实现免费的ocr
2.吐槽
目前网络上太多小白了,都不知道去官网下载的么,百度上大量充斥着付费下载,我真是服了,本来打算偷懒,问了下付费下载需要多少钱,
根据指引,加了QQ,竟然需要我付费10块钱,真实大大的人才!!!
作为开源精神的开发者,这不能忍,花了点时间写下这篇文档,只愿有更多志同道合的同学可以开源学习感兴趣的领域
3.安装Tesseract
官网地址 https://digi.bib.uni-mannheim.de/ 官网里的资源下载库路径 https://digi.bib.uni-mannheim.de/tesseract/ 目前我用的版本是 tesseract-ocr-w64-setup-v5.0.0.20190623.exe 直接下载该版本的路径 https://digi.bib.uni-mannheim.de/tesseract/tesseract-ocr-w64-setup-v5.0.0.20190623.exe
下载后,是个exe安装文件,傻瓜式一键安装,需要设置下安装路径,尽可能不要使用默认位置

在安装文件夹里会生成大量文件
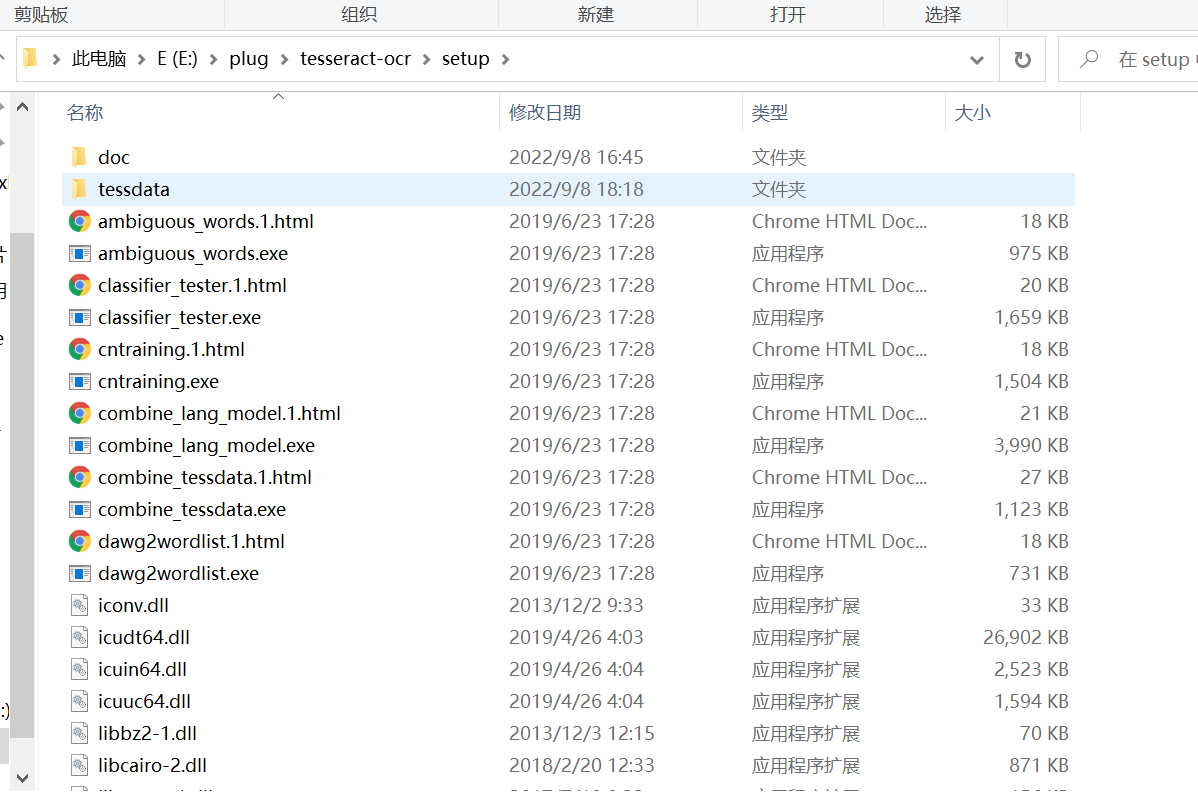
那么这个文件夹就是根目录,
将根目录的路径设置在系统的环境变量的path里 ,这一步很重要,否则java无法调用


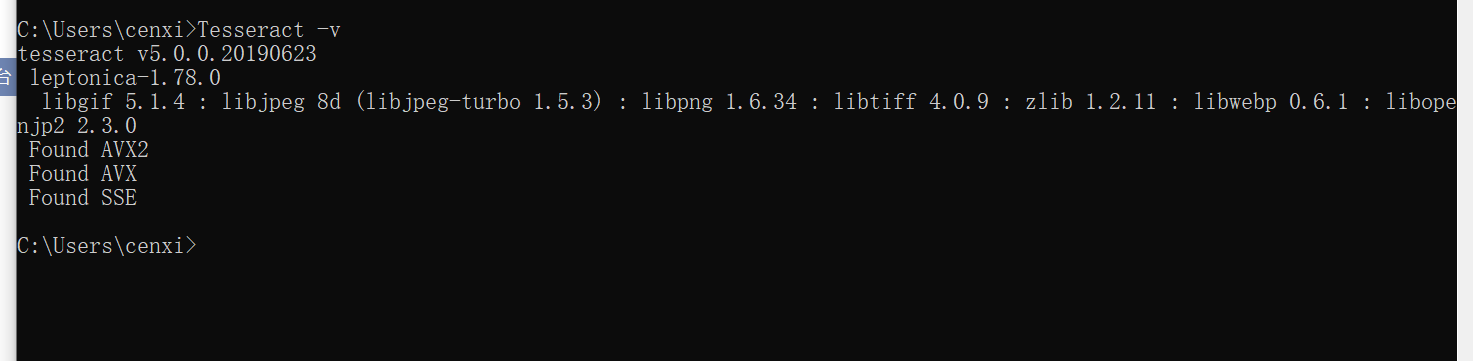
cmd打开指令框,输入
Tesseract -v
出现版本信息表示安装成功
4.添加训练数据
在这个 tessdata 文件夹里,添加需要的训练数据,默认只有eng的,即英文和数字 的 训练数据 ,如果需要识别中文 ,需要去git仓库下载
仓库地址有几个,都差不多,但是以后有可能被删除
https://gitcode.net/mirrors/tesseract-ocr/tessdata/-/tree/master
https://github.com/tesseract-ocr/tessdata_best
https://github.com/tesseract-ocr/tessdata
找到 chi_sim.traineddata 这个文件下载

将这个包放入 tessdata 文件夹里 即可
注意,这个包是官方开源的中文训练数据,准确率不高,大概70%左右,需要对不同的场景重新训练数据集,生成自己的traineddata文件后扔入tessdata文件夹里使用,训练自己的数据集再下一篇随笔讲解
5.java 使用
maven引入依赖包
<dependency>
<groupId>net.sourceforge.tess4j</groupId>
<artifactId>tess4j</artifactId>
<version>4.6.0</version>
</dependency>
使用的写法很简单,指定图片路径即可
public static String readStr(File file, String path) throws TesseractException { if (null == file) file = new File(path); Tesseract instance = new Tesseract();
//设置 tessdata 文件夹 的本地路径 instance.setDatapath("E:\\plug\\tesseract-ocr\\setup\\tessdata");
//设置需要使用的训练集,不设置则默认为eng instance.setLanguage("chi_sim"); return instance.doOCR(file); }
我简单封装的工具类


import lombok.Data; import net.sourceforge.tess4j.Tesseract; import net.sourceforge.tess4j.TesseractException; import java.io.File; @Data public class OCRUtil { /** * ocr读取文字 */ public static String readStr(File file) throws TesseractException { return readStr(file, null); } public static String readStr(String path) throws TesseractException { return readStr(null, path); } public static String readStr(File file, String path) throws TesseractException { if (null == file) file = new File(path); Tesseract instance = new Tesseract(); instance.setDatapath("E:\\plug\\tesseract-ocr\\setup\\tessdata"); instance.setLanguage("chi_sim"); return instance.doOCR(file); } public static void main(String[] args) throws TesseractException { // System.out.println(OCRUtil.readStr("C:\\Users\\cenxi\\Downloads\\m2\\m2.png")); // System.out.println(OCRUtil.readStr("C:\\Users\\cenxi\\Downloads\\meid.jpg")); System.out.println(OCRUtil.readStr("C:\\Users\\cenxi\\Downloads\\orc1.jpg")); // System.out.println(OCRUtil.readStr("C:\\Users\\cenxi\\Downloads\\orc1.png")); } }
6.测试

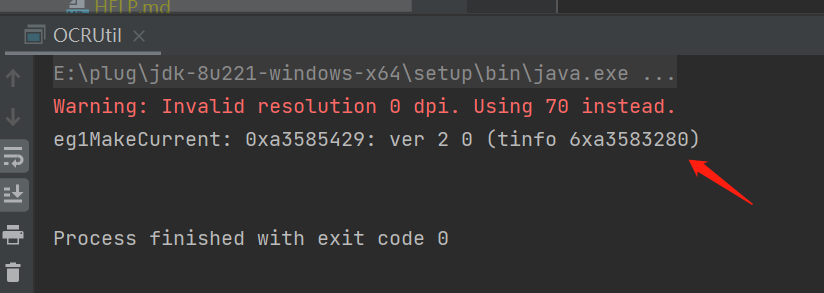
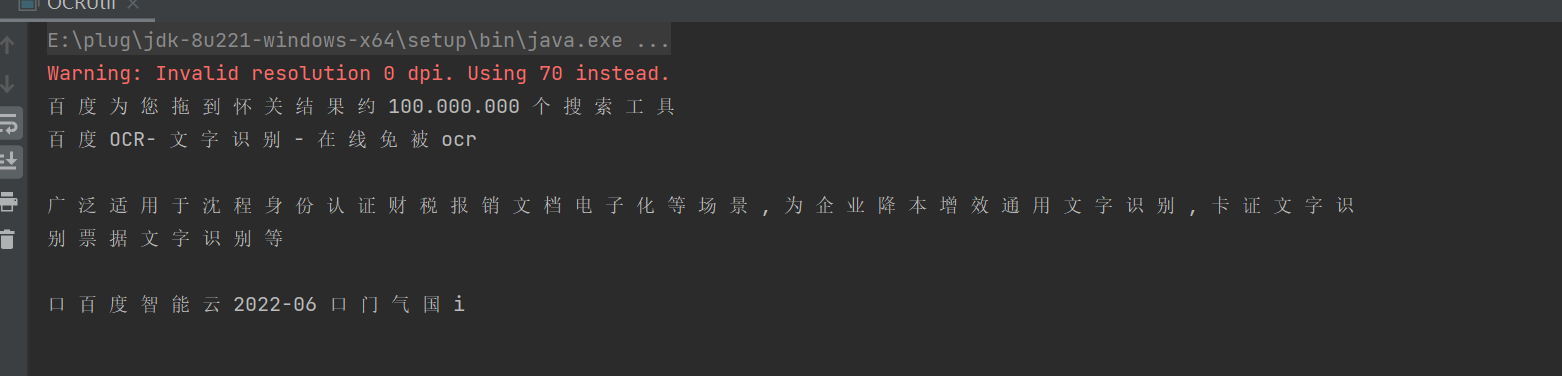
中文的准确率有待提高
手写字体需要自己训练,官网没有提供