https://aclanthology.org/P17-1018/
Introduction
在BiDAF模型问世后,机器阅读理解模型的研究主要是在交互层,特别是上下文编码和注意力机制的创新。R-net就是典型的代表,R-net在注意力机制中加入了门机制,可以动态控制模型利用各部分的信息,取得了很好的实际效果。
模型的组成部分
- 循环网络的编码器,分别建立问题和上下文的语义表示
- 门匹配层,对问题和上下文进行匹配
- 自匹配层,对整个段落的信息进行聚合
- 基于答案边界预测的指针网络层
gated attention-based recurrent network
通过引入门控机制,我们的基于门控注意力的循环网络根据段落部分与问题的相关性分配不同级别的重要性,掩盖不相关的段落部分并强调重要的段落部分。
self-matching mechanism
尽管循环网络具有理论能力,但在实践中只能记忆有限的段落上下文。一个答案的候选人往往不知道文章其他部分的线索。为了解决这个问题,我们提出了一个自匹配层,利用整个段落的信息来动态地细化段落表示。
基于门控注意力的循环网络层和自匹配层通过从问题和段落聚合的信息动态地丰富每个段落表示,使后续网络能够更好地预测答案。
Gated Self-Matching Networks
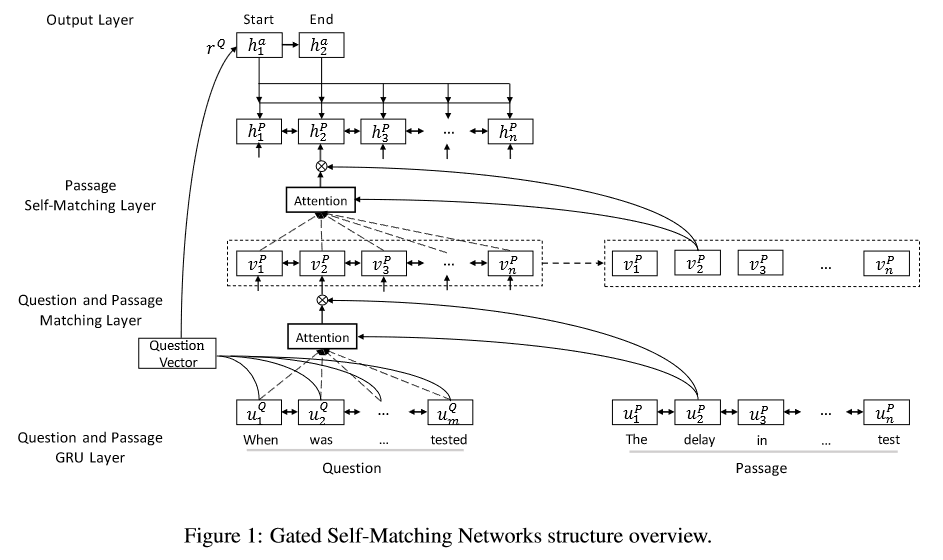
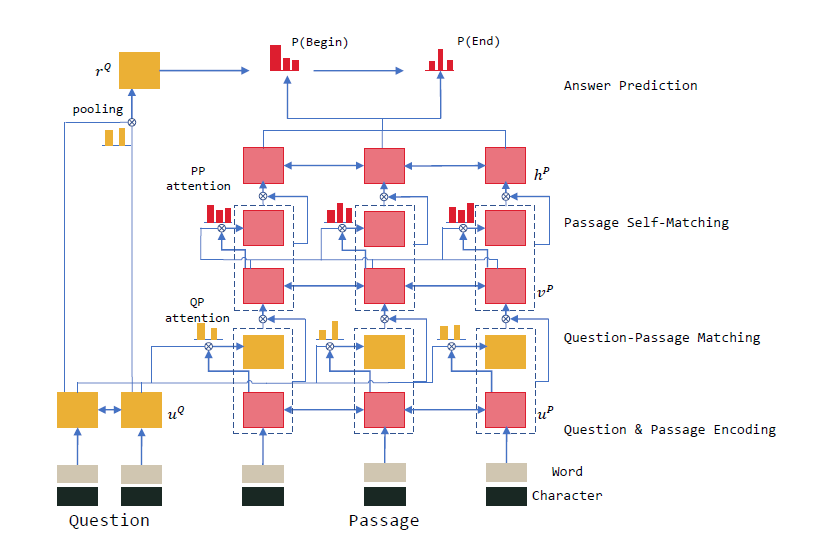
流程
将问题和段落由双向RNN处理,然后将问题和段落与基于注意力的RNN匹配,为段落获得问题感知的表示。除此之外,用自匹配注意力来聚合整个段落证据,并改进段落表示,然后输入到输出层,预测答案跨度的边界。
Question and Passage Encoder
设问题为\(Q = \left\{w^{Q}_{t} \right\}^{m}_{t=1}\),段落为\(P = \left\{ w^{P}_{t} \right\}^{n}_{t=1}\)
然后将Q和P进行word-embedding得到问题的编码$\left{ e^{Q}{t} \right}^{m}{t=1} \(和**段落的编码**\)\left{ e^{P}{t} \right}^{n}{t=1} $
接着进行character-embedding得到问题$\left{ c^{Q}{t} \right}^{m}{t=1} \(和**段落**\)\left{ c^{P}{t} \right}^{n}{t=1} $,字符编码能够很好的解决OOV(out of vocab)的问题
然后使用双向RNN(这里使用的是GRU)对上面的这些编码处理,分别得到问题和段落的语义表示
Gated Attention-based Recurrent Networks(两次使用)
这里有一个门控的基于注意力的循环网络,主要是将问题纳入段落进行表示,它是基于注意力的循环网络的一个变体,用一个额外的门来确定关于一个问题的段落中的信息的重要性。
根据上面的\(u^{Q}_{t}\)和\(u^{P}_{t}\),通过以下公式得到\(v^{P}_{t}\),这个\(v^{P}_{t}\)是每个段的表示,能够动态地从整个问题中融入聚合的匹配信息。\(v^{P}_{t}\)公式如下:
\(c_{t}\)(整个问题的注意力池向量\(u^{Q}\))的求法如下
为了找出段落中对问题有用的重要信息,这里又加了一个gate,这里的gate用于\([u^{P}_{t},c_{t}]\),公式如下
附加门是基于问句的当前通行词及其注意力池向量,关注问句与当前通行词之间的关系。门有效地模拟了在阅读理解和问答中只有部分段落与问题相关的现象。在后续计算中使用$[u{P}_{t},c_{t}]{*} \(不是\)[u^{P}{t},c{t}]$。门有效地模拟了阅读理解和问答中段落与问题相关的现象。
Self-Matching Attention
因为这里计算attention的时候,还是和自己,所以叫做self-matching attetion

通过gated attention-based recurrent networks,生成问题感知的篇章表示\(\left\{ v^{P}_{t} \right\}^{n}_{t=1}\),来确定篇章中的重要部分。
这种篇章表示有一个问题那就是对于语境的了解非常有限。比如一个候选答案就可能对其周围窗口之外的重要线索一无所知。为了解决这个问题,我们提出直接将问题感知的段落表示与自身进行匹配。它针对篇章中的词动态地从整个篇章中收集证据,并将与当前篇章词相关的证据及其匹配的问句信息编码到篇章表征\(h^{P}_{t}\)中。
\(c_{t}\)是整个段落\(v^{P}\)的注意力池向量
附加的门用于\([v^{P}_{t},c_{t}]\)来自适应控制RNN的输入
自匹配根据当前段落单词和问题信息从整个段落中提取依据
Output Layer
这里使用pointer networks去预测答案的位置,我们使用对问题表示的注意力池化来为指针网络生成初始隐藏向量。
根据段落表示\(\left\{ h^{P}_{t} \right\}^{n}_{t=1}\),注意力机制被用作一个指针,从通道中选择开始位置( p1 )和结束位置( p2 ),其表达式如下
这里\(h^{a}_{t-1}\)表示答案递归网络(指针网络)的最后一个隐藏状态。答案递归网络的输入是基于当前预测概率的注意力池化向量
在预测起始位置时,\(h^{a}_{t-1}\)表示答案递归网络的初始隐藏状态,我们使用问题向量\(r^{Q}\)作为初始状态,这个\(V^{P}_{r}\)是啥?
Experiment
词嵌入使用的glove,使用0向量来表示OOV,上下文编码使用3层双向GRU,门控的基于注意循环神经网络关于问题和段落匹配的,使用双向RNN,隐藏层向量的大小是75,所以层都是这个数,dropout是0.2,使用的是AdaDelta优化器。
效果
single model
Dev set上的EM(Exact match匹配)是71.1,F1(准确率和召回率的调和平均数)是79.5,Test set上是71.3,F1是79.7
ensemble model(可以理解为跑n个single model,取最好的模型结果机器学习 - Ensemble Model - 知乎 (zhihu.com))
Dev set上EM是75.6,Test set上是82.9
消融测试
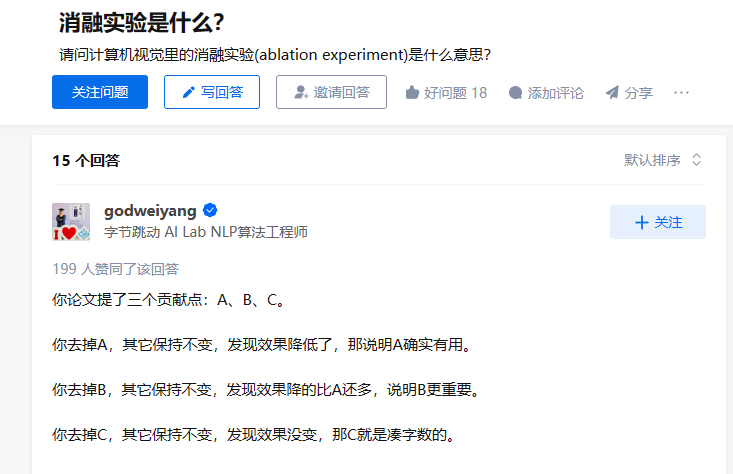
消融测试结果如下图
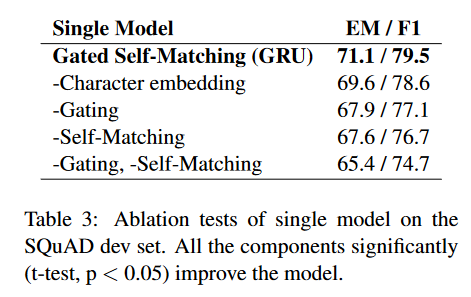
gated attention-based recurrent net 和 self-matching attention mechanism对自匹配网络有作用,self-matching的EM分数从GRU的71.1下降到了67.6,character embedding对模型的表现作用不大,但是它可以处理OOV或稀有的词,
模型的有效性