目录:
- Kafka存储机制
- Kafka分区规则
- Kafka分区策略
- Kafka日志
Kafka存储机制
再说Kafka存储机制之前我们先了解下分区和副本的作用:
- 分区:为了提高性能(也就是分而治之,它是高并发分布式中心思想)。
- 副本:为了高可用(保证数据安全)。
如何设置副本数量:
- 最低一个,最大不超过broker的数量(不在范围内的首先会报错;其次没有意义,超过broker数量时,首先broker宕机时不管你有多少个副本都是一起挂掉,拿不到数据)。
- 就经验来说,参考Hadoop副本数量分配(Hadoop默认3个)。
——————————————————————————————————————————————————————
Kafka数据分为索引数据和数据,xxx.index、xxx.log。
存储机制同样采用分而治之的方式,首先消息根据topic(主题)分区,每个topic又有多个partition(分区),每个partition下又有多个segment(数据片)。

每一个partition就相当于一个巨大的文件,它被segment拆分成多个小文件,这边是分而治之的思想。
你也可以理解成是公司,每个老板都是topic;为了提高管理效率增加了部门领导(partition),领导又管理职工(segment)。

.index存储元数据,.log存储大量的消息。如果我们要找获取消息,首先会通过二分法找到对应的index文件,再从index文件的偏移量找到对应的log文件。
如果是找偏移量为348的数据(上图左侧黄色编号为3),即对应log文件170410+3=170413,也就是消息为message170413的。
Kafka分区规则
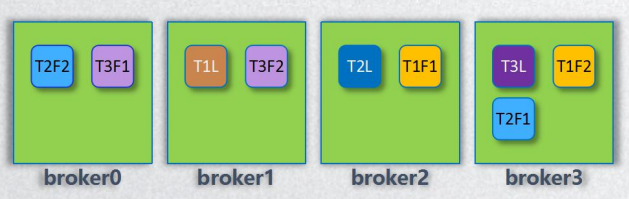
假如我们有3个分区,3个副本(L代表leader,F代表follow)。
故机器配置如下:
T1L T2L T3L
T1F1 T2F1 T3F1
T1F2 T2F2 T3F2
1、先从所有broker选一个存储第一个leader分区(选出broker1为T1L)。
2、按照broker顺序分配第二、第三个leader分区(所以T2L、T3L分别被分在broker2、broker3上)。
3、依次分配follow分区(如:第T1L被分配到broker1上,那么T1F1、T1F2就会被分配到broker2和broker3上;依次类推,T2L的两个follow会被依次分在broker3、broker0上)。
Kafka分区策略
- 轮询策略:若键值为null,并使用默认分区器,Kafka会根据轮询策略将消息均匀的分到各个分区上。
- 散列策略:若键值不为null,并使用了默认分区器,Kafka会对键进行散列,然后根据散列值将消息映射到对应的分区上。
- 自定义策略:用户可根据需要对数据使用不一样的分区策略。
Kafka日志
ISR、HW、LEO同步流程:
- ISR(In-sync replica): 副本同步队列,当有一条新的消息提交后,副本同步消息成功后才会出现在此队列中。若某个follow副本落后太多或宕机,leader会将它从ISR中删除。
- HW(high watemark): 高水位,指ISR中所有节点都已经复制完的消息的offset,也是消费者能获取到的最大的offset。
- LEO(LogEndOffset): 最后一条消息的偏移量。
假如有3个副本。
一开始消息的状态是这样的:
L F1 F2
1 1 1
2 2 2
HW & LEO 3 3 3
现发送一条消息,此时消息会先到leader副本,然后再通知其它两个follow副本复制。若此时仅有F1复制成功,此时便是这样的。
L F1 F2
1 1 1
2 2 2
HW 3 3 3
LEO 4 4
那么HW便是在4之上的3的位置,LEO是4的位置,LSR是L、F1。
当所有副本都同步完之后,HW与LEO便回到一个位置上。
L F1 F2 1 1 1 2 2 2 HW & LEO 3 3 3
4 4 4
——————————————————————————————————————————————————————
查看日志命令:./kafka-dumplog.sh --files --file /home/hadoop/kafka/broker-0/xxxx.index