排序算法分类
选择排序:简单选择排序、堆排序
插入排序:直接插入排序、二分插入排序和希尔排序
归并排序:归并排序
交换排序:冒泡排序、快速排序
基数排序:基数排序
算法时间和空间复杂度分析
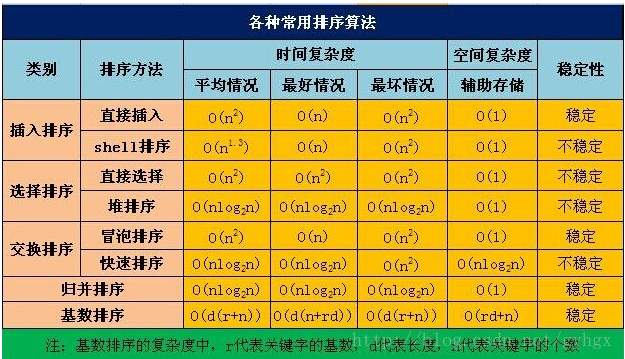
图1 性能分析
排序算法精讲
选择排序:
简单选择排序
思想:每次找出一个当前最小值并放到合适的位置。
不稳定排序
1)首先在未排序序列中找到最小(大)元素,存放到排序序列的起始位置
2)再从剩余未排序元素中继续寻找最小(大)元素,然后放到已排序序列的末尾。
3)重复第二步,直到所有元素均排序完毕。
堆排序
思想:利用沉降原理不断的调整成大(小)根堆
不稳定排序
1 /** 2 针对数组进行排序 3 堆是一种重要的数据结构,为一棵完全二叉树, 底层如果用数组存储数据的话,假设某个元素为序号为i(Java数组从0开始,i为0到n-1),如果它有左子树,那么左子树的位置是2i+1,如果有右子树,右子树的位置是2i+2,如果有父节点,父节点的位置是(n-1)/2取整。分为最大堆和最小堆,最大堆的任意子树根节点不小于任意子结点,最小堆的根节点不大于任意子结点。所谓堆排序就是利用堆这种数据结构来对数组排序,我们使用的是最大堆。处理的思想和冒泡排序,选择排序非常的类似,一层层封顶,只是最大元素的选取使用了最大堆。最大堆的最大元素一定在第0位置,构建好堆之后,交换0位置元素与顶即可。堆排序为原位排序(空间小), 且最坏运行时间是O(nlgn),是渐进最优的比较排序算法。 4 **/ 5 6 //初始化建立大根堆 7 private static void buildMaxHeap(int[] array){ //初始时建立大根堆 8 if(array == null || array.length <= 1){ 9 return; 10 } 11 12 int half = array.length/2; 13 for(int i = half; i >=0; i--){ 14 maxHeap(array, array.length, i); 15 } 16 } 17 18 //调整堆,使用沉降法实现大根堆 19 private static void maxHeap(int[] array, int heapSize, int index){ //利用沉降法调整堆 20 int left = index*2+1; 21 int right = index*2+2; 22 23 int largest = index; 24 if(left < heapSize && array[left] > array[largest]){ 25 largest = left; 26 } 27 28 if(right < heapSize && array[right] > array[largest]){ 29 largest = right; 30 } 31 32 if(largest != index){ //需要交换位置 33 int tmp = array[index]; 34 array[index] = array[largest]; 35 array[largest] = tmp; 36 37 maxHeap(array, heapSize, largest); 38 } 39 } 40 41 //堆排序算法 42 private static void heapSort(int[] array){ 43 if(array == null || array.length <= 1){ 44 return; 45 } 46 47 buildMaxHeap(array); 48 49 for(int i = array.length - 1; i > 0; i--){ 50 int tmp = array[0]; 51 array[0] = array[i]; 52 array[i] = tmp; 53 54 maxHeap(array, i, 0); 55 } 56 }
插入排序
直接插入排序
思想:每次插入一个元素,保持前面子数组的有序性。
稳定排序
折半插入排序
思想:将待排序的记录R[i]插入到已经排序完成的记录子表R[0,1,...i-1]中时,由于该子表已经排序完成,插找插入位置时可以使用"折半查找"实现。
1)选择一个增量序列t1,t2,…,tk,其中ti>tj,tk=1;
2)按增量序列个数k,对序列进行k 趟排序;
3)每趟排序,根据对应的增量ti,将待排序列分割成若干长度为m的子序列,分别对各子表进行直接插入排序。仅增量因子为1 时,整个序列作为一个表来处理,表长度即为整个序列的长度。
1 public int[] shellSort(int[] num, int len) { 2 // write code here 3 if(num == null || len < 2) 4 return num; 5 6 for(int step = len/2; step >= 1; step = step/2){ //选取希尔排序的间隔 7 subShellSort(num, step); 8 } 9 10 return num; 11 } 12 13 public void subShellSort(int[] num, int step){ 14 for(int i = step; i < num.length; i++){ 15 for(int j = i; j >=step; j-=step){ 16 if(num[j] < num[j-step]){ //利用冒泡排序进行子序列的排序 17 int tmp = num[j]; 18 num[j] = num[j-step]; 19 num[j-step] = tmp; 20 } 21 } 22 } 23 }
稳定排序
1 public class MergeSort { 2 public int[] mergeSort(int[] A, int n) { 3 // write code here 4 if(n<2){ 5 return A; 6 } 7 8 return sort(A,0,A.length-1); 9 10 } 11 12 public int[] sort(int[] num, int low, int high){ 13 int mid = (low+high)/2; 14 if(low < high){ 15 sort(num,low,mid); //排序左边数组 16 17 sort(num,mid+1,high); //排序右边数组 18 19 merge(num,low,mid,high); //归并两边数组 20 } 21 22 return num; 23 } 24 25 public void merge(int[] num, int low, int mid, int high){ 26 int[] tmp = new int[high-low+1]; //建立临时数组 27 int i = low, k = mid+1; //左右数组下标 28 int j = 0; 29 30 while(i<=mid && k<=high){ 31 if(num[i]<num[k]){ 32 tmp[j++] = num[i++]; 33 }else{ 34 tmp[j++] = num[k++]; 35 } 36 } 37 38 39 //左边数组剩余元素 40 while(i <= mid){ 41 tmp[j++] = num[i++]; 42 } 43 44 //右边数组剩余元素 45 while(k <= high){ 46 tmp[j++] = num[k++]; 47 } 48 49 //将新数组的值赋予num数组 50 for(int k1 = 0; k1<j; k1++){ 51 num[k1+low] = tmp[k1]; 52 } 53 54 } 55 }
基数排序
基数排序
思想:基数排序是一种非比较型整数排序算法,其原理是将整数按位数切割成不同的数字,然后按每个位数分别比较。由于整数也可以表达字符串(比如名字或日期)和特定格式的浮点数,所以基数排序也不是只能使用于整数。
桶排序:
思想:是将阵列分到有限数量的桶子里。每个桶子再个别排序(有可能再使用别的排序算法或是以递回方式继续使用桶排序进行排序)。桶排序是鸽巢排序的一种归纳结果。当要被排序的阵列内的数值是均匀分配的时候,桶排序使用线性时间(Θ(n))。但桶排序并不是比较排序,他不受到 O(n log n) 下限的影响。
简单来说,就是把数据分组,放在一个个的桶中,然后对每个桶里面的在进行排序。
稳定排序