安装过程及配置
-
安装过程准备:
下载好Python的安装程序后,开始安装,在进入安装界面后一定确保勾选将Python加入到系统环境变量的路径里。如图所示:

-
如果没有选取,那么按照下面的步骤进行操作。在桌面上用鼠标右键点击我的电脑并选择属性选项。如图所示:

-
在弹出的属性设置菜单中点击高级系统设置。如图所示:

-
在高级系统设置面板中点击环境变量。如图所示:

-
在弹出的环境变量设置中找到系统环境变量设置,并选中path选项,双击,或者点击编辑选项。如图所示:

-
在弹出的编辑窗口中,新建一个环境变量为python安装路径。添加后进行保存并退出。如图所示:

1,运行第一段python代码。
在d盘下创建一个t1.py文件内容是:
print('hello world')打开windows命令行输入cmd,确定后 写入代码python d:t1.py
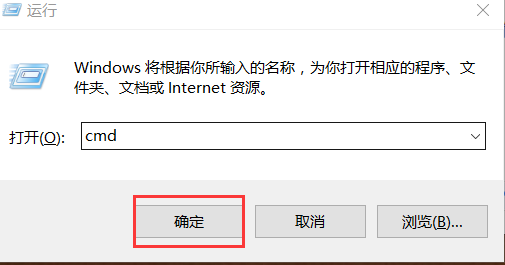

您已经运行了第一个python程序, 即:终端---->cmd-----> python 文件路径。 回车搞定~
2,解释器。
上一步中执行 python d:t1.py 时,明确的指出 t1.py 脚本由 python 解释器来执行。
如果想要类似于执行shell脚本一样执行python脚本,例:
./t1.py,那么就需要在 hello.py 文件的头部指定解释器,如下:123#!/usr/bin/env pythonprint"hello,world"如此一来,执行: .
/t1.py即可。ps:执行前需给予t1.py 执行权限,chmod 755 t1.py
3,内容编码。
python2解释器在加载 .py 文件中的代码时,会对内容进行编码(默认ascill),而python3对内容进行编码的默认为utf-8。
ASCII(American Standard Code for Information Interchange,美国标准信息交换代码)是基于拉丁字母的一套电脑编码系统,主要用于显示现代英语和其他西欧语言,其最多只能用 8 位来表示(一个字节),即:2**8 = 256,所以,ASCII码最多只能表示 256 个符号。
Bin(二进制)Oct(八进制) Dec(十进制)Hex(十六进制)缩写/字符解释0000 00000000NUL(null)空字符0000 00011101SOH(start of headline)标题开始0000 00102202STX (start of text)正文开始0000 00113303ETX (end of text)正文结束0000 01004404EOT (end of transmission)传输结束0000 01015505ENQ (enquiry)请求0000 01106606ACK (acknowledge)收到通知0000 01117707BEL (bell)响铃0000 100010808BS (backspace)退格0000 100111909HT (horizontal tab)水平制表符0000 101012100ALF (NL line feed, new line)换行键0000 101113110BVT (vertical tab)垂直制表符0000 110014120CFF (NP form feed, new page)换页键0000 110115130DCR (carriage return)回车键0000 111016140ESO (shift out)不用切换0000 111117150FSI (shift in)启用切换0001 0000201610DLE (data link escape)数据链路转义0001 0001211711DC1 (device control 1)设备控制10001 0010221812DC2 (device control 2)设备控制20001 0011231913DC3 (device control 3)设备控制30001 0100242014DC4 (device control 4)设备控制40001 0101252115NAK (negative acknowledge)拒绝接收0001 0110262216SYN (synchronous idle)同步空闲0001 0111272317ETB (end of trans. block)结束传输块0001 1000302418CAN (cancel)取消0001 1001312519EM (end of medium)媒介结束0001 101032261ASUB (substitute)代替0001 101133271BESC (escape)换码(溢出)0001 110034281CFS (file separator)文件分隔符0001 110135291DGS (group separator)分组符0001 111036301ERS (record separator)记录分隔符0001 111137311FUS (unit separator)单元分隔符0010 0000403220(space)空格0010 0001413321!叹号 0010 0010423422"双引号 0010 0011433523#井号 0010 0100443624$美元符 0010 0101453725%百分号 0010 0110463826&和号 0010 0111473927'闭单引号 0010 1000504028(开括号0010 1001514129)闭括号0010 101052422A*星号 0010 101153432B+加号 0010 110054442C,逗号 0010 110155452D-减号/破折号 0010 111056462E.句号 0010111157472F/斜杠 001100006048300数字0 001100016149311数字1 001100106250322数字2 001100116351333数字3 001101006452344数字4 001101016553355数字5 001101106654366数字6 001101116755377数字7 001110007056388数字8 001110017157399数字9 0011101072583A:冒号 0011101173593B;分号 0011110074603C<小于 0011110175613D=等号 0011111076623E>大于 0011111177633F?问号 010000001006440@电子邮件符号 010000011016541A大写字母A 010000101026642B大写字母B 010000111036743C大写字母C 010001001046844D大写字母D 010001011056945E大写字母E 010001101067046F大写字母F 010001111077147G大写字母G 010010001107248H大写字母H 010010011117349I大写字母I 01001010112744AJ大写字母J 01001011113754BK大写字母K 01001100114764CL大写字母L 01001101115774DM大写字母M 01001110116784EN大写字母N 01001111117794FO大写字母O 010100001208050P大写字母P 010100011218151Q大写字母Q 010100101228252R大写字母R 010100111238353S大写字母S 010101001248454T大写字母T 010101011258555U大写字母U 010101101268656V大写字母V 010101111278757W大写字母W 010110001308858X大写字母X 010110011318959Y大写字母Y 01011010132905AZ大写字母Z 01011011133915B[开方括号 01011100134925C反斜杠 01011101135935D]闭方括号 01011110136945E^脱字符 01011111137955F_下划线 011000001409660`开单引号 011000011419761a小写字母a 011000101429862b小写字母b 011000111439963c小写字母c 0110010014410064d小写字母d 0110010114510165e小写字母e 0110011014610266f小写字母f 0110011114710367g小写字母g 0110100015010468h小写字母h 0110100115110569i小写字母i 011010101521066Aj小写字母j 011010111531076Bk小写字母k 011011001541086Cl小写字母l 011011011551096Dm小写字母m 011011101561106En小写字母n 011011111571116Fo小写字母o 0111000016011270p小写字母p 0111000116111371q小写字母q 0111001016211472r小写字母r 0111001116311573s小写字母s 0111010016411674t小写字母t 0111010116511775u小写字母u 0111011016611876v小写字母v 0111011116711977w小写字母w 0111100017012078x小写字母x 0111100117112179y小写字母y 011110101721227Az小写字母z 011110111731237B{开花括号 011111001741247C|垂线 011111011751257D}闭花括号 011111101761267E~波浪号 011111111771277FDEL (delete)删除显然ASCII码无法将世界上的各种文字和符号全部表示,所以,就需要新出一种可以代表所有字符和符号的编码,即:Unicode
Unicode(统一码、万国码、单一码)是一种在计算机上使用的字符编码。Unicode 是为了解决传统的字符编码方案的局限而产生的,它为每种语言中的每个字符设定了统一并且唯一的二进制编码,规定虽有的字符和符号最少由 16 位来表示(2个字节),即:2 **16 = 65536,
注:此处说的的是最少2个字节,可能更多UTF-8,是对Unicode编码的压缩和优化,他不再使用最少使用2个字节,而是将所有的字符和符号进行分类:ascii码中的内容用1个字节保存、欧洲的字符用2个字节保存,东亚的字符用3个字节保存...
所以,python解释器在加载 .py 文件中的代码时,会对内容进行编码(默认ascill),如果是如下代码的话:
报错:ascii码无法表示中文
123#!/usr/bin/env pythonprint"你好,世界"改正:应该显示的告诉python解释器,用什么编码来执行源代码,即:
1234#!/usr/bin/env python# -*- coding: utf-8 -*-print"你好,世界"4,注释。
当行注释:# 被注释内容
多行注释:'''被注释内容''',或者"""被注释内容""
注释的原则:
①不用全部加注释,只需要在自己觉得重要或不好理解的部分加注释即可。 ②注释可以用中文或英文,但绝对不要用拼音。5,变量
变量是什么? 变量:把程序运行的中间结果临时的存在内存里,以便后续的代码调用。
5.1、声明变量
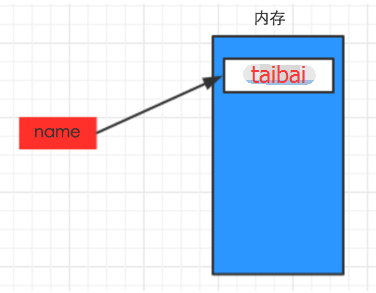
1234#!/usr/bin/env python# -*- coding: utf-8 -*-name="yefei"上述代码声明了一个变量,变量名为: name,变量name的值为:"yefei"
变量的作用:昵称,其代指内存里某个地址中保存的内容
5.2、变量定义的规则:
- 变量名只能是 字母、数字或下划线的任意组合
- 变量名的第一个字符不能是数字
- 以下关键字不能声明为变量名
['and', 'as', 'assert', 'break', 'class', 'continue', 'def', 'del', 'elif', 'else', 'except', 'exec', 'finally', 'for', 'from',
'global', 'if', 'import', 'in', 'is', 'lambda', 'not', 'or', 'pass', 'print', 'raise', 'return', 'try', 'while', 'with', 'yield'] - 变量的定义要具有可描述性。
5.3、推荐定义方式
#驼峰体 AgeOfYefei = 18 NumberOfStudents = 30 #下划线 age_of_yefei = 18 number_of_students = 30
你觉得哪种更清晰,哪种就是官方推荐的,我想你肯定会先第2种,第一种AgeOfOldboy咋一看以为是AngelaBaby
5.4、变量的赋值
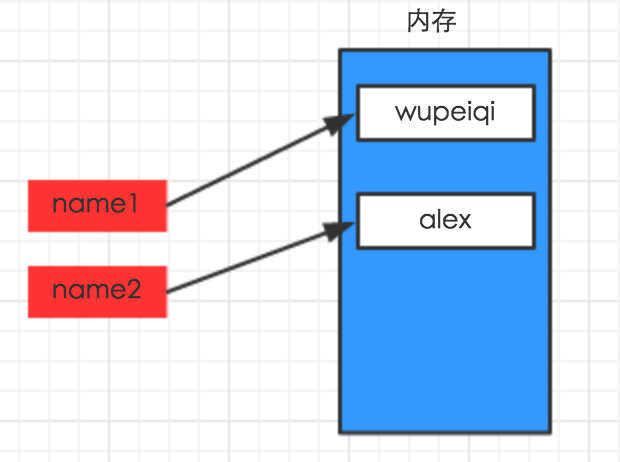
#!/usr/bin/env python # -*- coding: utf-8 -*- name1 = "fanying" name2 = "yefei"
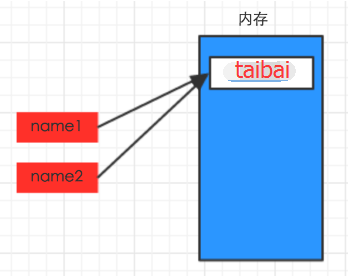
#!/usr/bin/env python # -*- coding: utf-8 -*- name1 = "taibai" name2 = name1
5.5、定义变量不好的方式举例
- 变量名为中文、拼音
- 变量名过长
- 变量名词不达意
6,常量
常量即指不变的量,如pai 3.141592653..., 或在程序运行过程中不会改变的量
举例,假如老男孩老师的年龄会变,那这就是个变量,但在一些情况下,他的年龄不会变了,那就是常量。在Python中没有一个专门的语法代表常量,程序员约定俗成用变量名全部大写代表常量
AGE_OF_YEFEI = 18在c语言中有专门的常量定义语法,
const int count = 60;一旦定义为常量,更改即会报错7,程序交互
#!/usr/bin/env python # -*- coding: utf-8 -*- # 将用户输入的内容赋值给 name 变量 name = input("请输入用户名:") # 打印输入的内容 print(name)执行脚本就会发现,程序会等待你输入姓名后再往下继续走。
可以让用户输入多个信息,如下
#!/usr/bin/env python # -*- coding: utf-8 -*-
name = input("What is your name?") age = input("How old are you?") hometown = input("Where is your hometown?") print("Hello ",name , "your are ", age , "years old, you came from",hometown)8,基础数据类型(初始)。
什么是数据类型?
我们人类可以很容易的分清数字与字符的区别,但是计算机并不能呀,计算机虽然很强大,但从某种角度上看又很傻,除非你明确的告诉它,1是数字,“汉”是文字,否则它是分不清1和‘汉’的区别的,因此,在每个编程语言里都会有一个叫数据类型的东东,其实就是对常用的各种数据类型进行了明确的划分,你想让计算机进行数值运算,你就传数字给它,你想让他处理文字,就传字符串类型给他。Python中常用的数据类型有多种,今天我们暂只讲3种, 数字、字符串、布尔类型
8.1、整数类型(int)。
int(整型)
在32位机器上,整数的位数为32位,取值范围为-2**31~2**31-1,即-2147483648~2147483647
在64位系统上,整数的位数为64位,取值范围为-2**63~2**63-1,即-9223372036854775808~9223372036854775807
long(长整型)
跟C语言不同,Python的长整数没有指定位宽,即:Python没有限制长整数数值的大小,但实际上由于机器内存有限,我们使用的长整数数值不可能无限大。
注意,自从Python2.2起,如果整数发生溢出,Python会自动将整数数据转换为长整数,所以如今在长整数数据后面不加字母L也不会导致严重后果了。
注意:在Python3里不再有long类型了,全都是int
>>> a= 2**64 >>> type(a) #type()是查看数据类型的方法 <type 'long'> >>> b = 2**60 >>> type(b) <type 'int'>
除了int和long之外, 其实还有float浮点型, 复数型,但今天先不讲啦
8.2、字符串类型(str)。
在Python中,加了引号的字符都被认为是字符串!
>>> name = "Alex Li" #双引号 >>> age = "22" #只要加引号就是字符串 >>> age2 = 22 #int >>> >>> msg = '''My name is taibai, I am 22 years old!''' #我擦,3个引号也可以 >>> >>> hometown = 'ShanDong' #单引号也可以
那单引号、双引号、多引号有什么区别呢? 让我大声告诉你,单双引号木有任何区别,只有下面这种情况 你需要考虑单双的配合
msg = "My name is Alex , I'm 22 years old!"多引号什么作用呢?作用就是多行字符串必须用多引号
msg = ''' 今天我想写首小诗, 歌颂我的同桌, 你看他那乌黑的短发, 好像一只炸毛鸡。 ''' print(msg)
字符串拼接
数字可以进行加减乘除等运算,字符串呢?让我大声告诉你,也能?what ?是的,但只能进行"相加"和"相乘"运算。
>>> name 'Alex Li' >>> age '22' >>> >>> name + age #相加其实就是简单拼接 'Alex Li22' >>> >>> name * 10 #相乘其实就是复制自己多少次,再拼接在一起 'Alex LiAlex LiAlex LiAlex LiAlex LiAlex LiAlex LiAlex LiAlex LiAlex Li'
注意,字符串的拼接只能是双方都是字符串,不能跟数字或其它类型拼接
>>> type(name),type(age2) (<type 'str'>, <type 'int'>) >>> >>> name 'Alex Li' >>> age2 22 >>> name + age2 Traceback (most recent call last): File "<stdin>", line 1, in <module> TypeError: cannot concatenate 'str' and 'int' objects #错误提示数字 和 字符 不能拼接
8.3、布尔值(True,False)。
布尔类型很简单,就两个值 ,一个True(真),一个False(假), 主要用记逻辑判断
但其实你们并不明白对么? let me explain, 我现在有2个值 , a=3, b=5 , 我说a>b你说成立么? 我们当然知道不成立,但问题是计算机怎么去描述这成不成立呢?或者说a< b是成立,计算机怎么描述这是成立呢?
没错,答案就是,用布尔类型
>>> a=3 >>> b=5 >>> >>> a > b #不成立就是False,即假 False >>> >>> a < b #成立就是True, 即真 True
9,格式化输出。
现有一练习需求,问用户的姓名、年龄、工作、爱好 ,然后打印成以下格式
------------ info of Yefei ----------- Name : Yefei Age : 18 job : Farmer Hobbie: Watching TV ------------- end -----------------
你怎么实现呢?你会发现,用字符拼接的方式还难实现这种格式的输出,所以一起来学一下新姿势
只需要把要打印的格式先准备好, 由于里面的 一些信息是需要用户输入的,你没办法预设知道,因此可以先放置个占位符,再把字符串里的占位符与外部的变量做个映射关系就好啦
name = input("Name:") age = input("Age:") job = input("Job:") hobbie = input("Hobbie:") info = ''' ------------ info of %s ----------- #这里的每个%s就是一个占位符,本行的代表 后面拓号里的 name Name : %s #代表 name Age : %s #代表 age job : %s #代表 job Hobbie: %s #代表 hobbie ------------- end ----------------- ''' %(name,name,age,job,hobbie) # 这行的 % 号就是 把前面的字符串 与拓号 后面的 变量 关联起来 print(info)%s就是代表字符串占位符,除此之外,还有%d,是数字占位符, 如果把上面的age后面的换成%d,就代表你必须只能输入数字啦
age : %d我们运行一下,但是发现出错了。。。
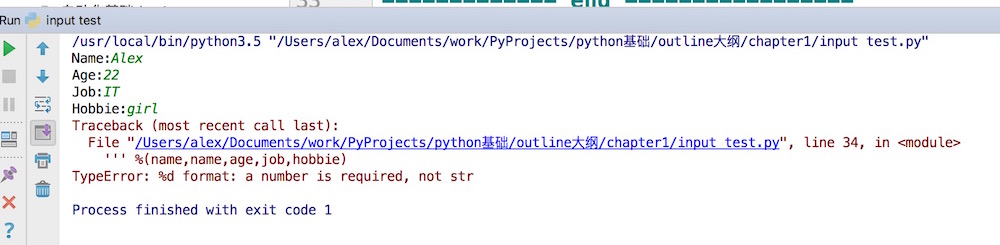
说%d需要一个数字,而不是str, what? 我们明明输入的是数字呀,22,22呀。
不用担心 ,不要相信你的眼睛我们调试一下,看看输入的到底是不是数字呢?怎么看呢?查看数据类型的方法是什么来着?type()
name = input("Name:") age = input("Age:") print(type(age))执行输出是
Name:Yefei Age:18 <class 'str'> #怎么会是str Job:Farmer让我大声告诉你,input接收的所有输入默认都是字符串格式!
要想程序不出错,那怎么办呢?简单,你可以把str转成int
age = int( input("Age:") ) print(type(age))肯定没问题了。相反,能不能把字符串转成数字呢?必然可以,
str( yourStr )问题:现在有这么行代码
msg = "我是%s,年龄%d,目前学习进度为80%"%('yefei',18) print(msg)这样会报错的,因为在格式化输出里,你出现%默认为就是占位符的%,但是我想在上面一条语句中最后的80%就是表示80%而不是占位符,怎么办?
msg = "我是%s,年龄%d,目前学习进度为80%%"%('yefei',18) print(msg)这样就可以了,第一个%是对第二个%的转译,告诉Python解释器这只是一个单纯的%,而不是占位符。