普通的hash算法在分布式应用中的不足
在分布式的存储系统中,要将数据存储到具体的节点上,如果我们采用普通的hash算法进行路由,将数据映射到具体的节点上,如key%N,key是数据的key,N是机器节点数,如果有一个机器加入或退出这个集群,则所有的数据映射都无效了,如果是持久化存储则要做数据迁移,如果是分布式缓存,则其他缓存就失效了
一致性hash算法
- 均衡性(Balance)
- 单调性(Monotonicity)
- 分散性(Spread)
- 负载(Load)
环形hash空间

按照常用的hash算法来将对应的key哈希到一个具有2^32次方个节点的空间中,即0 ~ (2^32)-1的数字空间中。现在我们可以将这些数字头尾相连,想象成一个闭合的环形
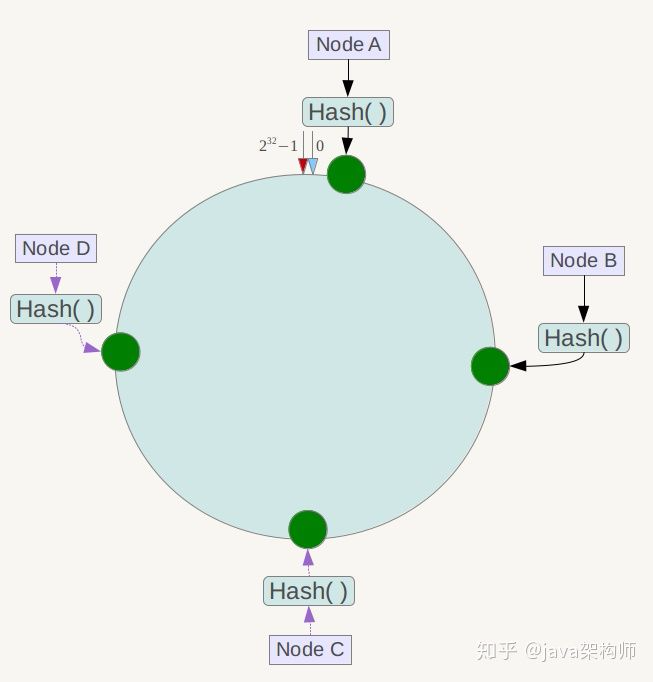
映射服务器节点
将各个服务器使用Hash进行一个哈希,具体可以选择服务器的ip或唯一主机名作为关键字进行哈希,这样每台机器就能确定其在哈希环上的位置
映射数据
现在我们将objectA、objectB、objectC、objectD四个对象通过特定的Hash函数计算出对应的key值,然后散列到Hash环上,然后从数据所在位置沿环顺时针“行走”,第一台遇到的服务器就是其应该定位到的服务器

服务器的删除与添加
如果此时NodeC宕机了,此时Object A、B、D不会受到影响,只有Object C会重新分配到Node D上面去,而其他数据对象不会发生变化

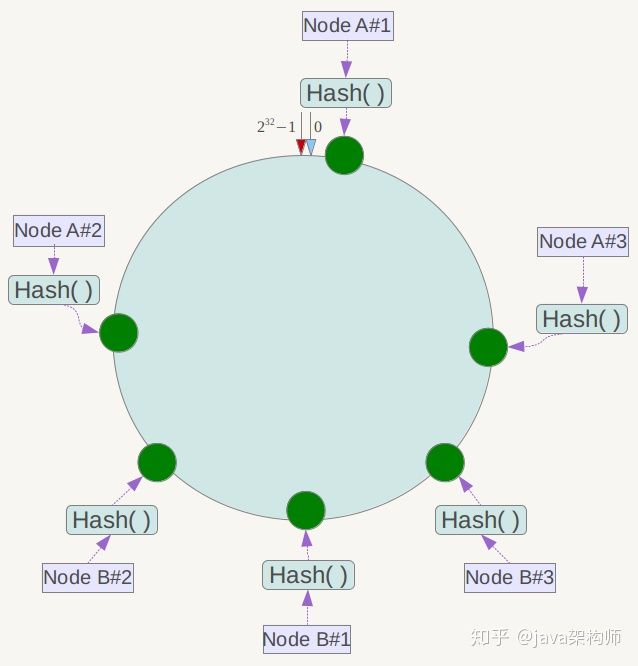
虚拟节点
为了解决这种数据倾斜问题,一致性哈希算法引入了虚拟节点机制,即对每一个服务节点计算多个哈希,每个计算结果位置都放置一个此服务节点,称为虚拟节点。具体做法可以先确定每个物理节点关联的虚拟节点数量,然后在ip或者主机名后面增加编号。例如上面的情况,可以为每台服务器计算三个虚拟节点,于是可以分别计算 “Node A#1”、“Node A#2”、“Node A#3”、“Node B#1”、“Node B#2”、“Node B#3”的哈希值,于是形成六个虚拟节点