HashMap源码分析(jdk 7)
1.创建一个map对象
HashMap map = new HashMap(); //底层创建了长度是16的一维数组Entry[] table
底层实现:HashMap.java
transient Entry<K,V>[] table; //Entry类型的底层数组table
第一步:调用无参构造器
public HashMap() {
this(DEFAULT_INITIAL_CAPACITY,DEFAULT_LOAD_FACTOR); //调用当前的重载构造器
}
DEFAULT_INITIAL_CAPACITY:默认初始容量为16。
DEFAULT_LOAD_FACTOR:默认的加载因子为0.75。
第二步:调用本类的重载构造器
public HashMap(int initialCapacity, float loadFactor) {
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal initial capacity: " +
initialCapacity);
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal load factor: " +
loadFactor);
int capacity = 1;
while(capacity < initialCapacity)
capacity <<= 1; //capacity左移一位1,2,4,8,16,它决定了底层创建数组的长度,一定是2的多少次幂
this.loadFactor = loadFactor;
threshold = (int)Math.min(capacity * loadFactor,MAXIMUM_CAPACITY + 1); //12 = 16 * 0.75
table = new Entry[capacity]; //创建了底层长度为16的数组赋给table
}
-
注意HashMap map = new HashMap(15);底层并不一定是创建长度为15的数组
-
threshold:临界值12。它影响着扩容。当底层创建了长度为16的数组时,它并不是添加第17个时才进行扩容,原因是数组的元素有可能永远存不满(有些位置上的元素是以链表的形式存储的)。这里是否扩容要看threshold临界值,超过12就要进行扩容
2.添加数据,put( )方法
map.put(key1,value1);
底层实现:HashMap.java
第一步:调用put()
public V put(K key, V value) {
if(key == null) //这里说明了HashMap的key可以为空值
return putForNullKey(value);
int hash = hash(key); //计算哈希值,hash()中调用了hashCode()方法
int i = indexFor(hash,table.length); //此哈希值经过某种算法计算以后,得到在Entry数组中的存放位置
for(Entry<K,V> e = table[i]; e != null; e = e.next){
/*拿出i位置上的元素,判空,e = e.next相当于将i位置上的链表走一遍*/
Object k;
if( e.hash == hash && ((e.key = key) == key) || key.equals(k))){//比较哈希值、key的地址、key所对应的数据
V oldValue = e.value;
e.value = value; // 用value1替换已存在数据e的value
e.recordAccess(m:this);
return oldValue;
}
}
modCount++;
addEntry(hash,key,value,i);
return null;
}
第一种情况:i位置上的数据为空即e = null时,跳过for,执行addEntry(hash,key,value,i),数据key1-value1添加成功。
- hash:当前添加的数据key1的哈希值
- key:当前添加的数据key1
- value:当前添加的数据value1
- i:当前添加的数据在数组中存放的位置
第二种情况:i位置上的数据不为空,key1的哈希值和已经存在的数据的哈希值都不相同,跳出for,执行addEntry(hash,key,value,i),数据key1-value1添加成功。
第三种情况:i位置上的数据不为空,key1的哈希值和已经存在的数据的哈希值相同,
-
(e.key = key) == key) || key.equals(k)返回false,跳出false,执行addEntry(hash,key,value,i),数据key1-value1添加成功。
-
(e.key = key) == key) || key.equals(k)返回true,执行e.value = value; 用value1替换已存在数据e的value。
第二步:调用addEntry()
void addEntry(int hash,K key,V value,int bucketIndex){
if((size >= threshold) && (null != table[bucketIndex])){ //扩容的条件:超出临界值(且要存放的位置非空)时
resize(newCapacity:2*table.length); //扩容为原来的2倍
/*这里需要重新计算原来数组中数据在新的数组中的存放位置,可能原来在链表中,新数组中变为在数组上*/
hash = (null != key)?hash(key):0;
bucketIndex = indexFor(hash,table.length);
}
//不需要扩容时,执行createEntry()
createEntry(hash,key,value,bucketIndex);
}
第三步:不需要扩容时,调用createEntry(),直接进行添加。
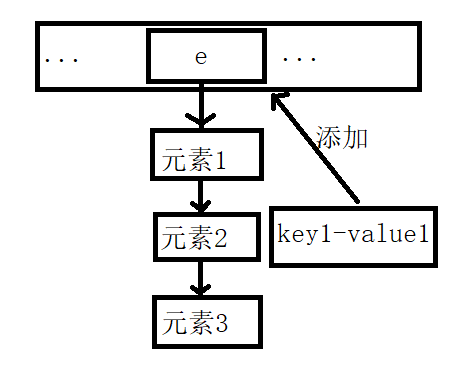
void createEntry(int hash,K key,V value,int bucketIndex){
Entry<K,V> e = table[bucketIndex]; //先将原来位置上的元素取出
table[bucketIndex] = new Entry<>(hash,key,value,e);
size++;
}
解释:table[bucketIndex] = new Entry<>(hash,key,value,e);将原来bucketIndex位置上的数据作为新添加数据的next出现,然后将新添加的数据key1-value1放在bucketIndex位置上。如图所示
添加前 添加后