首先,从问题出发:
在谷歌学术镜像网收集着多个谷歌镜像的链接。我们目标就是要把这些链接拿到手。
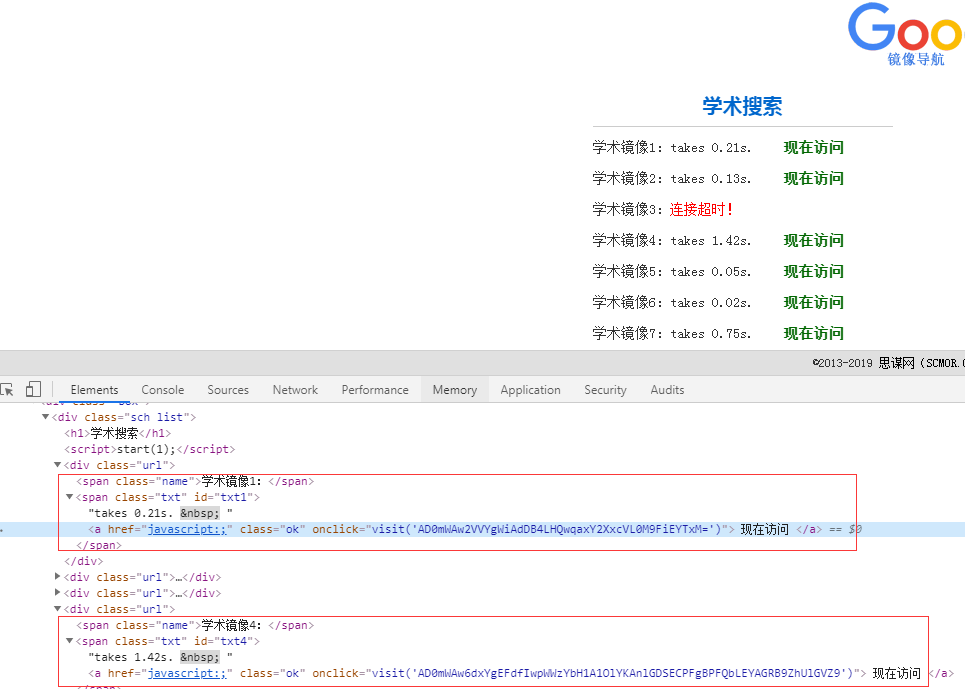
F12查看源码可以发现,对应的a标签并不是我们想要的链接,而是一个js点击函数。
其实在
onclick="visit('AD0mWAw2VVYgWiAdDB4LHQwqaxY2XxcVL0M9FiEYTxM=')"
上面一段代码里,AD0mWAw2VVYgWiAdDB4LHQwqaxY2XxcVL0M9FiEYTxM=就是加密后的url链接。
visit函数的作用就是对这一串字符串进行了解密并访问。
通过搜索我们可以清楚visit函数它的源码:
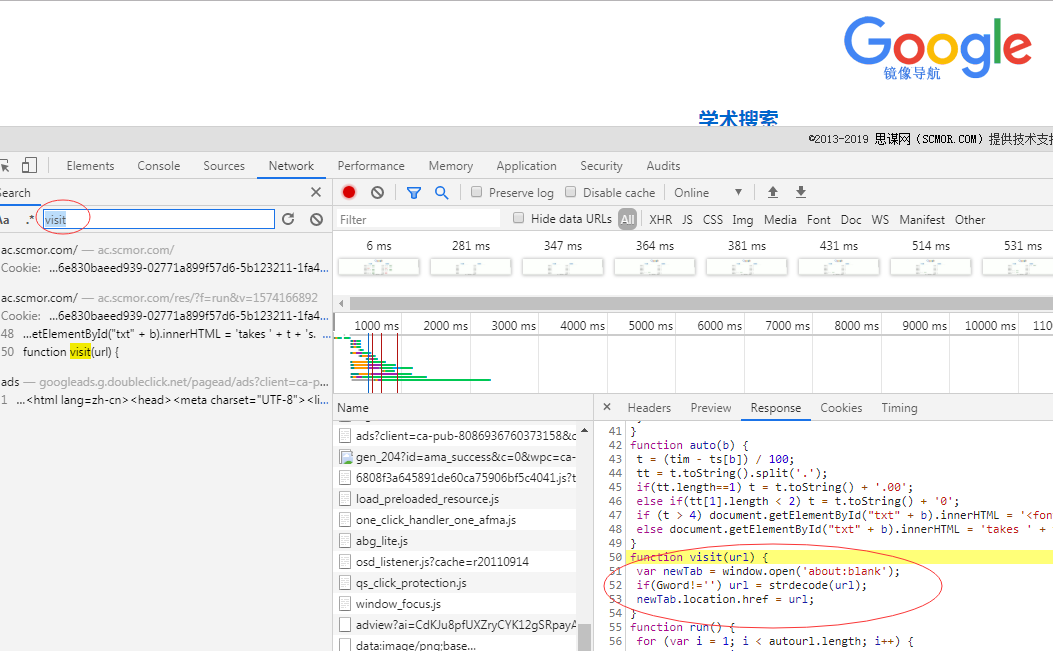
就是这一段:
function visit(url) { var newTab = window.open('about:blank'); //打开新窗口 if(Gword!='') url = strdecode(url);//解密字符串,将它变成url newTab.location.href = url;//访问这个url }
ok,又扯出来一个叫strdecode的函数,我们继续找找看:

function strdecode(string) { string = base64decode(string);//base64decode函数处理参数 key = Gword + hn;//Gword和hn两个变量可以在网页源码找到 len = key.length;//key的长度 code = ''; for (i = 0; i < string.length; i++) {//这个循环是中间的解密过程 var k = i % len; code += String.fromCharCode(string.charCodeAt(i) ^ key.charCodeAt(k)); } return base64decode(code);//再利用base64decode处理一次中间过程产出的code变量,其实这个就是真正的url了 }
其实sredecode的参数string就是类似一开始说的"AD0mWAw2VVYgWiAdDB4LHQwqaxY2XxcVL0M9FiEYTxM="
又有一个叫base64decode的函数,那我们再找找看:

ok,好长一段js代码。我都不想去理解它了、、
怎么办?
咱可以利用python的execjs库来执行js代码,只需把js代码保存下来就好。那我们把能用到的js都给保存下来像这样:
execjs安装:pip install PyExecJS
var base64DecodeChars = new Array(-1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, 62, -1, -1, -1, 63, 52, 53, 54, 55, 56, 57, 58, 59, 60, 61, -1, -1, -1, -1, -1, -1, -1, 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, -1, -1, -1, -1, -1, -1, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48, 49, 50, 51, -1, -1, -1, -1, -1); function base64decode(str) { var c1, c2, c3, c4; var i, len, out; len = str.length; i = 0; out = ""; while (i < len) { do { c1 = base64DecodeChars[str.charCodeAt(i++) & 0xff] } while (i < len && c1 == -1); if (c1 == -1) break; do { c2 = base64DecodeChars[str.charCodeAt(i++) & 0xff] } while (i < len && c2 == -1); if (c2 == -1) break; out += String.fromCharCode((c1 << 2) | ((c2 & 0x30) >> 4)); do { c3 = str.charCodeAt(i++) & 0xff; if (c3 == 61) return out; c3 = base64DecodeChars[c3] } while (i < len && c3 == -1); if (c3 == -1) break; out += String.fromCharCode(((c2 & 0XF) << 4) | ((c3 & 0x3C) >> 2)); do { c4 = str.charCodeAt(i++) & 0xff; if (c4 == 61) return out; c4 = base64DecodeChars[c4] } while (i < len && c4 == -1); if (c4 == -1) break; out += String.fromCharCode(((c3 & 0x03) << 6) | c4) } return out } function strdecode(string) { string = base64decode(string); key = "author: link@scmor.com.ac.scmor.com"; len = key.length; code = ''; for (i = 0; i < string.length; i++) { var k = i % len; code += String.fromCharCode(string.charCodeAt(i) ^ key.charCodeAt(k)); } return base64decode(code); }
然后利用python请求网页源码,把AD0mWAw2VVYgWiAdDB4LHQwqaxY2XxcVL0M9FiEYTxM=这些密文用re匹配出来。
最后利用上面保存的js代码解密:
最终代码(PS:也放在github上面了,博客左上角点击直达):
import requests from lxml import etree import re import execjs
with open('scmor.js', 'r', encoding='utf-8') as f: js = f.read() ctx = execjs.compile(js) #编译保存的js def get_html(): #请求html try: r = requests.get("http://ac.scmor.com/") r.encoding = r.apparent_encoding return r.text except: print('产生异常') def parse_html(html): #解析html,并用re匹配密文 tree = etree.HTML(html) script_text = tree.xpath('//script/text()')[0] autourls = re.findall(r'AD0mWAw[a-zA-Z0-9]+=*', script_text) return autourls def decode(string): #利用保存的js解密密文 return ctx.call('strdecode', string) if __name__ == '__main__': html = get_html() autourls = parse_html(html) for url in autourls: print(decode(url)) #print(decode('AD0mWAw2VVYgWiAdDB4LHQwqaxY2XxcVL0M9FiEYTxM=')) #decode将源码中的加密字符串转url
参考文章:https://www.cnblogs.com/happymeng/p/10755244.html
The end~