分词技术目前已经在机器翻译领域广泛使用。今天我们说说分句。
分句的作用主要用在,当我们给翻译引擎一大段文字的时候,它很有可能就搞不定了,因为一般需要将分句后的句子送给引擎,引擎在翻译完后再将结果拼起来。
这里找到一个开源的分句,我们一起来看看它:
https://github.com/Tessmore/sbd
安装node的过程我这里就不说了,需要说的一点是,安装完后,我们在这里打开命令行:
打开命令行后,运行 npm install sbd
新建一个js脚本,代码如下:
var tokenizer = require('sbd'); var text = "On Jan. 20, former Sen. Barack Obama became the 44th President of the U.S. Millions attended the Inauguration."; var sentences = tokenizer.sentences(text); console.log(sentences)
我们运行下直接输出:
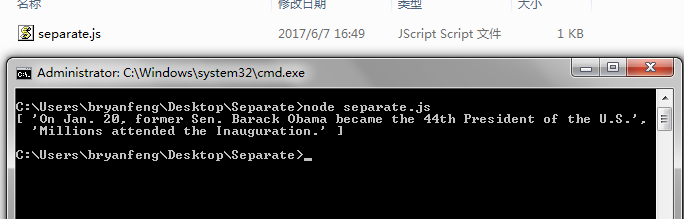
可以看到这句话分句成功了,且成功避开了日期当中的标点已经专有名词缩写的标点。
python版本
首先拿到我的压缩包。
先通过源码安装这两个库
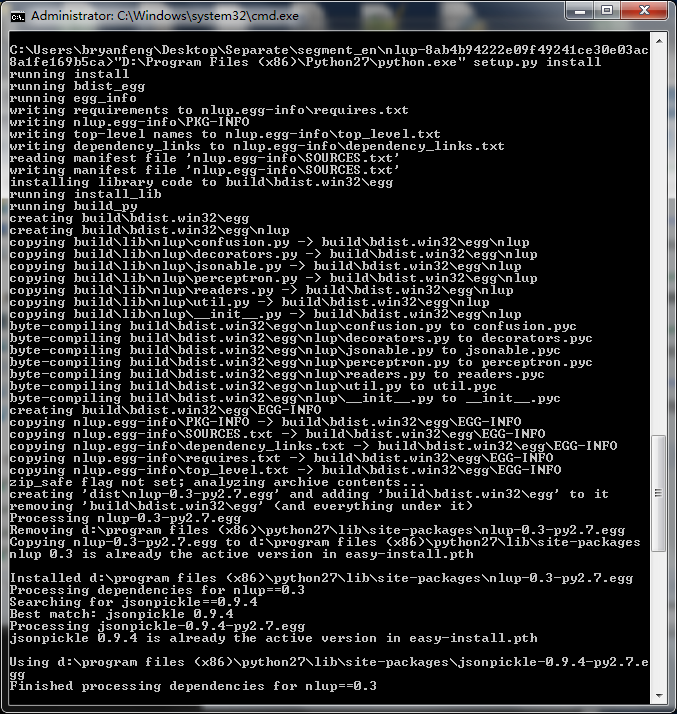
python setup.py install
装完后发现在python的目录下多了 **。egg文件
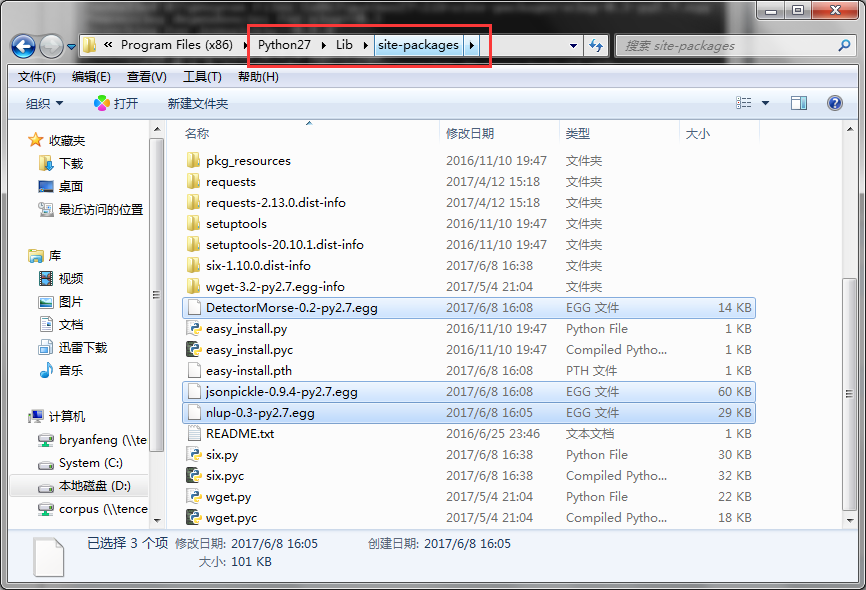
此时只需要把egg文件加压即可。
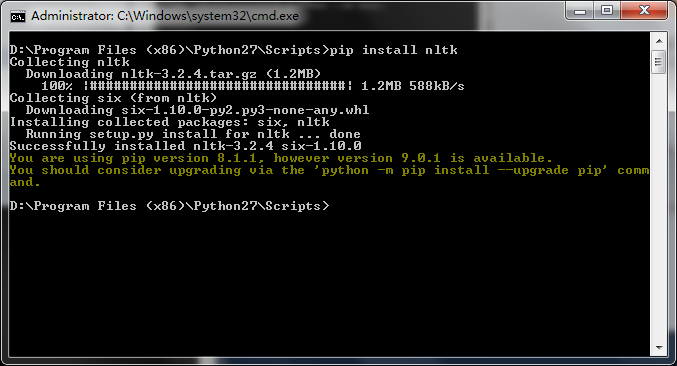
最后再通过pip安装一个nltk即可
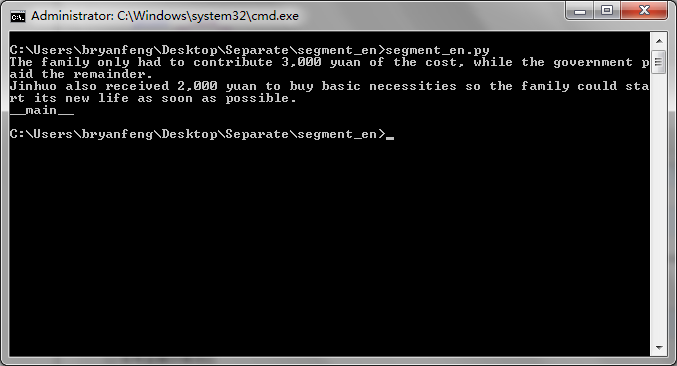
此时我们用以下代码运行一下
#coding = utf-8 from nlup.decorators import IO from detectormorse import Detector if __name__ == '__main__': detector = IO(Detector.load)('./DetectorMorse/DM-wsj.json.gz') print(" ".join(detector.segments("The family only had to contribute 3,000 yuan of the cost, while the government paid the remainder. Jinhuo also received 2,000 yuan to buy basic necessities so the family could start its new life as soon as possible."))) print __name__
就可以得到分句的结果: