◆版权声明:本文出自胖喵~的博客,转载必须注明出处。
转载请注明出处:http://www.cnblogs.com/by-dream/p/6554340.html
前言
google的翻译不得不承认它是比较好的。但是google翻译对外提供的翻译接口都是收钱的,做为一名普普通通的开发者,囊中羞涩,因此就需要借助技术的力量来完成免费的翻译接口的调用。
git
首先在github上我们找到了这篇链接 https://github.com/ssut/py-googletrans

看介绍免费、无限制,这刚好适合我们来用。于是按照它的操作步骤我们来试试:
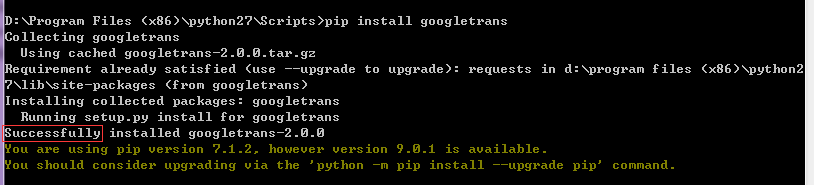
由于它是python的,因此第一步是去下载它的python库,由于我没有配置python pip的环境变量,因此我手动进入这个目录下:
然后运行 pip install googletrans 这个命令,去下载提供的这个库。
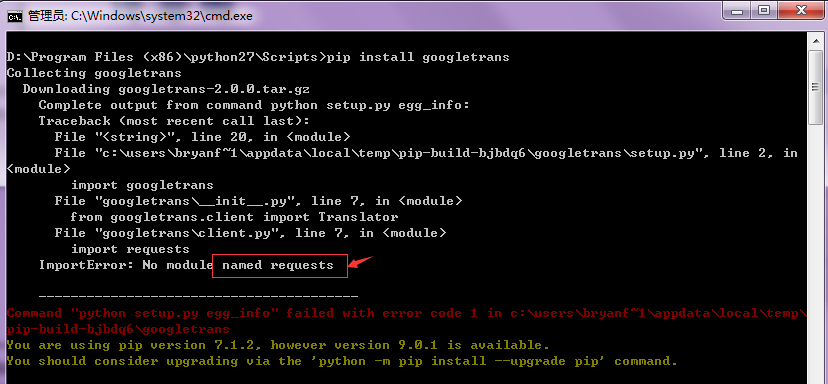
这个时候出错,提示我们没有requests库,因此我们还需要在安装requests库。果然文档里也有些
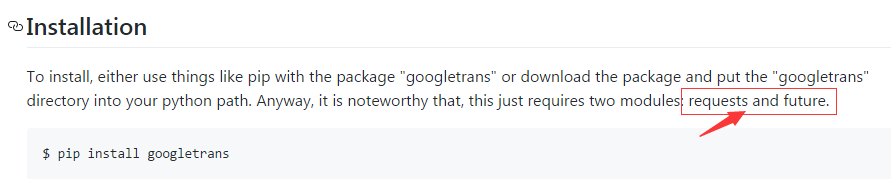
因此我们就安装把
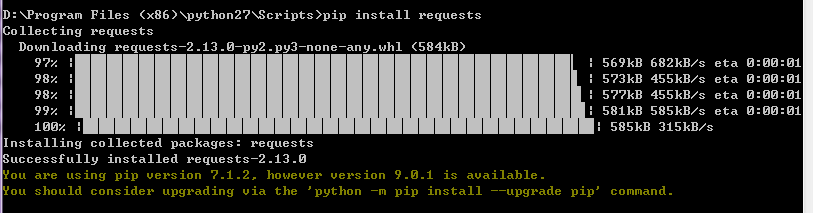
安装完后再安装googletrans 就可以了:
这个时候我们调用它API提供的方法试试,代码如下:
#-*- coding:utf-8 -*- from googletrans import Translator import sys reload(sys) sys.setdefaultencoding( "utf-8" ) translator = Translator() print translator.translate('今天天气不错').text print translator.translate('今天天气不错', dest='ja').text print translator.translate('今天天气不错', dest='ko').text
这个时候就可以看到输出结果:
the weather is nice today
今日天気がいいです
오늘 날씨가 좋은
一个简单的翻译demo就实现了。是不是非常的简单
然而,这个库并不是google官方提供的,并且有的时候这个库也是不稳定的,因为我决定自己去趟一下这趟浑水。
第一步当然是抓取它的请求,看看它是怎么请求的。按下F12进入浏览器调试模式,眼睛盯紧network:
接着我们输入一句话,看看它会产生什么消息包。
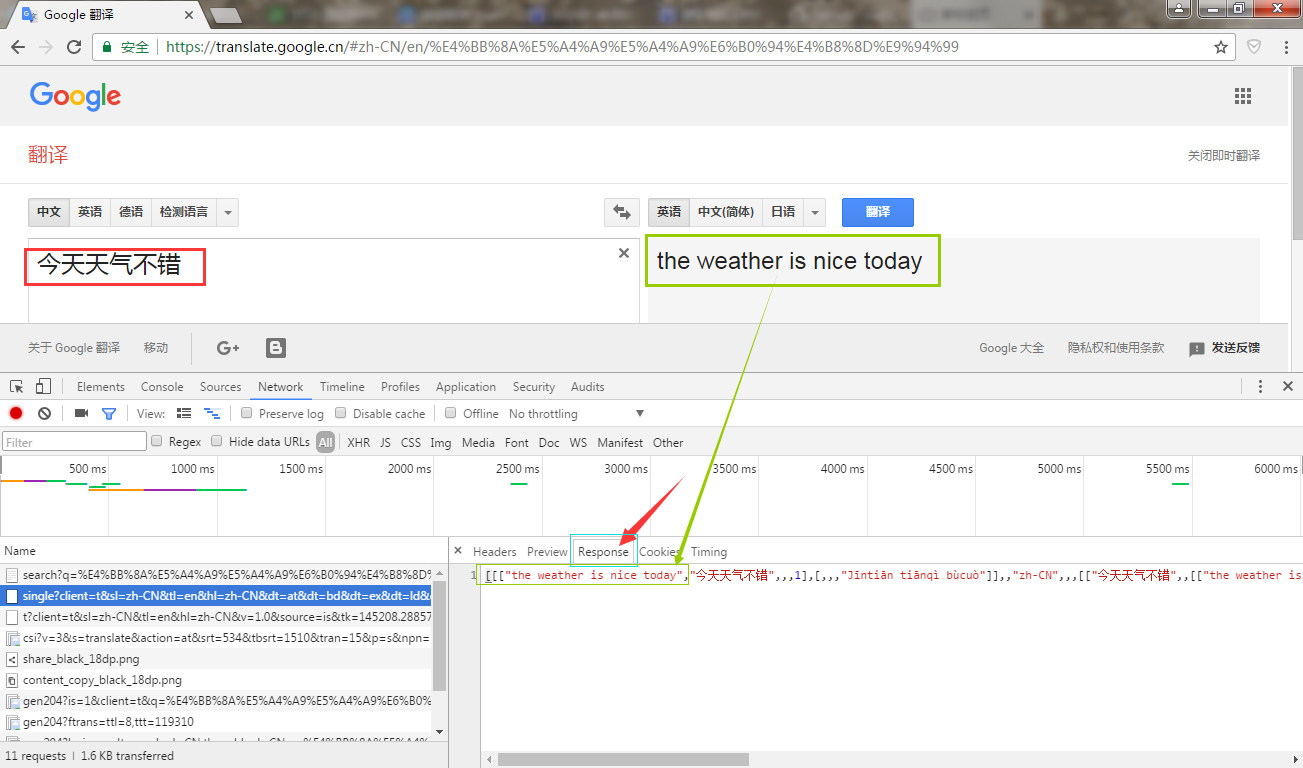
居然有这么多的消息包,我们一个一个找,直到找到Response中有翻译内容的。这个时候我们去看一下它的header:
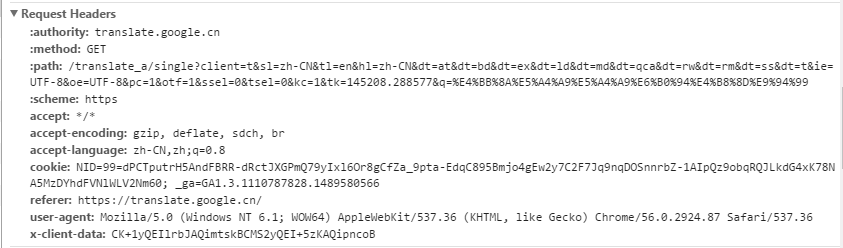
可以看到是get方式,于是我们可以浏览器里直接去请求这个url。
果然我们的得到了一个文件,这个时候打开文件,文件里就是请求回来的翻译结果:
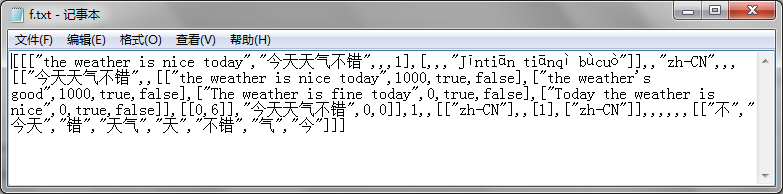
这时候我们去分析一下请求的参数,看看我们是否可以构造,可以看到原来要翻译的文本,就是跟着q这个参数出去的:
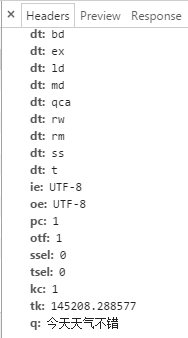
只不过在请求的时候,文字被encode成了%**%**,这时候我们试着换一个文字去请求,结果发现返回:

仔细上网查过之后,每次翻译的文字不同,参数中的tk值就会不同,ticket这种策略就是google用来防爬虫的。
tk和文字以及TKK有关,TKK也是实时变化的,具体怎么拿到是在 translate.google.cn 这个网页源代码中有一段js代码:

我们直接运行这段js,会得到一个值,这个值就是 TKK值:

那么如何根据TKK和文本算出tk值呢,网上有大神已经实现了js的代码,直接拿过来用了:
var b = function (a, b) { for (var d = 0; d < b.length - 2; d += 3) { var c = b.charAt(d + 2), c = "a" <= c ? c.charCodeAt(0) - 87 : Number(c), c = "+" == b.charAt(d + 1) ? a >>> c : a << c; a = "+" == b.charAt(d) ? a + c & 4294967295 : a ^ c } return a } var tk = function (a,TKK) { for (var e = TKK.split("."), h = Number(e[0]) || 0, g = [], d = 0, f = 0; f < a.length; f++) { var c = a.charCodeAt(f); 128 > c ? g[d++] = c : (2048 > c ? g[d++] = c >> 6 | 192 : (55296 == (c & 64512) && f + 1 < a.length && 56320 == (a.charCodeAt(f + 1) & 64512) ? (c = 65536 + ((c & 1023) << 10) + (a.charCodeAt(++f) & 1023), g[d++] = c >> 18 | 240, g[d++] = c >> 12 & 63 | 128) : g[d++] = c >> 12 | 224, g[d++] = c >> 6 & 63 | 128), g[d++] = c & 63 | 128) } a = h; for (d = 0; d < g.length; d++) a += g[d], a = b(a, "+-a^+6"); a = b(a, "+-3^+b+-f"); a ^= Number(e[1]) || 0; 0 > a && (a = (a & 2147483647) + 2147483648); a %= 1E6; return a.toString() + "." + (a ^ h) }
这段代码只需要直接调用 tk这个函数就可以得到tk值,得到tk值之后,我们就可以拼接出url来进行请求了。
Demo
这里我用Python和node一起完成了一个小的demo,大家可以下载我的代码。我简单介绍一下脚本的原理。
首先入口是用node完成的:
// 导入translate var trans= require('./translate.js'); // 调用翻译结果 trans.gettrans('你好')
直接调用了 translate.js,我们看看这个文件:


// 得到TKK var exec = require('child_process').exec; var cmdStr = 'getTKK.py'; exec(cmdStr, function(err,stdout,stderr){ if(err) { console.log('get TKK is error' + stderr); } else { //console.log(stdout); } }); // 读取TKK var rf=require("fs"); var tkk=rf.readFileSync("TKK","utf-8"); //console.log(tkk); var gettrans=function(text){ var gettk= require('./gettk.js') res=gettk.tk(text, tkk.toString()) //console.log(res) var testenc = encodeURI(text) //console.log(encodeURI(text)) var exec2 = require('child_process').exec; var cmdStr2 = 'http.py '+testenc+' '+res+' '; //console.log('http.py '+testenc+' '+res) exec2(cmdStr2, function(err,stdout,stderr){ if(err) { //console.log('http is error' + stderr); } else { // 最终的结果 console.log(stdout); } }); } module.exports.gettrans=gettrans;
translate.js 当中融合了比较多的内容,首先是调用Python的getTKK.py。
#-*- coding:utf-8 -*- import os # 爬取网页拿到TKK的js代码 os.system('getTKKjs.py > getTKK.js') # 执行TKKjs代码拿到TKK值 os.system('node getTKK.js > TKK')
我们可以看到原理很简单,先调用 getTKKjs.py 利用爬虫先将刚才我们分析的那段网页代码给爬取下来,然后生成js文件,接着调用这个js文件,将结果写入到本地一个文件TKK当中。紧接着translate.js读取了TKK值之后,调用我们前面提到的那段node的接口,就可以得到tk值了,这个时候再调用http.py送给Python进行请求,将结果回传给node。
#-*- coding:utf-8 -*- import urllib2 from bs4 import BeautifulSoup # 要爬取的总url weburl='http://translate.google.cn/' class Climbing(): # 设置代理开关 enable_proxy = False # 总url url = '' # 初始化 def __init__(self, url): self.url = url proxy_handler = urllib2.ProxyHandler({"http" : 'web-proxy.oa.com:8080'}) null_proxy_handler = urllib2.ProxyHandler({}) if self.enable_proxy: opener = urllib2.build_opener(proxy_handler) else: opener = urllib2.build_opener(null_proxy_handler) urllib2.install_opener(opener) # 根据url,得到请求返回内容的soup对象 def __getResponseSoup(self, url): request = urllib2.Request(url) request.add_header('User-Agent', "Mozilla/5.0") #request.add_header('Accept-Language', 'zh-ch,zh;q=0.5') response = urllib2.urlopen(request) resault = response.read() soup = BeautifulSoup(resault, "html.parser") return soup # 爬取TKK def getTKK(self): soup = self.__getResponseSoup(self.url) allinfo = soup.find_all('script') for info in allinfo: chinese = info.get_text().encode('utf-8') #print chinese if chinese.find("TKK") > 0: #print chinese res = chinese.split("TKK")[1] res = res.split(");")[0] print "TKK"+res+");" print "console.log(TKK);" c = Climbing(weburl) c.getTKK()
#-*- coding:utf-8 -*- import time import urllib2 import urllib from sys import argv script,zh,tk = argv url='http://translate.google.cn/translate_a/single?client=t&sl=zh-CN&tl=en&hl=zh-CN&dt=at&dt=bd&dt=ex&dt=ld&dt=md&dt=qca&dt=rw&dt=rm&dt=ss&dt=t&ie=UTF-8&oe=UTF-8&pc=1&otf=1&ssel=6&tsel=3&kc=0&tk='+ tk +'&q=' + zh def getRes(): #print 'chinese is :'+urllib.unquote(first) null_proxy_handler = urllib2.ProxyHandler({}) opener = urllib2.build_opener(null_proxy_handler) urllib2.install_opener(opener) req = urllib2.Request(url) req.add_header('User-Agent', "Mozilla/5.0") response = urllib2.urlopen(req) print response.read() print getRes()