关注公众号:Java架构师联盟,每日更新技术好文
部分资料已经上传到我的git仓库中:有需要的可以下载
作为一个程序员,通常,我们的程序需要根据程序运行时才知道创建多少个对象。但若非程序运行,程序开发阶段,我们根本不知道到底需要多少个数量的对象,甚至不知道它的准确类型。为了满足这些常规的编程需要,我们要求能在任何时候,任何地点创建任意数量的对象,而这些对象用什么来容纳呢?我们首先想到了数组,但是数组只能放同一类型的数据,而且其长度是固定的,那怎么办呢?集合便应运而生了!
而对于集合的相关内容,我通过思维导图整理了一下,分成两个部分,Map和Collection两个部分,来看一下
Map

Collection
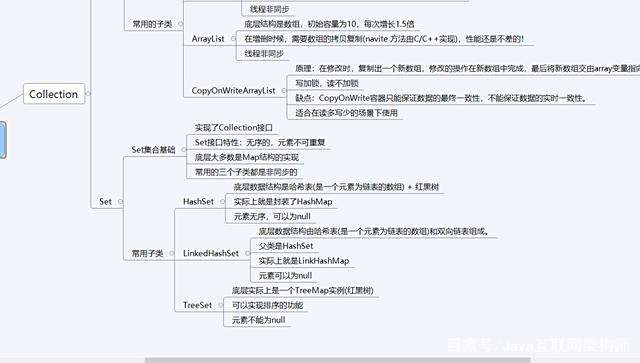
因为篇幅原因,只展示Collection的List,这也是在日常开发中应用最多的,或者说在面试过程中被问到最多的一个知识点,因为它可以扩充出来很多其他的知识点
一、ArrayList的底层实现
-
ArrayList实现与List、RandomAccess接口,是顺序接口,即元素存放的数据与放进去的顺序相同,允许放入null元素,也支持随机访问
-
底层通过数组实现。除该类未实现同步外,其余跟Vector大致相同
-
ArrayList相当于动态数据,其中最重要的两个属性分别是:elementData数组以及siz
二、ArrayList可以实现同步吗
为了追求效率,ArrayList没有实现同步(synchronizd),如果需要逗哥线程并发访问,用户可以手动同步,也可以使用Vector代替。如可以先采用Collections.synchronizedList()方法对其进行包装
三、ArrayList的add()方法
在调用add()方法的时候首先进行扩容校验,将插入的值放在尾部,并将size+1.
public boolean add(E e) { ensureCapacityInternal(size + 1); // Increments modCount!! elementData[size++] = e; return true; }
四、ArrayList的add(index,e)方法
如果调用add(index,e)在指定位置添加的话也是首先扩容校验,接着对数据进行复制,目的是把index位置空出来放本次插入的数据,并将后面的数据向后移动一个位置。
public void add(int index, E element) { rangeCheckForAdd(index); ensureCapacityInternal(size + 1); // Increments modCount!! //复制,向后移动 System.arraycopy(elementData, index, elementData, index + 1, size - index); elementData[index] = element; size++; }
其实扩容最终调用的代码
private void grow(int minCapacity) { // overflow-conscious code int oldCapacity = elementData.length; int newCapacity = oldCapacity + (oldCapacity >> 1); if (newCapacity - minCapacity < 0) newCapacity = minCapacity; if (newCapacity - MAX_ARRAY_SIZE > 0) newCapacity = hugeCapacity(minCapacity); // minCapacity is usually close to size, so this is a win: elementData = Arrays.copyOf(elementData, newCapacity); }
也是一个数组复制的过程。
注意:
由此可见ArrayList的主要消耗时数组扩容以及在指定位置添加数据,在日常使用时最好是指定大小,尽量减少扩容。更要减少在指定位置插入数据的操作。
五、ArrayList的序列化
由于ArrayList是基于动态宿主实现的,所以并不是所有的空间都被使用。因此使用了transient修饰。可以防止被自动序列化
transient Object[] elementData; // non-private to simplify nested class access
因此ArrayList自定义了序列化和反序列化
//序列化 private void writeObject(java.io.ObjectOutputStream s) throws java.io.IOException{ // Write out element count, and any hidden stuff int expectedModCount = modCount; s.defaultWriteObject(); // Write out size as capacity for behavioural compatibility with clone() s.writeInt(size); // Write out all elements in the proper order. //只序列化了被使用的数据 for (int i=0; i<size; i++) { s.writeObject(elementData[i]); } if (modCount != expectedModCount) { throw new ConcurrentModificationException(); } } //反序列化 private void readObject(java.io.ObjectInputStream s) throws java.io.IOException, ClassNotFoundException { elementData = EMPTY_ELEMENTDATA; // Read in size, and any hidden stuff s.defaultReadObject(); // Read in capacity s.readInt(); // ignored if (size > 0) { // be like clone(), allocate array based upon size not capacity int capacity = calculateCapacity(elementData, size); SharedSecrets.getJavaOISAccess().checkArray(s, Object[].class, capacity); ensureCapacityInternal(size); Object[] a = elementData; // Read in all elements in the proper order. for (int i=0; i<size; i++) { a[i] = s.readObject(); } } }
当对象中自定义了writeObject和readObject方法时,JVM会调用这两个自定义方法来实现序列化和反序列化
从实现中可以看出ArrayList值序列化了被使用的数据
六、ArrayList和Vector的比较
Vector也会是实现List接口,底层数据结构和ArrayList类似,也是一个动态数组存放的数据,不过在add()方法的时候使用synchronized进行同步数据,但是开销较大,所以Vector是一个同步容器并不是并发容器。
add()方法
public synchronized boolean add(E e) { modCount++; ensureCapacityHelper(elementCount + 1); elementData[elementCount++] = e; return true; }
add(index,e)方法:指定位置插入数据
public void add(int index, E element) { insertElementAt(element, index); } public synchronized void insertElementAt(E obj, int index) { modCount++; if (index > elementCount) { throw new ArrayIndexOutOfBoundsException(index + " > " + elementCount); } ensureCapacityHelper(elementCount + 1); System.arraycopy(elementData, index, elementData, index + 1, elementCount - index); elementData[index] = obj; elementCount++; }
七、ArrayList的扩容机制
-
假如有20个数据需要添加,那么会分别在第一次的时候将ArrayList
-
之后扩容会按照1.5倍增长,也就是当添加第11个数据的时候,ArrayList继续扩容变为10*1.5=15;
-
当添加第16个数据时。继续扩容15*1.5=22个
-
不能超过int的最大值(231-1)-8
private static final int MAX_ARRAY_SIZE = Integer.MAX_VALUE - 8;
八、LinkedList的底层实现
-
LinkedList底层是基于双向链表实现的;
-
本身实现了List和Deque(双端队列)接口
-
拥有List的一些特性(jdk1.7/1.8之后取消了循环,修改为双向链表)
既可以看做一个顺序容器,又可以看做一个队列(Queue),同时又可以看做一个栈(stack)。这样看来,LinkedList简直是个全能冠军。当你需要使用栈或者队列时,可以考虑使用LinkedList,一方面是因为Java官方已经声明不建议使用Stack类,更遗憾的是,Java里根本没有一个叫做Queue的类(它是一个接口名)。关于栈或者队列,现在的首选是ArrayDeque,它有着比LinkedList(当做栈或者队列使用时)更好的性能。
九、LinkedList的add()方法
public boolean add(E e) { linkLast(e); return true; } void linkLast(E e) { final Node<E> l = last; final Node<E> newNode = new Node<>(l, e, null); last = newNode; if (l == null) first = newNode; else l.next = newNode; size++; modCount++; }
可见每次插入都是移动指针,和ArrayList的拷贝数组来说效率要高上不少
十、LinkedList的查询方法get(index)
public E get(int index) { checkElementIndex(index); return node(index).item; } Node<E> node(int index) { // assert isElementIndex(index); if (index < (size >> 1)) { Node<E> x = first; for (int i = 0; i < index; i++) x = x.next; return x; } else { Node<E> x = last; for (int i = size - 1; i > index; i--) x = x.prev; return x; } }
上述代码,利用了双向链表的特性,如果index离链表头比较近,就从节点头部遍历。否则就从节点尾部开始遍历。使用空间(双向链表)来换取时间
-
node会以O(n/2)的性能去获取一个节点
-
如果索引值大于链表大小的一半,那么将从尾节点开始遍历,这样的效率是非常低的,特别是当index越接近size的中间值
十一、LinkedList优缺点
LinkedList插入、删除都是移动指针效率很高
产讯需要遍历进行查询,效率较低
怎么样,不知道总结的详细不,看完之后有没有一点收获,而这一些知识的整理也参考了下面这份文档的内容
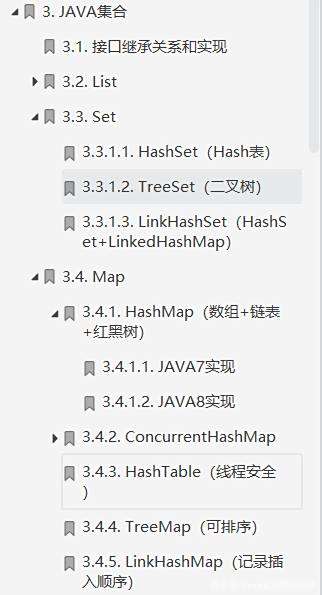
详细内容展示

Set

List

map

而这份文档除了集合之外,还包括这些知识,我想不算全部,这里面大部分对现在的你都应该有所帮助吧
你比别人强的地方,不是你做过多少年的CRUD工作,而是你比别人掌握了更多深入的技能。不要总停留在CRUD的表面工作,理解并掌握底层原理并熟悉源码实现,并形成自己的抽象思维能力,做到灵活运用,才是你突破瓶颈,脱颖而出的重要方向!
你在刷抖音,玩游戏的时候,别人都在这里学习,成长,提升,人与人最大的差距其实就是思维。你可能不信,优秀的人,总是在一起。