自学python爬虫也快半年了,在目前看来,我面临着三个待解决的爬虫技术方面的问题:动态加载,多线程并发抓取,模拟登陆。目前正在不断学习相关知识。下面简单写一下用selenium处理动态加载页面相关的知识。目标——抓取页面所有的高考录取分数信息。
对于动态加载,开始的时候是看到Selenium+Phantomjs的强大,直接就学的这个。打开网页查看网页源码(注意不是检查元素)会发现要爬取的信息并不在源码里面。也就是说,从网页源码无法通过解析得到数据。Selenium+Phantomjs的强大一方面就在于能将完整的源码抓取到,上代码。
from selenium import webdriver
def get_grade(url):
print(url)
#匿名爬虫
#假定9999端口开启tor服务
service_args = ['--proxy=localhost:9999', '--proxy-type=socks5', ]
driver = webdriver.PhantomJS(executable_path=这里是PhantomJS的绝对路径)
driver.get(url)
data = driver.page_source
print(data)
get("http://gkcx.eol.cn/soudaxue/queryProvince.html?page=1")
这里还用到了匿名爬虫,这里呢我也只是到了能用的水平,具体原理还不太懂。。。这样就能拿到完整的源码,是不是很简单呢?当然简单啦,不过简单的代价就是牺牲速度。
这个程序还不算复杂,当抓取量大的时候,模拟抓取的效率就会变得很低(还不会多线程。。。不知道用多线程能不能提速)。下面是此项目的完整代码:
import xlsxwriter
from selenium import webdriver
from bs4 import BeautifulSoup
def get_grade(url):
print(url)
#匿名爬虫
#假定9999端口开启tor服务
service_args = ['--proxy=localhost:9999', '--proxy-type=socks5', ]
driver = webdriver.PhantomJS(executable_path=r"F:TechonolgoyPythonfilespiderspider_toolsJS1phantomjs.exe")
driver.get(url)
data = driver.page_source
# print(data)
soup = BeautifulSoup(data, 'lxml')
grades = soup.find_all('tr')
for grade in grades:
global i
if '<td>' in str(grade):
i += 1
print(i)
grade_text =grade.get_text()
print(grade_text)
grade_text = str(grade_text)
city = grade_text[:-13]
worksheet.write(i,0,city)
time = grade_text[-13:-9]
worksheet.write(i,1,time)
subs = grade_text[-9:-7]
worksheet.write(i,2,subs)
s = grade_text[-7:-3]
worksheet.write(i,3,s)
grade = grade_text[-3:]
worksheet.write(i,4,grade)
i = -1
workbook = xlsxwriter.Workbook('grades.xlsx')
worksheet = workbook.add_worksheet()
worksheet.set_column('A:A',10)
worksheet.set_column('B:B', 10)
worksheet.set_column('C:C', 10)
worksheet.set_column('D:D', 10)
worksheet.set_column('E:E', 10)
urls = ['http://gkcx.eol.cn/soudaxue/queryProvince.html?page='+str(num)
for num in range(1,166)]
for url in urls:
get_grade(url)
workbook.close()
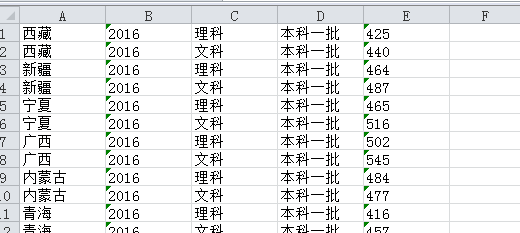
家里面网速太慢,一共用了20分钟才爬取完毕。。。抓取到的EXCEL文件格式如下:
我是被这模拟抓取的龟速折磨的够心累的,所以,经大牛们指点,找到了处理这类问题的另一个方法——直接清求json文件获取数据!这个放到下面再写。