-
模块和软件开发目录规范
- 模块
- 模块:就是一系列功能的结合体
- 模块三种来源:
- 1.内置的(Python解释器自带的)
- 2.第三方的(别人写的)
- 3.自定义的(你自己写的)
- 模块的四种表现形式
- 1.使用Python边编写的py文件(也就意味着py文件也可以称之为模块:一个py文件也可以称之为一个模块)
- 2.已被编译为共享库或DLL的C或C++扩展
- 3.把一系列模块组织到一起的文件夹(文件夹下有一个__init__.py文件,该文件称之为包)包:一系列py文件的结合体
- 4.使用C编写并连接到Python解释器的内置模块
- 为什么要用模块:
- 1.用别人写好的模块(内置的,第三方的):极大提高开发效率
- 2.使用自己写的模块(自定义的):程序比较庞大的时候,项目不可能只在一个py文件中,当多个文件中都需要使用相同的方法的时候,可以将改公共的方法写到一个py文件中,其他的文件以模块的形式导过去直接调用即可
- 模块的使用:
- 注意:一定要区分哪个是执行文件,哪个是被导入的文件
- import方式导入模块
- 右键运行run.py文件首先会创建一个run.py自己的一个名称空间
- 首次导入模块:
- (执行文件为run.py,导入文件为md.py;md.py中有read1方法,change()方法等)
- 1.执行md.py文件
- 2.运行md.py文件中的代码,将产生的名字与值存放在md.py名称空间中
- 3.在执行文件中产生一个指向名称空间的名字(md)
- 4.访问模块中的名字指向的值:使用import导入模块,访问模块名称空间中的名字统一句式:模块名.名字(print(md.read1)),如果是方法,加括号即可执行md.read1()
- 注意点一:函数名加括号的情况:
- 1.只要能拿到函数名,无论在哪都可以通过函数名加括号的方式,调用这个函数(会回到函数定义阶段 依次执行代码)
- 2.函数定义阶段,名字的查找顺序就已经固定死了,不会因为调用位置的变化而变化
- 注意点二:使用import导入模块,访问模块名称空间中的名字统一句式:模块名.名字:
- 1.指名道姓地访问模块中的名字,永远不会与执行文件中的名字冲突
- 2.这种方式是唯一的方式
- 注意点三:导入多个模块:
- 1.通常导入模块的句式会写在文件开头,也会写在函数体内
- 2.只要当几个模块有相同部分,或者同属于同一个模块,可以使用 import 模块名1,模块名2,模块名3 的形式;当几个模块没有联系的情况下,应该分多次导入import os(换行) import time(换行) import md
- 注意点四:起别名
- 模块名字比较复杂时可以取别名 import testtttttttttt as func
- 多次导入模块:
- 多次导入不会再执行模块文件,会沿用第一次导入的成果(******)
- from...inport...方式导入模块
- 导入和执行流程和import是一样的
- 缺点:
- 1.访问模块中的名字不需要加模块名前缀
- 2.在访问模块中的名字时,可能会与当前执行文件中的名字冲突
- 补充:
- 1.from md import * 可以一次性将md模块中的名字全部加载过来(不推荐使用,占用内存空间)并且也不知道那些名字可以用(有些可能和执行文件中的变量名冲突)
- 2.__all__可以指定所在py文件被当做模块导入的时候,可以限制导入这能拿到的名字都有哪些(__all__是写在模块中的__all__['read1', 'change',],此时执行文件中写的导入语句是import md import *)
- 循环导入
- 两个模块互相导入就形成了循环导入。如果出现循环导入问题 那么一定是你的程序设计的不合理循环导入问题应该在程序设计阶段就应该避免
- 如何避免:
- 1.将循环导入的句式写在文件最下方,保证先声明后导入
- 2.需要导入时再导入,例如导入语句放在函数体内
- 3.降低程序耦合
- __name__用法
- 用法一:
- 可以在文件中写一句 print(__name__)
- 当文件被当做执行文件 执行的时候,打印结果是__main__
- 当文件被当做模块导入的时候__name__的结果是模块名
- 用法二:
- 将函数名加括号的形式,写在if __name__ == '__main__'判断体内,则根据用户的执行方式,文件自动就选择了运行方式:被用作导入的时候__name__返回的是模块名,跟'__main__'不相等,则不执行函数体代码;被执行的时候,__name__返回的是'__main__'跟'__name__'相等,则执行函数名加括号,即执行函数体代码
- 注意:快捷写法,输入main之后,直接按tab键 即可自动补全成为if __name__ == '__main__'
- 绝对导入和相对导入
- 绝对导入:
- 1.必须依据执行文件所在的文件夹路径为准
- 2.绝对导入无论在执行文件还是被导入文件都适用
- 相对导入:
- .代表当前路径
- ..代表上一级路径
- ...代表是上上一级路径
- 导入注意事项;
- 1.相对导入不能用在执行文件中
- 2.相对导入只能用在被导入的模块中,使用相对导入的话,就不用考虑执行文件到底是谁,只需要知道模块与模块之间路径关系
- 模块查找顺序
- 顺序:
- 1.先从内存中找(已经加载的模块)
- 2.没有的话,再从内置中找
- 3.最后从sys.path中找(相当于环境变量)
- 使用方法:
- 查找方法,先调用import sys 再打印print(sys.path) 表示搜索模块的路径集,返回一个列表,显示的是当前文件可以访问到的路径,第一个路径永远是执行文件所在的文件夹
- 可以在python 环境下使用sys.path.append(path)添加相关的路径,但在退出python环境后自己添加的路径就会自动消失! sys.path.append(r'D:Python项目day14dir1')
- 与路径结合的方式导入模块:from dir1.dir import md
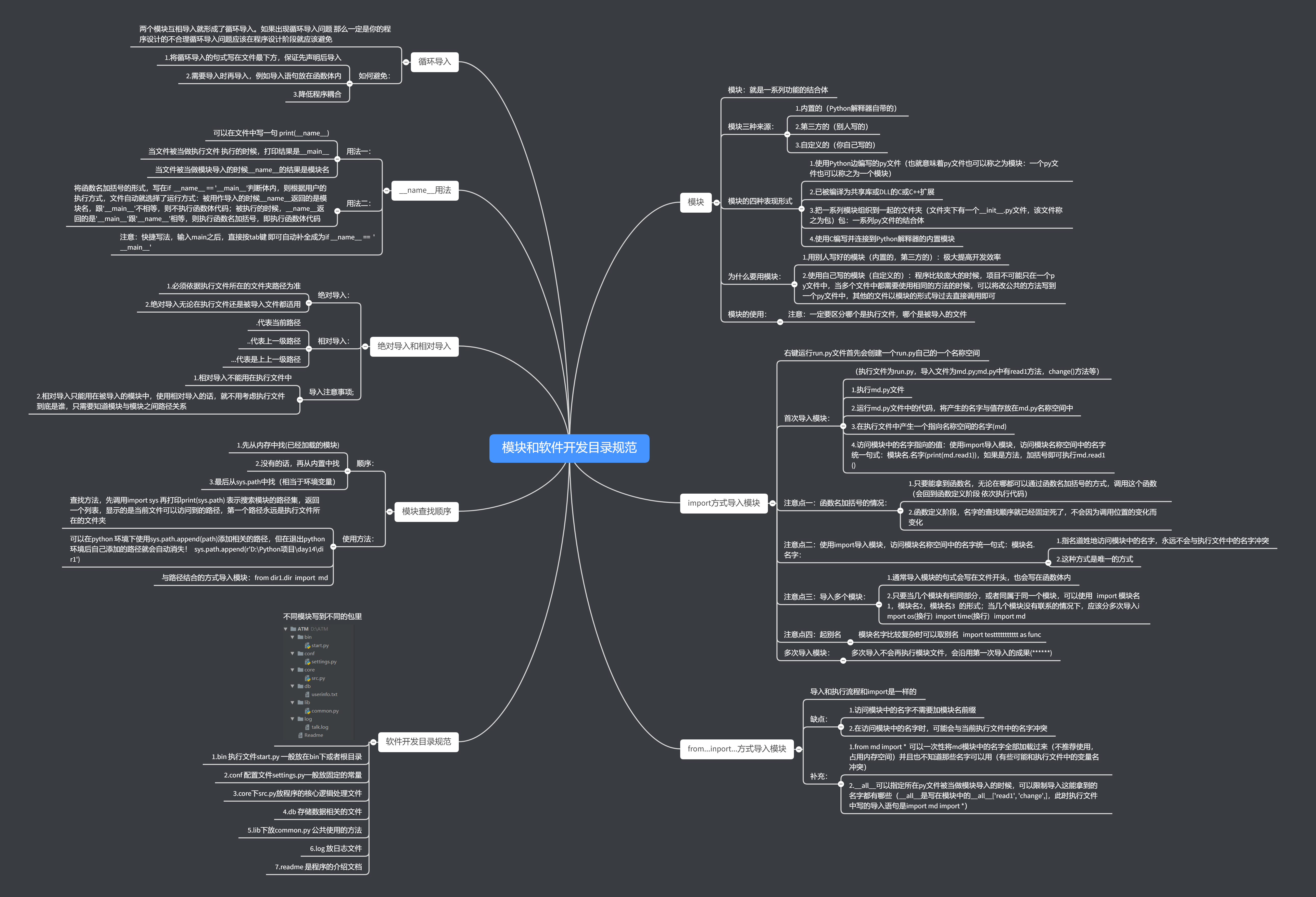
- 软件开发目录规范
- 不同模块写到不同的包里
- 1.bin 执行文件start.py 一般放在bin下或者根目录
- 2.conf 配置文件settings.py一般放固定的常量
- 3.core下src.py放程序的核心逻辑处理文件
- 4.db 存储数据相关的文件
- 5.lib下放common.py 公共使用的方法
- 6.log 放日志文件
- 7.readme 是程序的介绍文档
-
相关阅读:
5种Python使用定时调度任务的方式
基于Tensorflow + Opencv 实现CNN自定义图像分类
CANN 5.0硬核技术抢先看
大力出奇迹,揭秘昇腾CANN的AI超能力
MSQL:超强的多任务表示学习方法
Shell:Lite OS在线调试工具知多少
带你掌握Vue过滤器filters及时间戳转换
Selenium系列(六) 详细解读强制等待、隐式等待、显式等待的区别和源码解读
Linux常用命令 top命令详解(重点)
Selenium系列(一) 详细解读8种元素定位方式
-
原文地址:https://www.cnblogs.com/buzaiyicheng/p/11196813.html
Copyright © 2020-2023
润新知
