Java pageEncoding原理详解
首先看下文章解释:
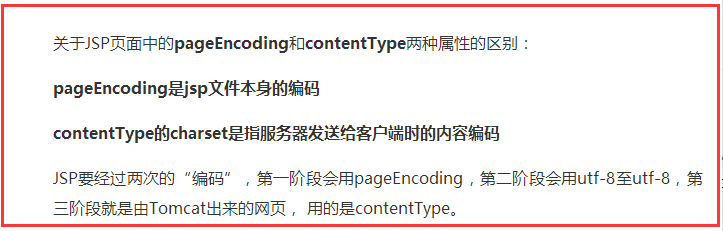
意思是jsp文件本身的编码
巨大的疑问:这里有一个很大的问题,既然你都已经从jsp中读到了这条属性,证明内容读取正确,那你还需要知道这条属性所指的编码是什么干嘛?
下面务必来看看Jsp的编译原理
第一阶段是jsp编译成java
它会根据pageEncoding的设定读取jsp,结果是由指定的编码方案翻译成统一的UTF-8 JAVA源码(即.java),如果pageEncoding设定错了,或没有设定,出来的就是中文乱码。
第二阶段是由JAVAC的JAVA源码至java byteCode的编译
不论JSP编写时候用的是什么编码方案,经过这个阶段的结果全部是UTF-8的encoding的java源码。
JAVAC用UTF-8的encoding读取java源码,编译成UTF-8 encoding的二进制码(即.class),这是JVM对常数字串在二进制码(java encoding)内表达的规范。
第三阶段是Tomcat(或其的application container)载入和执行阶段二的来的JAVA二进制码
输出的结果,也就是在客户端见到的,这时隐藏在阶段一和阶段二的参数contentType就发挥了功效
-----------------------------------------------------------------------------------------------------------------------------------
概括流程:读取jsp -> 编译成java文件 -> 编译成class文件
可以得出:
第一次读取jsp时所用的编码肯定不是pageEncoding所指定的编码,因为既然能读到pageEncoding的属性的时候,肯定就知道jsp文件的编码,因为pageEncoding在jsp文件当中,不可能不读jsp文件就知道pageEncoding的属性
重点:
那么既然jsp都被读出来了,还需要pageEncoding属性(设置读取jsp文件的编码)干嘛
原因是,这里的读取是指的,编译成.java文件时,读取jsp的编码
分析原理就是:
用默认编码打开jsp得到pageEncoding属性 -> 使用pageEncoding属性设置的编码再次读取jsp -> 编译成.java文件
有意思的地方就在这里了,有人会问第一步用默认编码能获得未知编码的jsp文件中的pageEncoding吗,你怎么知道jsp文件用的是什么编码呢,那么,请仔细想想,pageEncoding属性的语言是英文,java所支持的编码是不是都是支持英文的呢
所以jsp文件编码、pageEncoding指定编码、Content-Type编码一致才能正确显示数据就是这个原因
相信已经透彻的讲了,已经没有能够浓缩的地方了,有什么不懂可以留言,一般常在,尽量帮你解决,伸出小手点个赞,谢谢 = =