一、简介
Libra R-CNN: Towards Balanced Learning for Object Detection是发表于2019年CVPR的论文。文章中没有太多改造网络结构,计算成本也没增加多少,只是通过三个方面的改进就能在MSCOCO数据集上AP值比FPN Faster RCNN高2.5%,比RetinaNet高2%。附上开源链接。
二、参考文献/博客
- Libra R-CNN: Towards Balanced Learning for Object Detection
- CVPR 2019 | Libra R-CNN 论文解读
- Feature Pyramid Networks for Object Detection
三、论文详解
1、提出背景
三个不平衡
随着深卷积网络的发展,近年来,在目标检测方面取得了显著进展。一些检测框架,如Fasetr R-CNN、Retinanet和Cascaded R-CNN已经开发出来,这大大推动了技术的发展。尽管管道体系结构存在明显的差异,例如单阶段与两阶段,但现代检测框架大多遵循一种通用的训练范式:
- 采样候选区域 sample level
- 从中提取特征 feature level
- 在多任务目标函数的指导下识别目标和润色边界框 objective level
如fig1所示:
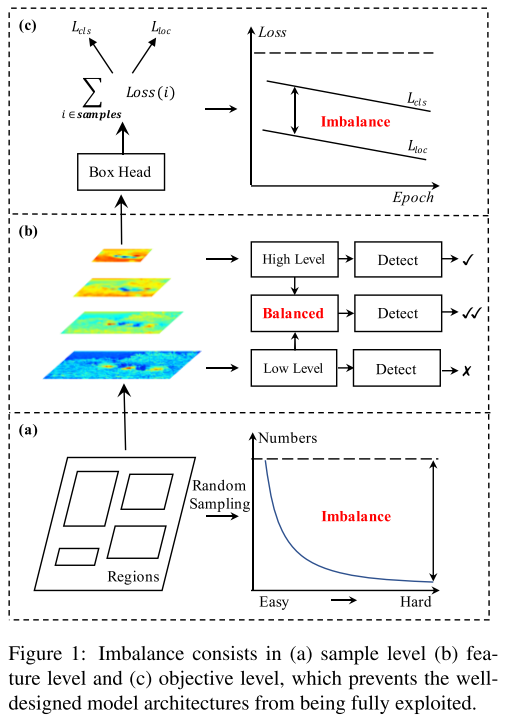
这个范式使得目标检测是否成功取决于三方面:
- 选择的区域是否具有代表性
- 提取的特征是否被充分利用
- 多任务目标函数是否为最优的
sample level imbalance
当训练目标探测器时,难样本(hard exsample)尤其有价值,因为它们更有效地提高了检测性能。然而,随机抽样(random sampling)往往导致选择样本以简单样本为主。流行的难例方法,如OHEM,有助于将焦点转向难样本。然而,它们往往对噪声标签敏感,并产生相当大的内存和计算成本。在单级探测器中,focal loss也缓解了这一问题,但当扩展到R-CNN时,发现几乎没有改善,因为大多数易分负样本是通过两级过滤的。因此,这个问题需要更优雅地解决。
feature level imbalance
主干中深层次的高层次特征具有更多的语义意义,而深层次的低层次特征具有更多的描述性内容。最近,通过横向连接在FPN和PANET中进行的特征集成促进了目标检测的发展。这些方法启发我们,低层次和高层次的信息是对目标检测的补充。如何利用它们来集成金字塔表示的方法决定了检测性能。但是,将它们集成在一起的最佳方法是什么?我们的研究表明,综合特征应该具有来自每个分辨率的平衡信息。但前文所述方法中的顺序方式将使集成特性更多地关注相邻分辨率,而较少关注其他分辨率。在信息流中,非相邻层次中包含的语义信息在每次融合时都会被稀释一次。下图是FPN论文中特征融合比较的图:
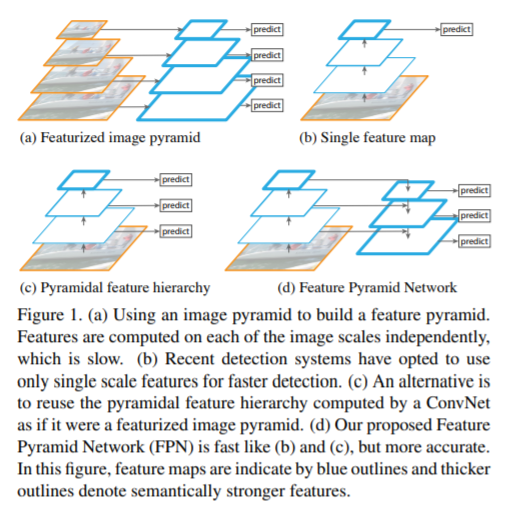
可以看到FPN更关注于相邻层间的特征融合。
objective level imbalance
检测器需要执行两个任务,即分类和定位。因此,训练目标中包含两个不同的目标。如果它们没有得到适当的平衡,一个目标可能会受到影响,从而导致总体性能不理想。训练过程中涉及的样本情况相同。如果不适当平衡,易分样本产生的小梯度可能会淹没在难例产生的大梯度中,从而限制进一步细化。因此,我们需要重新平衡所涉及的任务和样本,使其达到最佳收敛。
2、解决办法
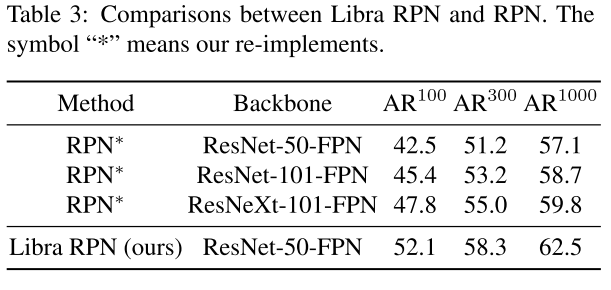
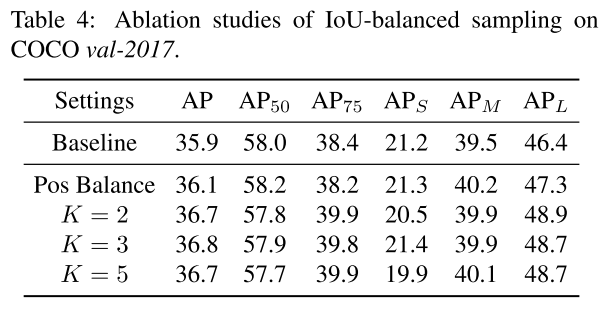
IoU-balanced sampling
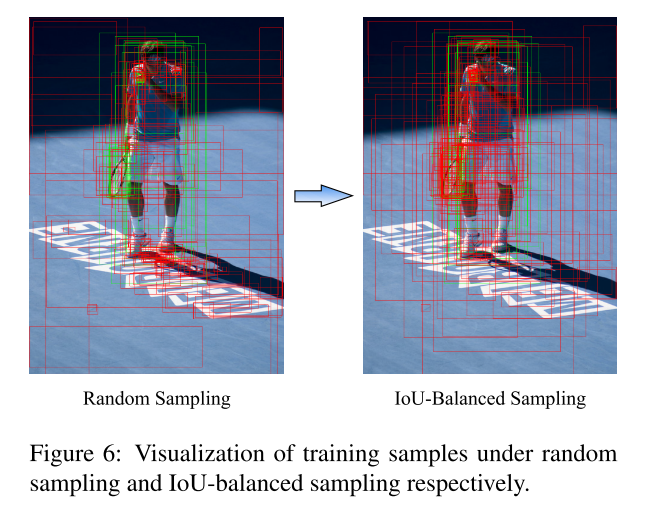
根据它们和真值的IoU来挖掘难例。下图为不同采样的比较:

训练样本和真值的重叠和它是否难分有关?我们主要考虑难负样本的问题,这是众所周知的主要问题。我们发现超过60%的难负样本重叠度大于0.05,但随机抽样只提供了超过相同阈值的30%的训练样本。这种极端的样本不平衡将许多难样本埋藏在成数千个易分样本之中。基于这一观察,我们提出了IOU平衡。
一种简单而有效的难样本方法,无需额外成本。假设我们需要从M个对应的候选样本中抽取N个负样本。随机抽样下每个样本的选择概率是:
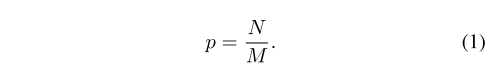
为了提高难负样本的选定概率,我们根据IOU将采样间隔均匀地分成K个。N个需要的难负样本平均分配到每个区间。然后我们从中均匀地选取样本。因此,我们得到了IOU均衡抽样下的选择概率:
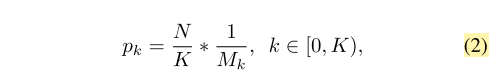
Mk是第k个区间中候选样本的数量。K在论文中被设为3(经过实验,只要更容易选择IoU更高的样本,结果对K不敏感)。
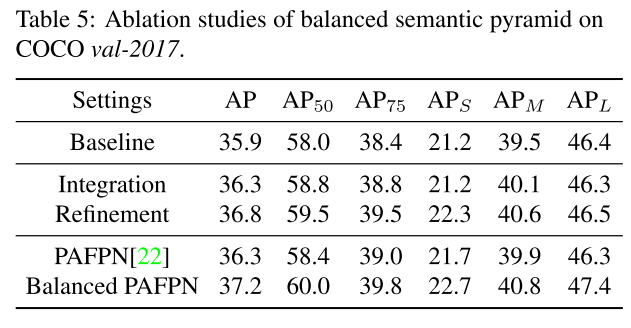
Balanced Feature Pyramid
我们的核心思想是使用相同的深度集成的平衡语义特征来增强多层次的特征。管道如图所示。它由四个步骤组成:缩放、整合、润色和强化。
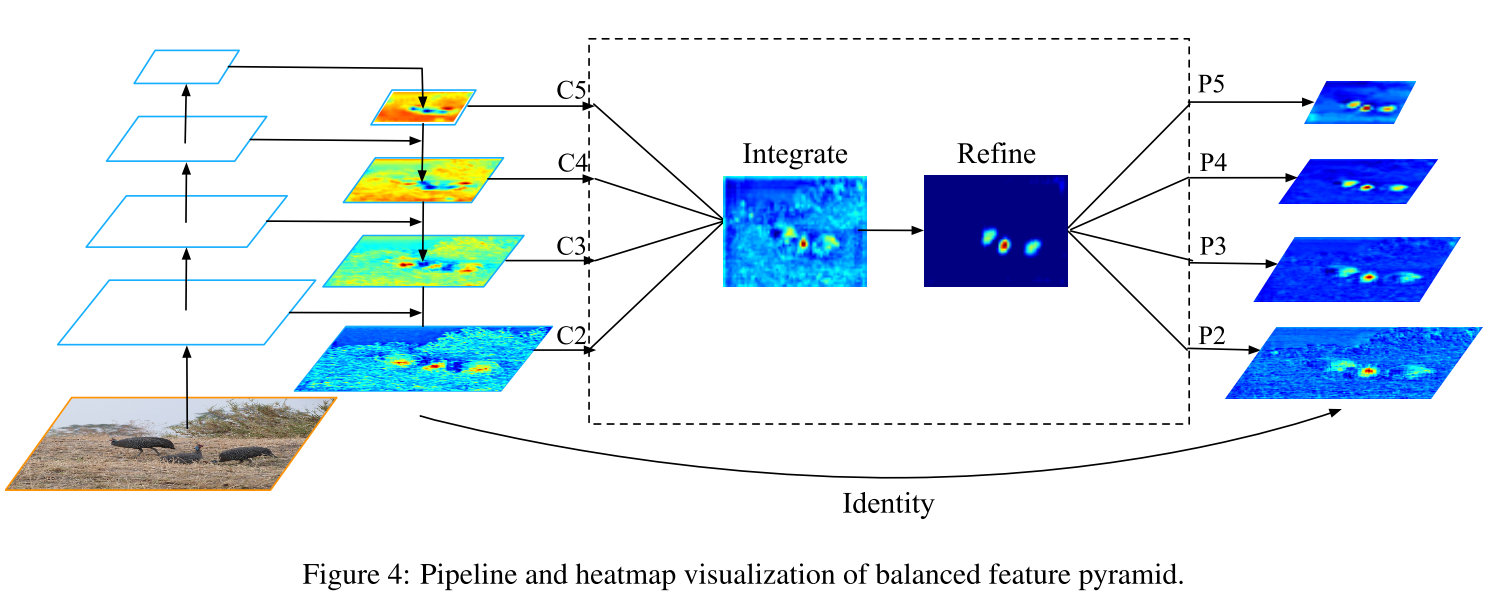
Obtaining balanced semantic features 获得平衡语义特征。分辨率级别l的特征表示为Cl。多级别特征的数量表示为L。涉及的最低和最高级别的索引表示为lmin和lmax。在图中,C2的分辨率最高。为了同时集成多层次特性并保持其语义层次,我们首先将多层次特性C2、C3、C4、C5分别使用插值和最大值池化调整为中等大小,即与C4大小相同,。一旦特征被重新调整,通过简单的平均得到平衡的语义特征:
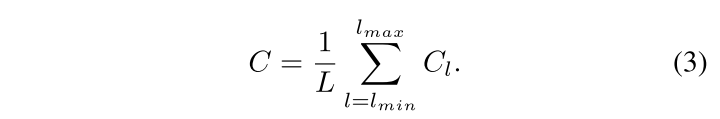
在本步骤中,每个分辨率都从其他分辨率中获得同等的信息。
Refining balanced semantic features 润色平衡的语义特征。 我们发现直接使用卷积和non-local模块都可以很好地工作。但non-local更稳定。因此,在本文中,我们使用embedded Gaussian non-local attention作为默认值。细化步骤有助于增强集成功能,进一步提高结果。使用这种方法,可以同时聚合从低级到高级的特征。输出P2、P3、P4、P5用于在FPN中沿着同一管道检测对象。值得一提的是,我们的平衡特性金字塔可以与最近的解决方案(如FPN和PAFPN)互补,而不会产生任何冲突。
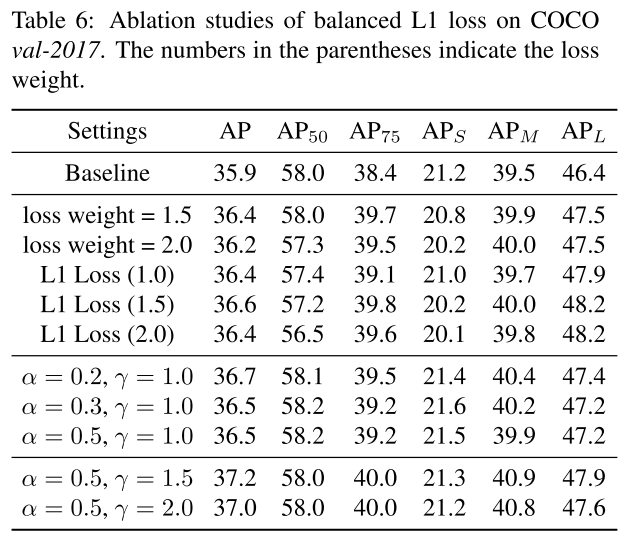
Balanced L1 Loss
Faster R-CNN以来,分类和定位问题在多任务损失的指导下同时得到解决,定义为:
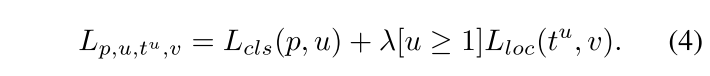
Lcls和Lloc分别是识别和定位的目标函数。Lcls中的预测和目标分别表示为p,u。tu是类别u相应的回归结果,v是回归目标。λ用于调整多任务学习下的权重。我们称损失大于或等于1.0的样本为outliers。其他样本称为inliers。
平衡多任务损失的常见的方法就是调整权重,但是由于回归目标无界,直接增加定位损失会使得模型对outliers更加敏感。这些outliers可以被视为难样本,会产生对训练过程有害的过大梯度。与outliers相比,inliers对整体梯度的贡献很小,可以看作是一个简单的样本。更具体地说,与outliers相比,每个样本的平均梯度只有30%。考虑到这些问题,我们提出了平衡的L1损耗,用Lb表示。
首先我们看Smooth L1 Loss:
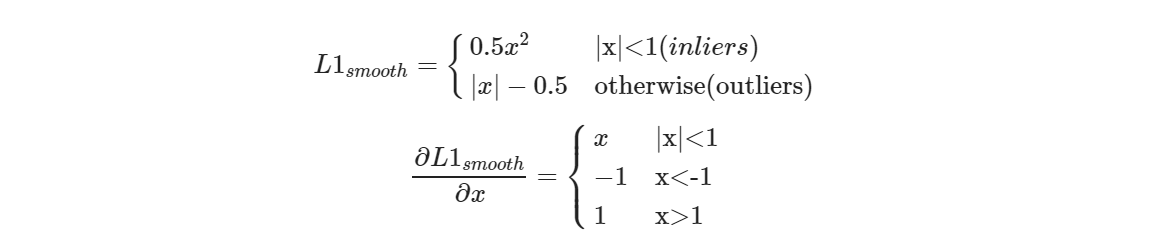
Lloc的Balanced L1 Loss为:
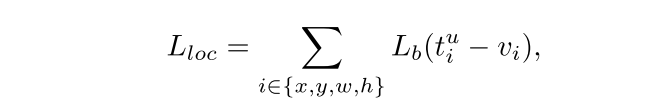
梯度计算遵循下面的准则:
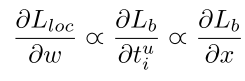
于是作者从需出发,设计了一个在|x|<1时梯度比较大的函数
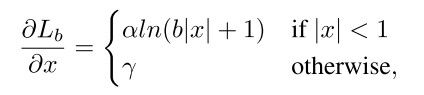
从下图中可以看出,在|x|<1时,上式的梯度是大于x(Smooth L1 Loss的梯度)

根据梯度反求出Lb(x) 表达式:
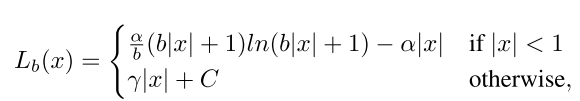
还有很重要的一点就是为了函数的连续性,需要满足x=1时,Lb(1)=γ。

四、实验结果
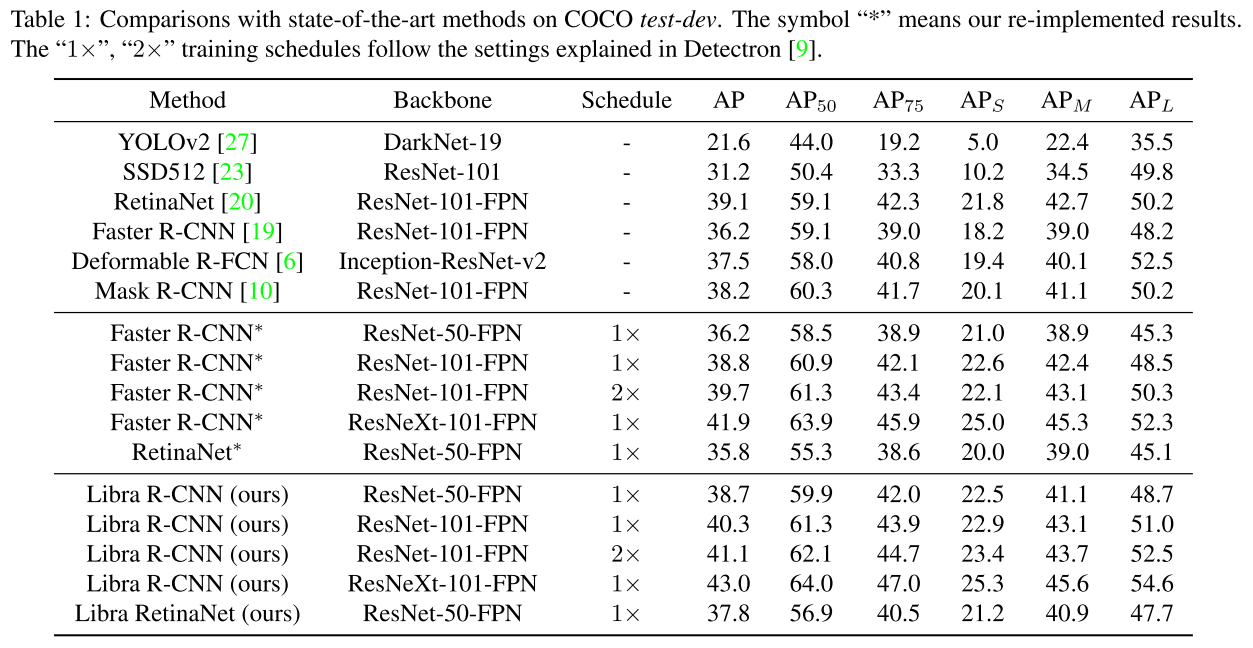

五、总结
这篇论文结构清晰,从三个问题入手,分层次解决问题,在不太改动网络结构和增加计算成本的条件下,就能获得比较好的结果,是一篇比较好的baseline。