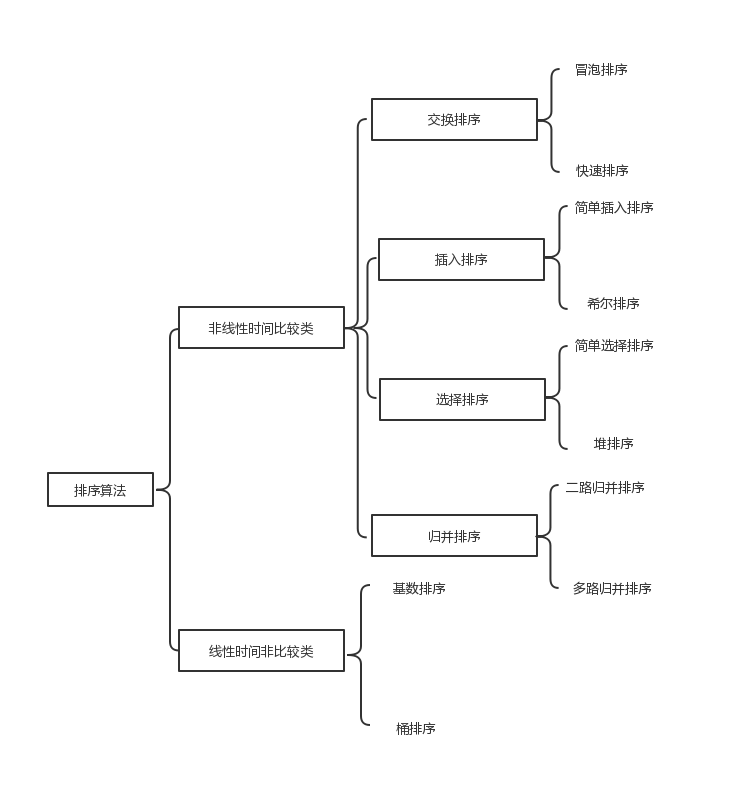
一、算法概述
1.算法分类
常见的十大经典排序算法可以分为两大类:
- 非线性时间比较类排序:通过比较来决定元素间的相对次序,由于其时间复杂度不能突破O(nlogn),因此称为非线性时间比较类排序。
- 线性时间非比较类排序:不通过比较来决定元素间的相对次序,它可以突破基于比较排序的时间下界,以线性时间运行,因此称为线性时间非比较类排序。
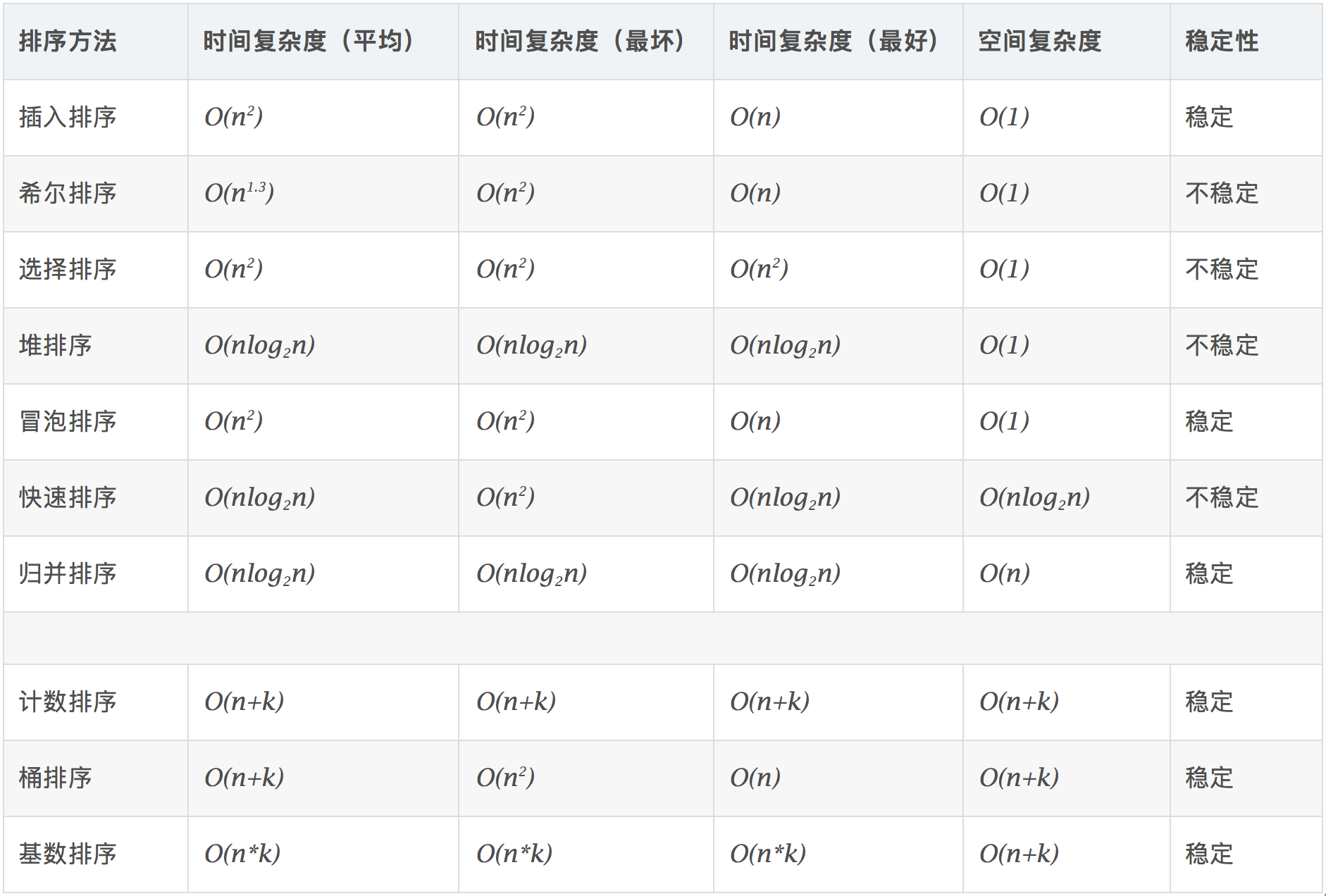
2.算法复杂度
3.相关概念
稳定:如果a原本在b前面,而a=b,排序之后a仍然在b的前面。
不稳定:如果a原本在b的前面,而a=b,排序之后 a 可能会出现在 b 的后面。
时间复杂度:对排序数据的总的操作次数。反映当n变化时,操作次数呈现什么规律。
空间复杂度:是指算法在计算机内执行时所需存储空间的度量,它也是数据规模n的函数。
二、参考博客
- C++经典排序算法总结 https://www.cnblogs.com/fnlingnzb-learner/p/9374732.html
- 排序(1):冒泡排序 https://cuijiahua.com/blog/2017/12/algorithm_2.html
- 快速排序算法的C++实现 https://www.cnblogs.com/xiezhw3/p/3439031.html
- 001-快速排序(C++实现) https://www.cnblogs.com/miracleswgm/p/9199124.html
- 插入排序(C++实现)https://www.cnblogs.com/Mrzhang3389/p/10127398.html
- 处理海量数据的高级排序之希尔排序(C++) https://www.cnblogs.com/leoin2012/p/3910889.html
- 八种排序方法(一)——选择排序 https://blog.csdn.net/qq_39360985/article/details/78808171
- 排序(5):简单选择排序 https://cuijiahua.com/blog/2017/12/algorithm_5.html
三、算法详解
1.交换排序之冒泡排序
代码实现:
void BubbleSort(int* pData, int count) { for (int i = 1; i < count; i++) { for (int j = count - 1; j >= i; j--) { if (pData[j] < pData[j - 1]) { swap(pData[j],pData[j-1]);//自行写交换函数 } } } }
2.交换排序之快速排序
首先,快排的思想就是
- 从数列中挑出一个元素,称为 "基准"(pivot),
- 重新排序数列,所有元素比基准值小的摆放在基准前面,所有元素比基准值大的摆在基准的后面(相同的数可以到任一边)。在这个分区退出之后,该基准就处于数列的中间位置。这个称为分区(partition)操作。
- 递归地(recursive)把小于基准值元素的子数列和大于基准值元素的子数列排序
快速排序的时间复杂度在最坏情况下是O(N2),最好和平均的时间复杂度是O(N*lgN)。
这句话很好理解:假设被排序的数列中有N个数。遍历一次的时间复杂度是O(N),需要遍历多少次呢?至少lg(N+1)次,最多N次。
(01) 为什么最少是lg(N+1)次?快速排序是采用的分治法进行遍历的,我们将它看作一棵二叉树,它需要遍历的次数就是二叉树的深度,而根据完全二叉树的定义,它的深度至少是lg(N+1)。因此,快速排序的遍历次数最少是lg(N+1)次。
(02) 为什么最多是N次?这个应该非常简单,还是将快速排序看作一棵二叉树,它的深度最大是N。因此,快读排序的遍历次数最多是N次。
代码实现:
int partition(int array[], int begin, int end) { int index = begin; int pivot = array[begin]; swap(array[index], array[end]);//将pivot换到最后 for(int i = begin; i != end; i++) {//将小于pivot的元素放到左边,大的放到右边 if (array[i] < pivot) swap(array[index], array[i]);
++index; } swap(array[index], array[end]); return index; } void quickSort(int array[], int begin, int end) { if (begin >= end) return; int position = partition(array, begin, end); quickSort(array, begin, position - 1); quickSort(array, position + 1, end); }
3.插入排序之简单插入排序
其基本思想是:把待排序的记录按其关键码值的大小逐个插入到一个已经排好序的有序序列中,直到所有的记录插入完为止,得到一个新的有序序列。
实现代码:
//插入排序 void InsertionSort(int a[], int size) { int i; //有序区间的最后一个元素的位置,i+1就是无序区间最左边元素的位置 for(i = 0; i < size-1; ++i){ int tmp = a[i + 1]; //tmp是待插入到有序区间的元素,即无序区间最左边的元素 int j = i; while(j >= 0 && tmp < a[j]){ //寻找插入的位置 a[j + 1] = a[j]; //比tmp大的元素都往后移动 --j; } a[j + 1] = tmp; } }
4.插入排序之希尔排序
希尔排序原理:
教科书式表述:
先取一个小于n的整数d1作为第一个增量,把文件的全部记录分组。所有距离为d1的倍数的记录放在同一个组中。先在各组内进行直接插入排序;然后,取第二个增量d2<d1重复上述的分组和排序,直至所取的增量dt=1(dt<dt-1<…<d2<d1),即所有记录放在同一组中进行直接插入排序为止。
图解:
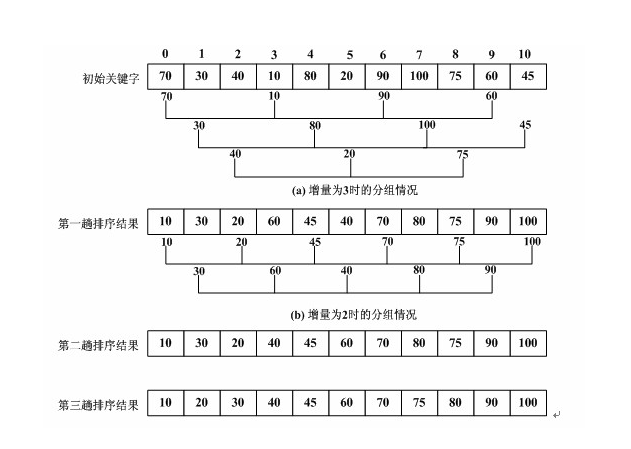
ps:趟数和增量序列的选取有关
代码实现:
/* 希尔插入排序过程 a - 待排序数组 s - 排序区域的起始边界 delta - 增量 len - 待排序数组长度 */ void shellInsert(int a[], int s, int delta, int len) { int temp, i, j, k; for (i = s + delta; i < len; i += delta)//i为未排序数组的第一个数字位置 { for(j = i - delta; j >= s; j -= delta) if(a[j] < a[i])break; temp = a[i]; for (k = i; k > j; k -= delta) { a[i] = a[i - delta]; } a[k + delta] = temp; } } /* 希尔排序 a - 待排序数组 len - 数组长度 */ void shellSort(int a[], int len) { int temp; int delta; //增量 //Hibbard增量序列公式 delta = (len + 1)/ 2 - 1; while(delta > 0) //不断改变增量,对数组迭代分组进行直接插入排序,直至增量为1 { for (int i = 0; i < delta; i++) { shellInsert(a, i, delta, len); } delta = (delta + 1)/ 2 - 1; } } void shellSort2(int a[], int len) { int temp; int delta; //增量 //希尔增量序列公式 delta = len / 2; while(delta > 0) { for (int i = 0; i < delta; i++) { shellInsert(a, i, delta, len); } delta /= 2; } }
5.选择排序之简单选择排序
选择排序的基本思想:
每一趟在n-i+1(i=1,2,3…,n-1)个记录中选取关键字最小的记录与第i个记录交换,并作为有序序列中的第i个记录。
例如:
待排序列: 43,65,4,23,6,98,2,65,7,79
第一趟: 2,65,4,23,6,98,43,65,7,79
第二趟: 2,4,65,23,6,98,43,65,7,79
第三趟: 2,4,6,23,65,98,43,65,7,79
第四趟: 2,4,6,7,43,65,98,65,23,79
第五趟: 2,4,6,7,23,65,98,65,43,79
第六趟: 2,4,6,7,23,43,98,65,65,79
第七趟: 2,4,6,7,23,43,65,98,65,79
第八趟: 2,4,6,7,23,43,65,65,98,79
第九趟: 2,4,6,7,23,43,65,65,79,98
选择排序的时间复杂度为:O(n^2),空间复杂度:O(1)
选择排序是不稳定的;示例图如下:
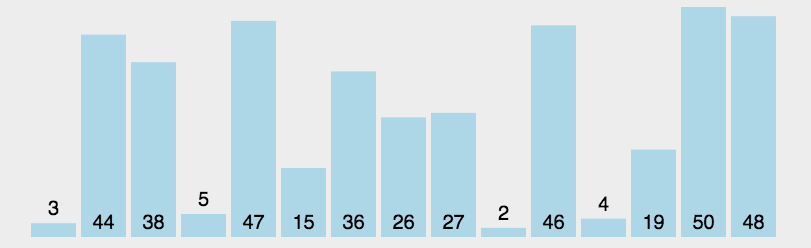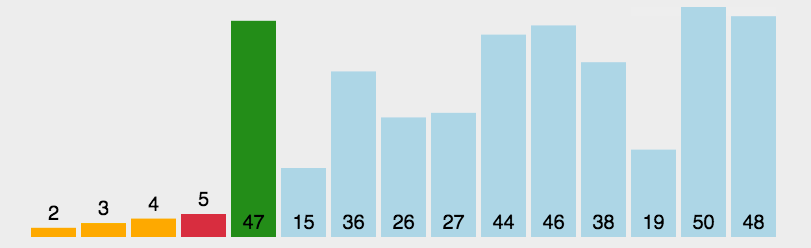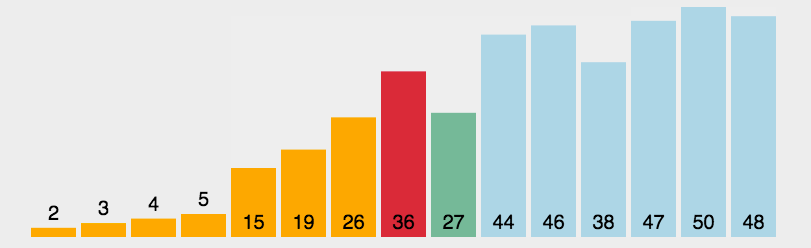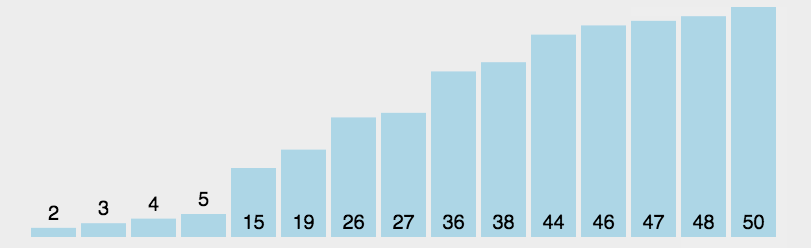
代码实现:
void SelectSort(int a[],int n) //选择排序 { int min; for(int i=0;i<n-1;i++) //每次循环数组,找出最小的元素,放在前面,前面的即为排序好的 { min=i; //假设最小元素的下标 for(int j=i+1;j<n;j++) //将上面假设的最小元素与数组比较,交换出最小的元素的下标 if(a[j]<a[min]) min=j; //若数组中真的有比假设的元素还小,就交换 if(i!=min) swap(a[i], a[min]); } }
未完待续 经典排序算法总结(二)https://www.cnblogs.com/bupt213/p/11377953.html