一个窗口函数在一系列与当前行有某种关联的表行上执行一种计算。
这与一个聚集函数所完成的计算有可比之处。
但是窗口函数并不会使多行被聚集成一个单独的输出行,这与通常的非窗口聚集函数不同。
取而代之,行保留它们独立的标识。在这些现象背后,窗口函数可以访问的不仅仅是查询结果的当前行。
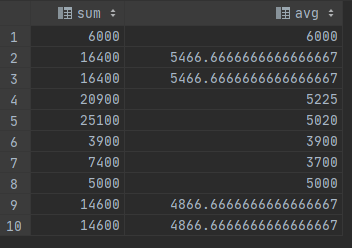
下面是一个例子用于展示如何将每一个员工的薪水与他/她所在部门的平均薪水进行比较:
SELECT depname, empno, salary, avg(salary) OVER (PARTITION BY depname) FROM empsalary;

最开始的三个输出列直接来自于表empsalary,并且表中每一行都有一个输出行。
第四列表示对与当前行具有相同depname值的所有表行取得平均值(这实际和非窗口avg聚集函数是相同的函数,但是OVER子句使得它被当做一个窗口函数处理并在一个合适的窗口帧上计算)。
一个窗口函数调用总是包含一个直接跟在窗口函数名及其参数之后的OVER子句。这使得它从句法上和一个普通函数或非窗口函数区分开来。OVER子句决定究竟查询中的哪些行被分离出来由窗口函数处理。
OVER子句中的PARTITION BY子句指定了将具有相同PARTITION BY表达式值的行分到组或者分区。对于每一行,窗口函数都会在当前行同一分区的行上进行计算。
OVER上的ORDER BY控制窗口函数处理行的顺序(窗口的ORDER BY并不一定要符合行输出的顺序)。下面是一个例子:
SELECT depname, empno, salary,
rank() OVER (PARTITION BY depname ORDER BY salary DESC) FROM empsalary;
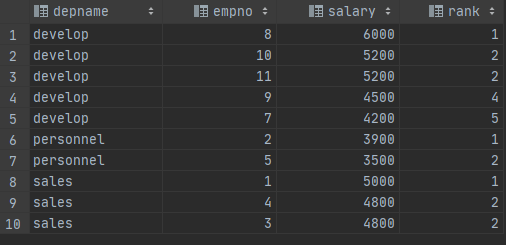
rank函数在当前行的分区内按照ORDER BY子句的顺序为每一个可区分的ORDER BY值产生了一个数字等级。
rank不需要显式的参数,因为它的行为完全决定于OVER子句。
一个窗口函数所考虑的行属于那些通过查询的FROM子句产生并通过WHERE、GROUP BY、HAVING过滤的“虚拟表”。【select 字句的基础上】
窗口函数只允许出现在查询的SELECT列表和ORDER BY子句中。它们不允许出现在其他地方,例如GROUP BY、HAVING和WHERE子句中。
我们已经看到如果行的顺序不重要时ORDER BY可以忽略。PARTITION BY同样也可以被忽略,在这种情况下会产生一个包含所有行的分区。
这里有一个与窗口函数相关的重要概念:对于每一行,在它的分区中的行集被称为它的窗口帧。
(有无order by的区别)一些窗口函数只作用在窗口帧中的行上,而不是整个分区。默认情况下,如果使用ORDER BY,则帧包括从分区开始到当前行的所有行,以及后续任何与当前行在ORDER BY子句上相等的行。如果ORDER BY被忽略,则默认帧包含整个分区中所有的行。
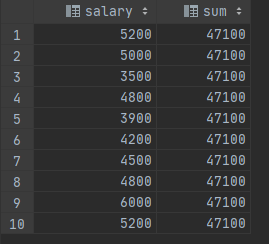
SELECT salary, sum(salary) OVER () FROM empsalary;
SELECT salary, sum(salary) OVER (ORDER BY salary) FROM empsalary;
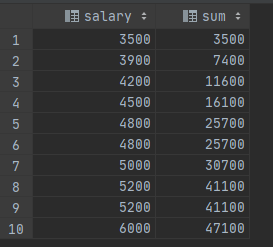
这里的合计是从第一个(最低的)薪水一直到当前行,包括任何与当前行相同的行(注意相同薪水行的结果)。
窗口函数只允许出现在查询的SELECT列表和ORDER BY子句中。它们不允许出现在其他地方,例如GROUP BY、HAVING和WHERE子句中。
这是因为窗口函数的执行逻辑是在处理完这些子句之后。
另外,窗口函数在非窗口聚集函数之后执行。这意味着可以在窗口函数的参数中包括一个聚集函数,但反过来不行。
如果需要在窗口计算执行后进行过滤或者分组,我们可以使用子查询。例如:
SELECT depname, empno, salary, enroll_date
FROM
(SELECT depname, empno, salary, enroll_date,
rank() OVER (PARTITION BY depname ORDER BY salary DESC, empno) AS pos
FROM empsalary
) AS ss
WHERE pos < 3;
(共用相同的窗口行为)当一个查询涉及到多个窗口函数时,可以将每一个分别写在一个独立的OVER子句中。但如果多个函数要求同一个窗口行为时,这种做法是冗余的而且容易出错的。
替代方案是,每一个窗口行为可以被放在一个命名的WINDOW子句中,然后在OVER中引用它。例如:
SELECT sum(salary) OVER w, avg(salary) OVER w
FROM empsalary
WINDOW w AS (PARTITION BY depname ORDER BY salary DESC);