作业要求来自于:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE2/homework/3339
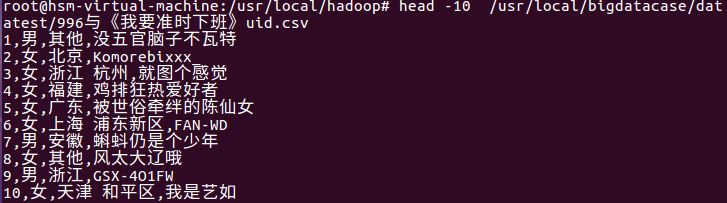
我主要的爬取内容是关于热门微博文章“996”与日剧《我要准时下班》的联系,其中包括两个csv文件— —996与《我要准时下班》.csv与996与《我要准时下班》uid.csv。其中996与《我要准时下班》.csv的内容是用户的id、发表微博的内容、微博的点赞数,996与《我要准时下班》.csv的内容是基于996与《我要准时下班》.csv的用户id获取用户的性别、所在地与昵称。
Hadoop综合大作业 要求:
1.将爬虫大作业产生的csv文件上传到HDFS



上传文件到hdfs
2.对CSV文件进行预处理生成无标题文本文件
3.把hdfs中的文本文件最终导入到数据仓库Hive中
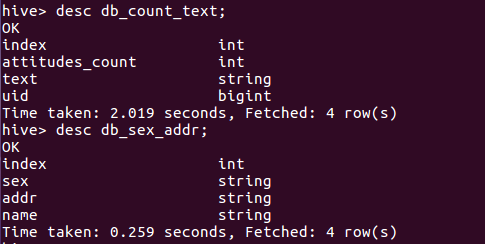
db_count_text与db_sex_addr表的属性

创建数据库

查看数据库
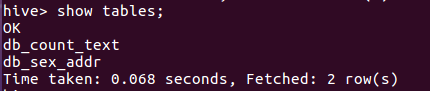
查看数据库中的表
4.在Hive中查看并分析数据
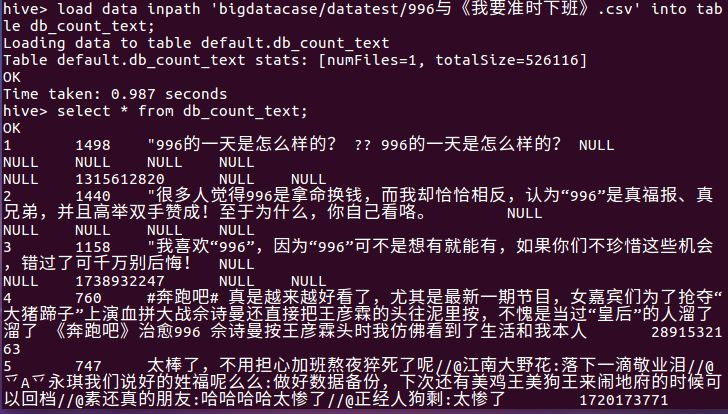
查看db_count_text的全部数据

查看db_sex_addr的全部数据
5.用Hive对爬虫大作业产生的进行数据分析,写一篇博客描述你的分析过程和分析结果。(10条以上的查询分析)
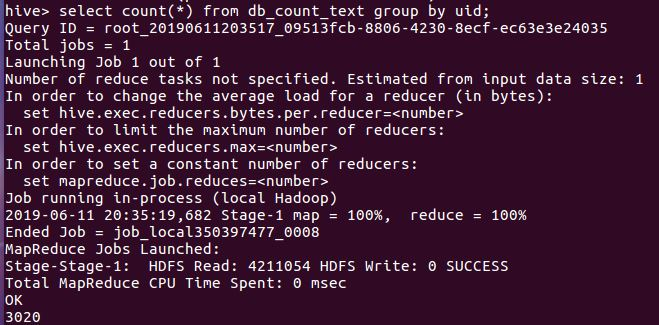
①统计db_count_text表中的条目数
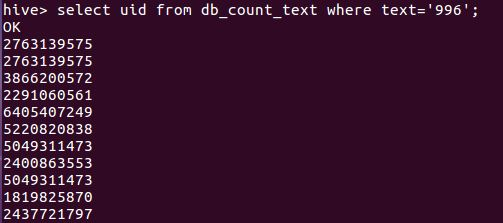
②查询db_count_text表中微博中有关于“996”的用户ID
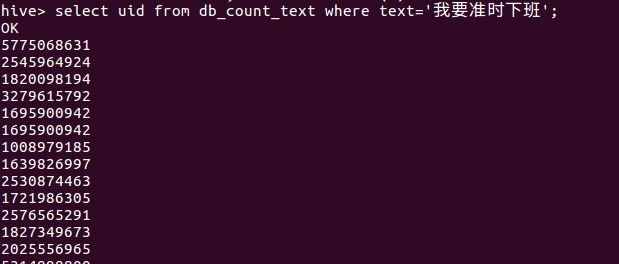
③查询db_count_text表中微博中有关于“我要准时下班”的用户ID
④查看db_sex_addr表中的所在地与该所在地的用户

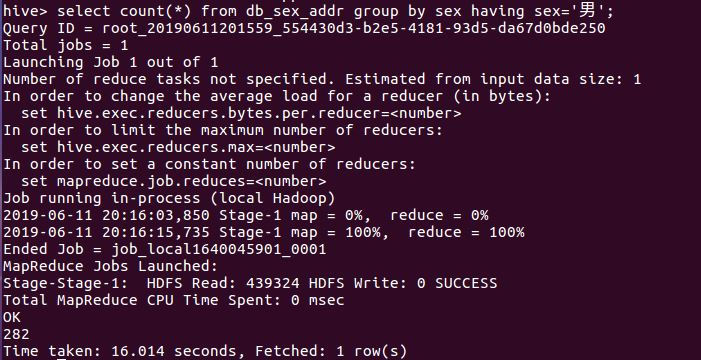
⑤查看db_sex_addr表中的男生的用户数
⑥查看db_sex_addr表中的女生的用户数
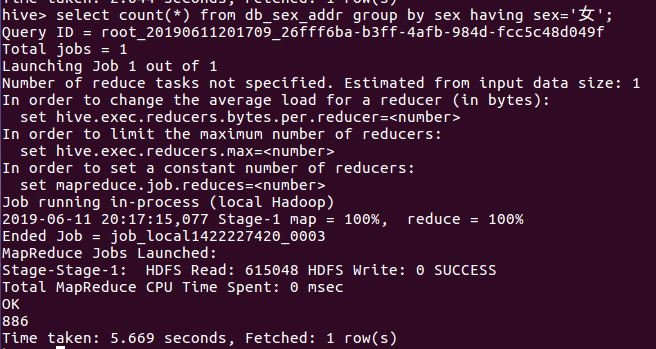
分析:从查询的统计的性别可以看出女性的比例高于男性,不仅说明微博活跃度中女性占比较高,同时在关于996与日剧《我要准时下班》的话题中参与度最高。
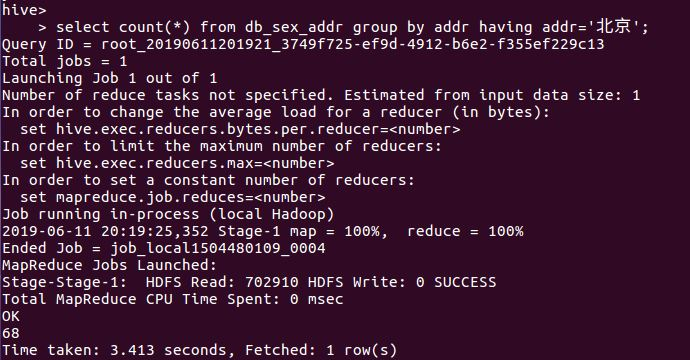
⑦查看db_sex_addr表中的所在地为北京的用户数
⑧查看db_sex_addr表中的所在地为广东的用户名

⑨查看db_sex_addr表中的所在地为浙江,性别为男性的用户名

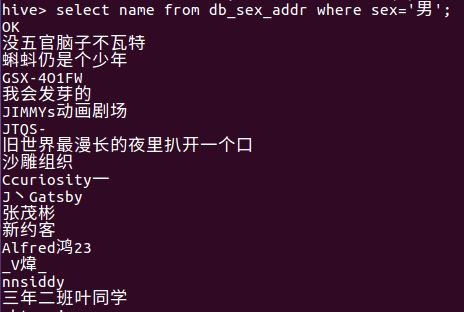
⑩查看db_sex_addr表中的所有性别为男性的用户名