作业要求来自于:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE2/homework/2851
1. 简单说明爬虫原理
通过程序模拟浏览器请求站点的行为,把站点返回的HTML代码/JSON数据/二进制数据(图片、视频) 爬到本地,进而提取自己需要的数据,存放起来使用。
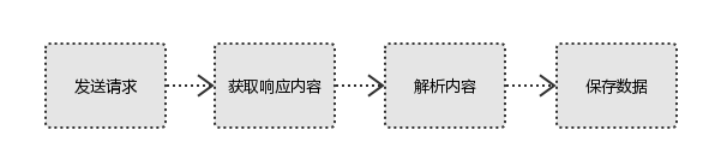
2. 理解爬虫开发过程
1).简要说明浏览器工作原理;
HTTP协议的作用原理包括四个步骤:
①连接:Web浏览器与Web服务器建立连接,打开一个称为socket(套接字)的虚拟文件,此文件的建立标志着连接建立成功。
②请求:Web浏览器通过socket向Web服务器提交请求。HTTP的请求一般是GET或POST命令(POST用于FORM参数的传递)。GET命令的格式为: GET 路径/文件名 HTTP/1.0 文件名指出所访问的文件,HTTP/1.0指出Web浏览器使用的HTTP版本。
③ 应答:Web浏览器提交请求后,通过HTTP协议传送给Web服务器。Web服务器接到后,进行事务处理,处理结果又通过HTTP传回给Web浏览器,从而在Web浏览器上显示出所请求的页面。
④关闭连接:当应答结束后,Web浏览器与Web服务器必须断开,以保证其它Web浏览器能够与Web服务器建立连接。
2).使用 requests 库抓取网站数据;
requests.get(url) 获取校园新闻首页html代码
import requests #requests.get(url) 获取校园新闻首页html代码 url="http://www.gzcc.cn/"; r=requests.get(url); r.raise_for_status(); r.encoding=r.status_code; print(r.text);

3).了解网页
写一个简单的html文件,包含多个标签,类,id
<!DOCTYPE html> <html> <head> <style type="text/css"> div,span{ font-size:20px; color: #0000FF; } .one{ font-size:30px; } </style> <meta charset="UTF-8"> <title></title> <script src="js/jquery-1.9.0.js"></script> <script src="js/jsseclector.js"></script> </head> <body> <p align="center" class="one" id="一"><font size="5" >第一章:jQuery概述</font></p> <span id="1-1">1.1 初识jQuery <div> <a href="" id="1.1.1">--1.1.1 什么是jQuery</a></div> <div> --1.1.2 jQuery的优势</div> <div> --1.1.3 下载jQuery脚本文件和配置jQuery环境</div> <div> --1.1.4 第一个简单的jQuery程序</div> </span> <span id="1-2">1.2 jQuery对象和DOM对象 <div> <a href="">--2.1.1 DOM对象</a></div> <div> --2.1.2 jQuery对象</div> </span> <span id="1-3" >1.3 jQuery开发工具 <div> <a href="">--3.1.1 使用Dreamweaver编辑jQuery程序</a></div> <div> --3.1.2 调试jQuery程序</div> </span> </body> </html>
4).使用 Beautiful Soup 解析网页;
通过BeautifulSoup(html_sample,'html.parser')把上述html文件解析成DOM Tree
select(选择器)定位数据
①找出含有特定标签的html元素:
print(soup.select("div"));

②找出含有特定类名的html元素:
print(soup.select(".thirdthSize"));
![]()
③找出含有特定id名的html元素:
print(soup.select("#oneBytwo"));

3.提取一篇校园新闻的标题、发布时间、发布单位
import requests import bs4 from bs4 import BeautifulSoup #获取网页 url="http://news.gzcc.cn/html/2019/xiaoyuanxinwen_0320/11029.html"; r=requests.get(url); r.encoding=r.apparent_encoding; text=r.text; #print(text); #解析网页 soup=BeautifulSoup(text,"html.parser"); #新闻标题 title=soup.select(".show-title"); print(title); #发布时间与发布单位 time=soup.select(".show-info"); print(time);
