该作业要求来自于:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE2/homework/2646
1.字符串操作:
- 解析身份证号:生日、性别、出生地等。
#获取身份证号中的出生日期与性别 identify=input("请输入您的身份证号:"); while(len(identify)!=18): print("您的身份证号码输入错误"); identify = input("请重新输入您的身份证号:"); year=identify[6:10]; month=identify[10:12]; day=identify[12:14]; print("出生日期是{}-{}-{}".format(year,month,day)); sex=identify[-2]; if int(sex)%2==0: print("性别为女"); else: print("性别为男")

- 凯撒密码编码与解码
#凯撒密码编码与解码 word=input("请输入一段字母:"); n=input("请输入偏移值:"); s=ord("a"); e=ord("z"); choose=input("编码请按1,解码请按2:"); print("凯撒密码编码:",end="") for i in word: if s<=ord(i)<=e: if choose == "1": print(chr(s+(ord(i)-s+int(n))%26),end=""); elif choose == "2": print("凯撒密码解码:", end="") print(chr(s + (ord(i)-s-int(n)) % 26), end=""); else: print("您的选择输入错误!") else: print(i,end="");


- 网址观察与批量生成
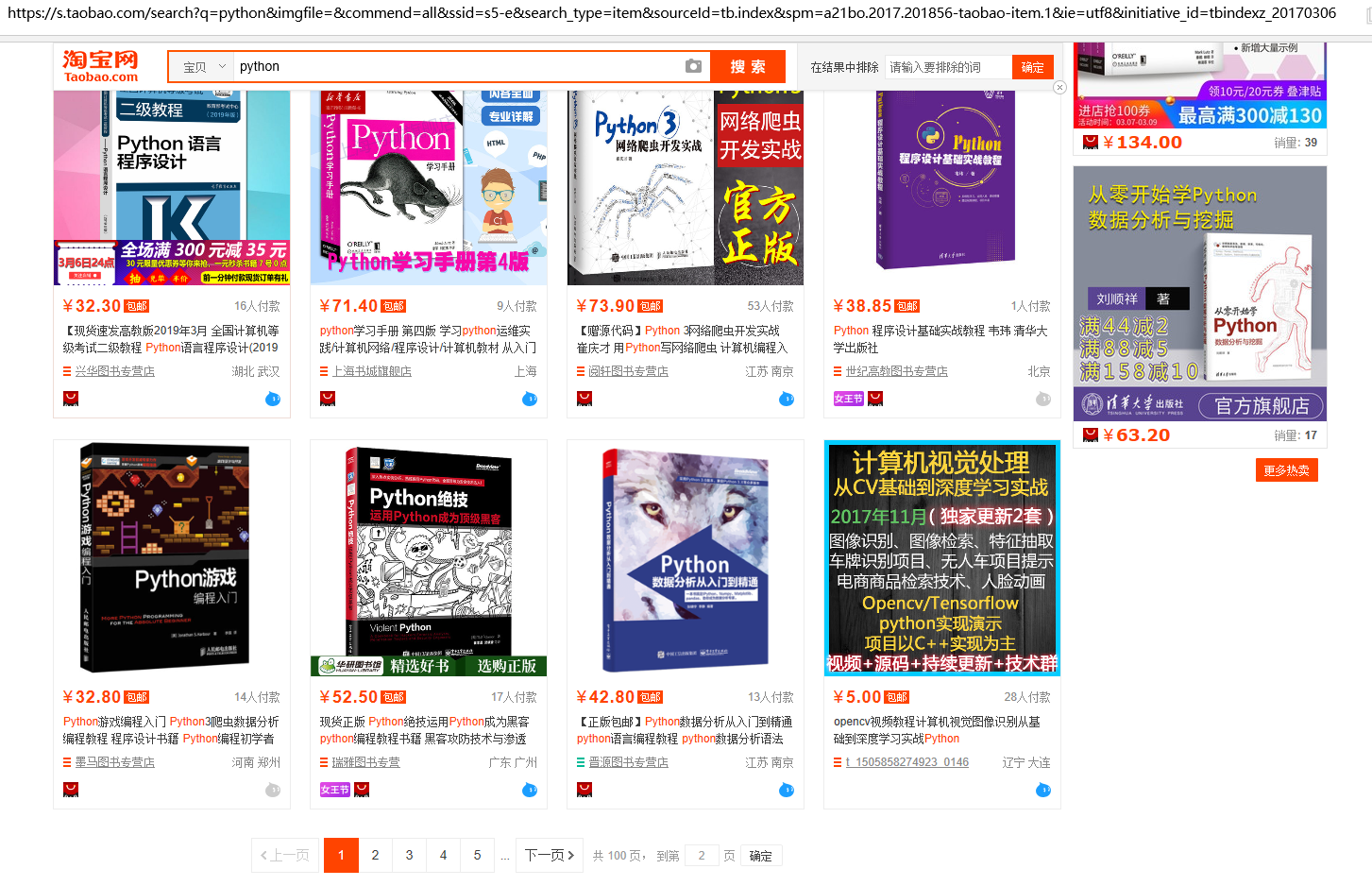
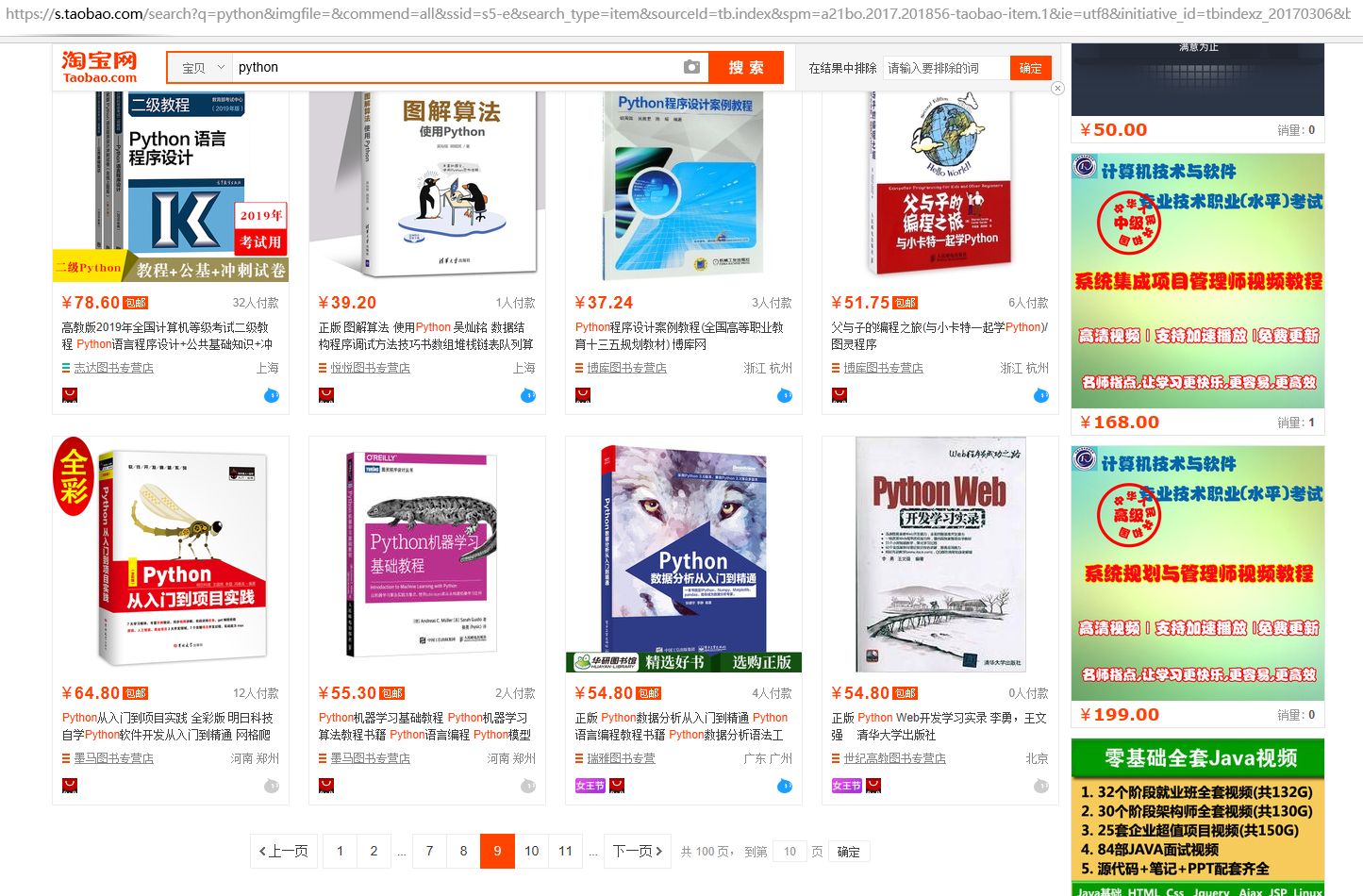
#观察淘宝搜索页并生成10页的搜索结果 print(r"淘宝搜索‘python’结果如下"); url="https://s.taobao.com/search?q=python&imgfile=&commend=all&ssid=s5-e&search_type=item&sourceId=tb.index&spm=a21bo.2017.201856-taobao-item.1&ie=utf8&initiative_id=tbindexz_20170306" s="&bcoffset=3&ntoffset=3&p4ppushleft=1%2C48&s=" print("第1页网址为{}".format(url)); for i in range(9): arg=url+s+str(i*44); print("第{}页网址为{}".format(i+2,url));

2.英文词频统计预处理
- 下载一首英文的歌词或文章或小说,保存为utf8文件。
- 从文件读出字符串。
- 将所有大写转换为小写
- 将所有其他做分隔符(,.?!)替换为空格
- 分隔出一个一个的单词
- 并统计单词出现的次数。
#文件操作 def readFile(): f=open("speech.txt"); text=f.read(); print(text); f.close(); return text; #文本操作 def splitText(): dict={} s="124.,," t=readFile().lower(); #文本中的大写字母转换为小写字母 for i in s: t=t.replace(i,''); #替换文本中的字符 t = t.split(); #分割文本 for j in t: dict[j]=t.count(j); #'单词与单词出现次数存入字典 return dict; #排序 def sortDict(): d=sorted(splitText().items(),reverse=True,key=lambda d:d[1]); '元组排序,降序,按值排序' print("speech文本统计词频如下: "); for i in range(10): print(d[i][0],"--",d[i][1]); def main(): sortDict(); main();
截图如下:

