内容目录
- 为什么要学习SPSS
- spss发展史
- spss操作界面
- spss基本使用方式
- SPSS的常用操作
- 数据管理
- spss制作图表
- 使用spss进行描述统计分析
1.为什么要学习SPSS
统计分析软件是数据分析的主要工具
统计设计完成后,完整的分析过程包括
- 数据的搜集
- 数据的整理
- 数据的分析
- 结果的报告
统计学为数据分析提供一套完整的科学的方法论,统计软件为数据分析提供了实现手段。
spss的基本特点
1.1优势
- 功能强大
- 兼容性好
- 易用性强,是应用统计人员的首选
- 扩展性高(以一种不同的方式)
1.2劣势
- 计算速度相对较慢
- 在统计模型的纳入上速度较慢
2.简单说一下spss的发展历史
SPSS名称
最开始:名称 Statistical Product and Service Solutions
现在:IBM SPSS Statistics
2.1 发展历程
世界上最早的统计分析软件
60年代:美国斯坦福三位研究生研发
70年代:1975年成立法人组织、在芝加哥组建了SPSS总部,退出SPSS中小型机版-SPSSX
80年代:微机版(V1~4)SPSS/PC+
90年代:Windows版(V6~10)
本世纪:11~25,中文版,2010年被IBM收购
现在最新版本是25,中间可能会有一些bug,但基本问题不大,可以正常使用
2.2 SPSS与其他分析软件对比
spss是最早的统计分析软件,发展到现在,已经比较成熟,同类的分析软件有SAS和R
SAS:统计分析软件,有一定难度,难上手,收费的,市场研究用的比较多
R:是一个编程语言,会python就没必要学它了,开源的,也是有各种包
SPSS相对简单,易上手,功能也不差,而且现在被IBM收购之后,与office无缝衔接,很好用,SPSS可以跟python R等连接使用,很方便。
3.spss操作界面
3.1工作名称与存储名称
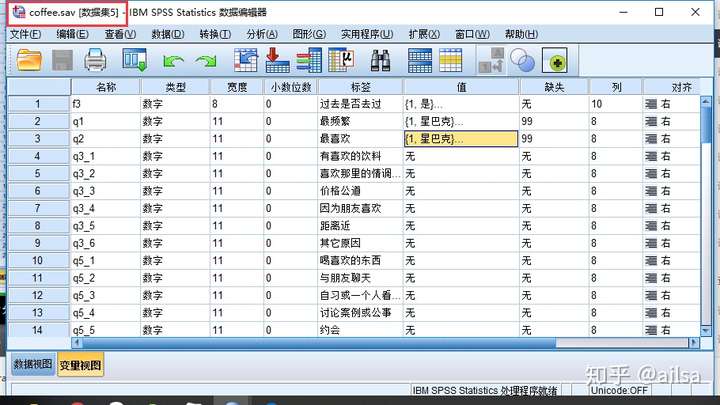
coffee.sav 为文件存储名称
[数据集5]为文件工作名称
详细说明:
若你是从硬盘上打开的文件,会自动读取文件存储名称,另外spss会按照编号编制一个数据集X的名称,以便区分,不同盘的文件名相同的情况。
若是新建文件,则文件尚未保存到硬盘上,命名为:按照编号无标题X,等你保存的时候可以修改
3.2四大窗口
- 数据编辑窗口
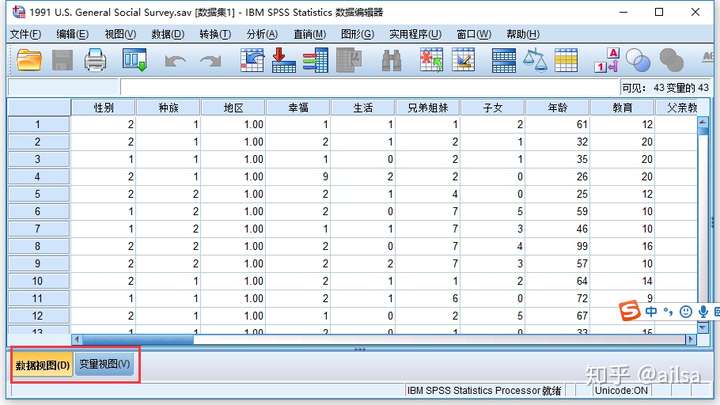
跟Excel真的很像,就是一个电子表格
数据视图:主操作界面
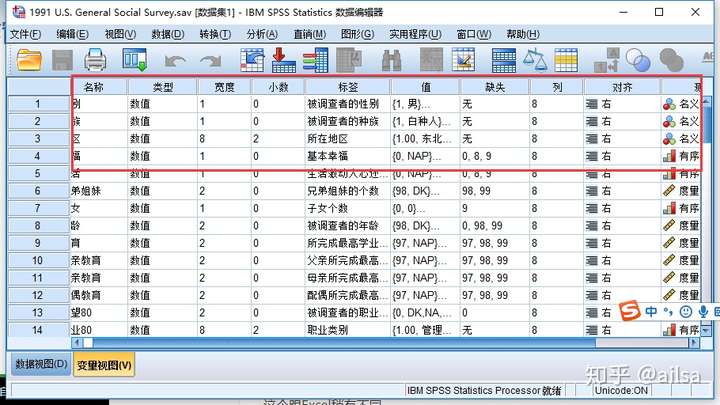
变量视图:定义变量
这个跟Excel稍有不同
- 结果浏览窗口
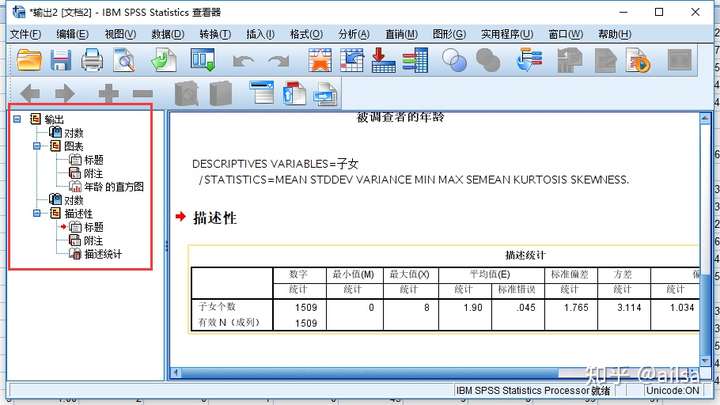
我们选择相应的统计分析之后,分析结果都会在单独的窗口呈现
统计软件里最美观的结果输出
提供类似资源管理器的界面和操作方式
- 语法窗口
如何打开语法窗口
打开一个新的语法窗口
【文件】--【新建/打开】--【语法】
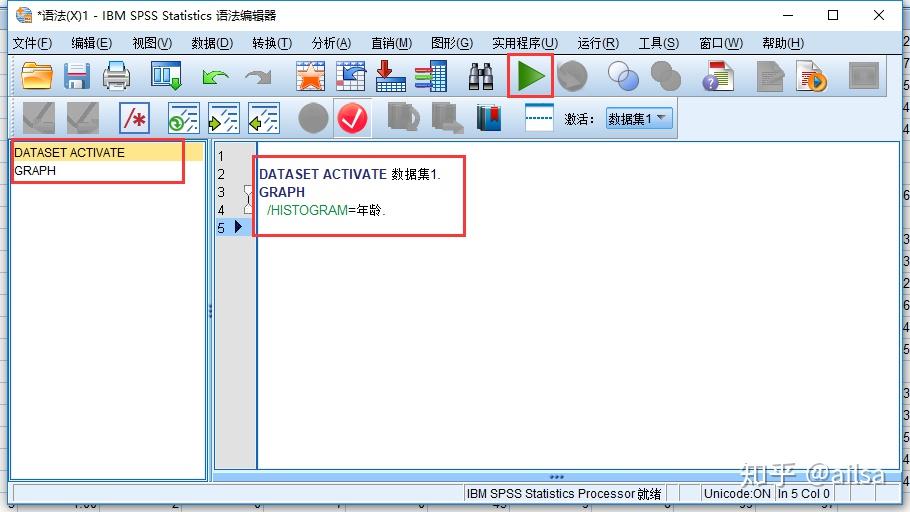
执行语法,可以看到结果
spss的执行原理
1.选择操作按钮
2.转义成可执行的spss语言代码
3.生成分析结果
- 脚本窗口
打开方式
python脚本
Basic脚本
【文件】--【新建/打开】 -- 【脚本】
用于二次开发,用的不多,了解就可以了
4.spss基本使用方式
4.1菜单式对话框介绍
采用菜单方式和对话框方式,操作简单,易于上手,功能也不差
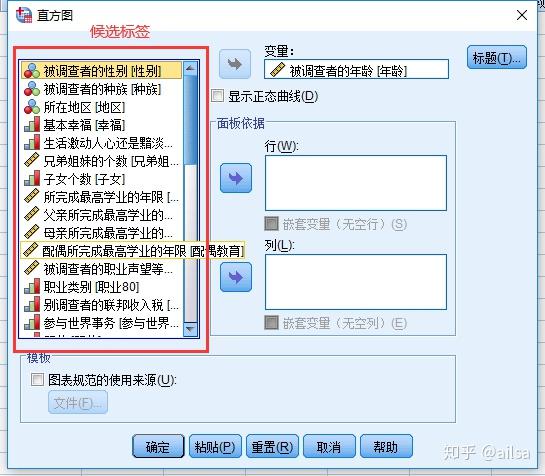
候选变量列表框
测量尺度+标签+变量名方式
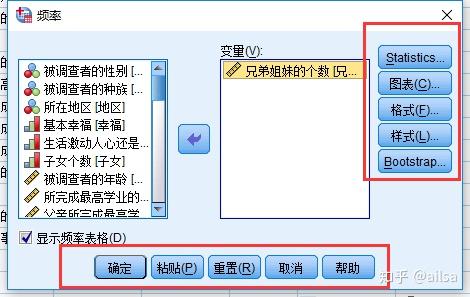
五个标准按钮
- 确定、取消
- 粘贴:用于自动生成SPSS程序
- 重置:恢复对话框为初始状态
- 帮助:方法,用法介绍
其他按钮
- 多数情况下回弹出二级对话框
- 灰色表示不可用
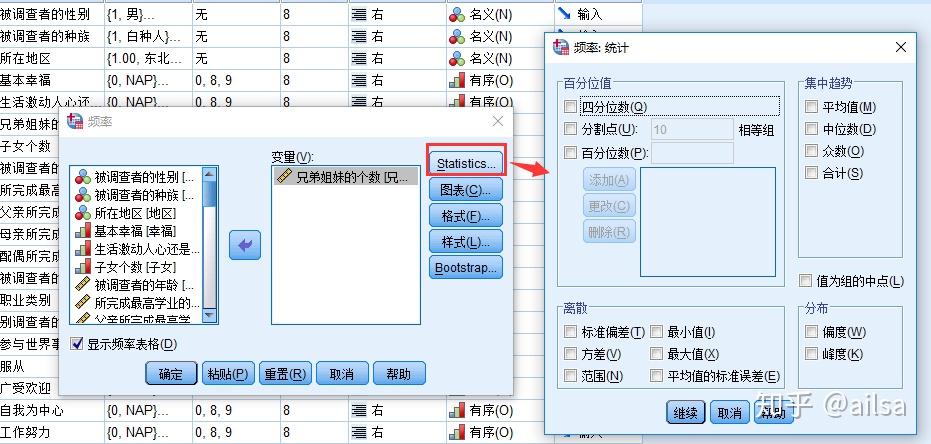
二级对话框
单选框(组)
- 一般均成组出现,多选一
复选框(组)
- 可成组,也可单独出现,多选多
文本框
下拉框
4.2变量存储类型
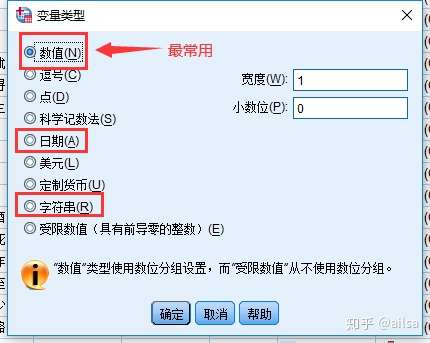
- 数值型:应用最为广泛
- 字符型:由于分析、整理都较困难,建议少量使用,改为编码录入
- 日期型:实际是特殊的数值型变量,尽量少用
注:大部分情况下,使用数值就可以了
其他附加属性
变量名与变量值标签
可用于对变量及变量值含义进行说明,使结果更易于阅读
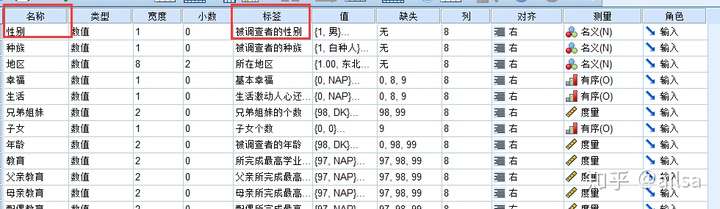
缺失值
除非问卷中有特殊编码,否则按默认情况处理
4.3 spss如何导入外部数据
4.3.1.如何读取Excel文件
我们在工作中,经常用到导入Excel文件,其实这个操作也很简单
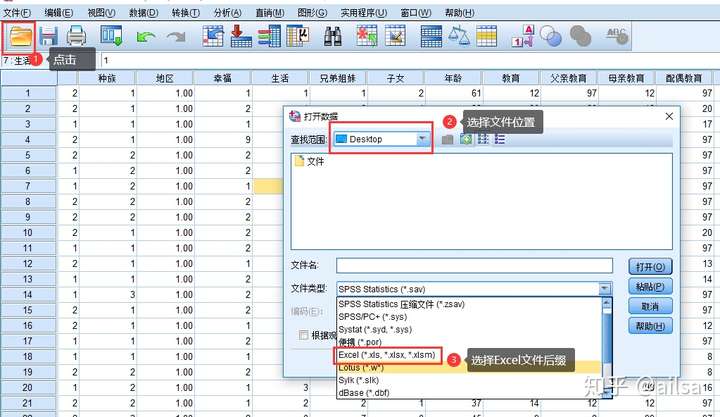
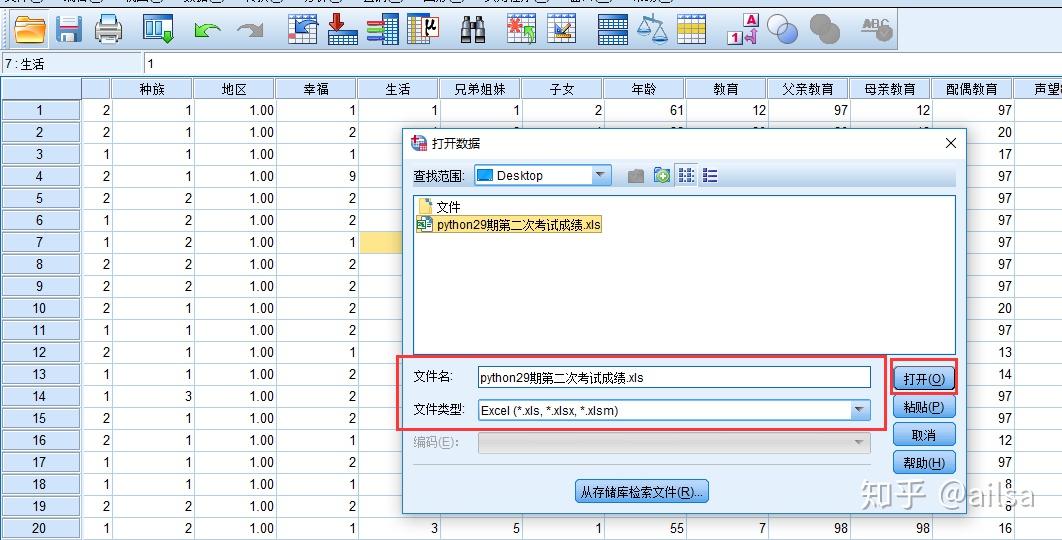
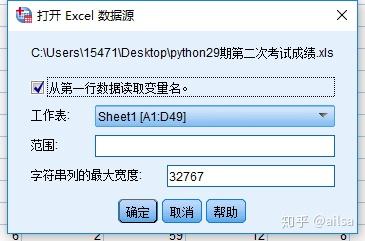
4.3.2.如何导入数据库文件
通过ODBC资源管理器实现
这里以mysql数据库为例,如果没有ODBC驱动的话,需要安装,这里提供mysql的ODBC驱动网盘链接
链接: https://pan.baidu.com/s/1C-Gky6o0aql0qXO54NZ6qw 提取码: 36ya
安装好驱动以后,需要做以下步骤
step1:【文件】--【导入数据】--【数据库】--【新建查询】
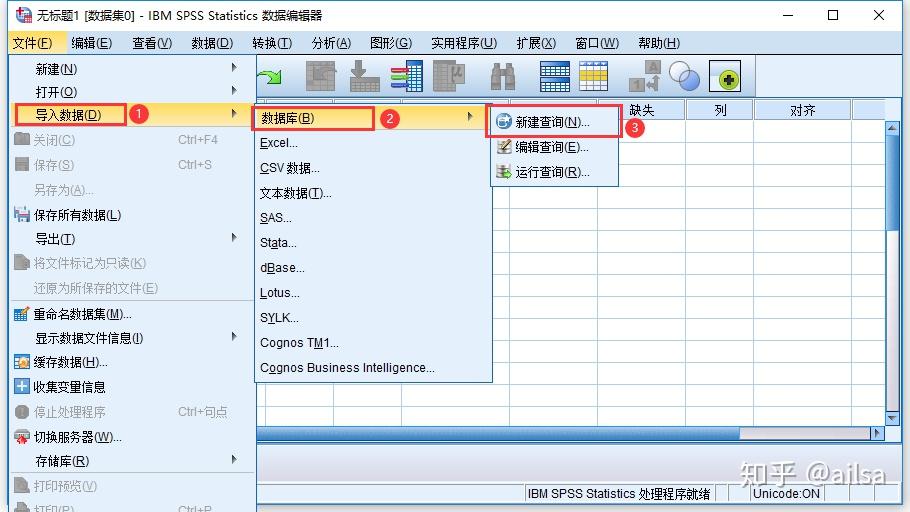
step2:【添加ODBC数据源】--【用户DNS】--【添加】--【mysql的相关驱动】
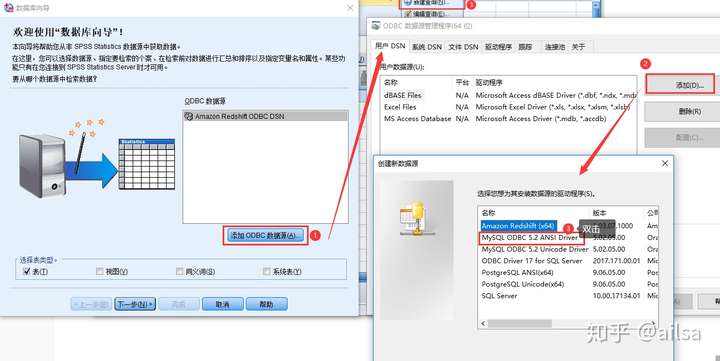
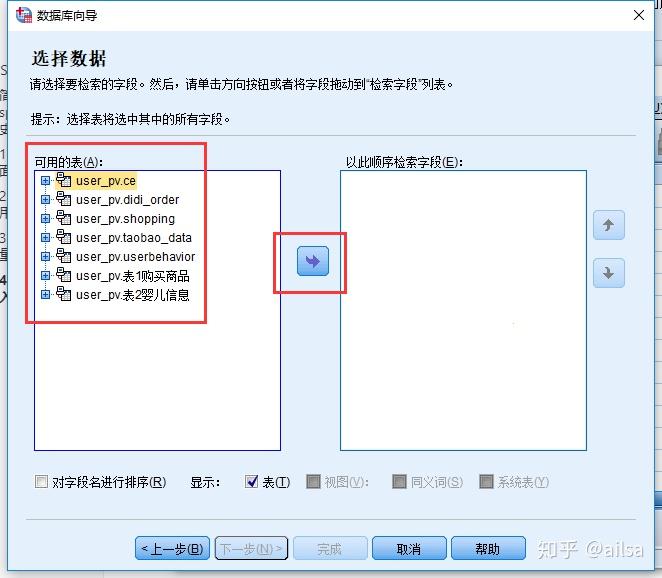
step3:按照图片提示填入相关信息
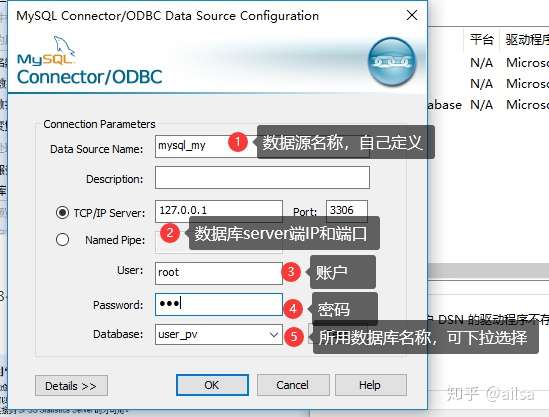
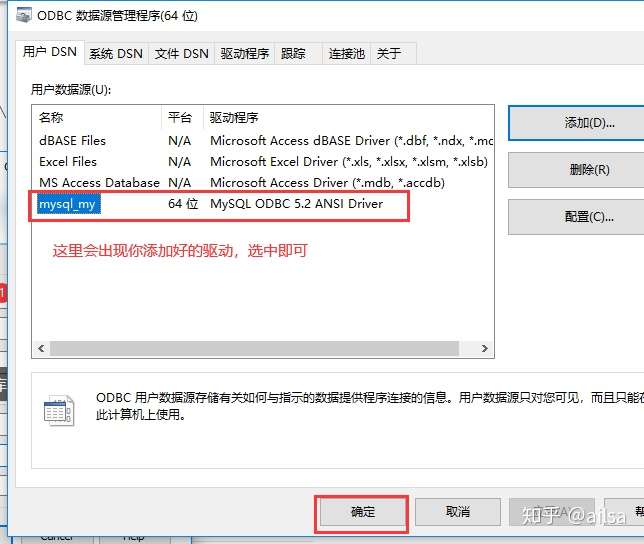
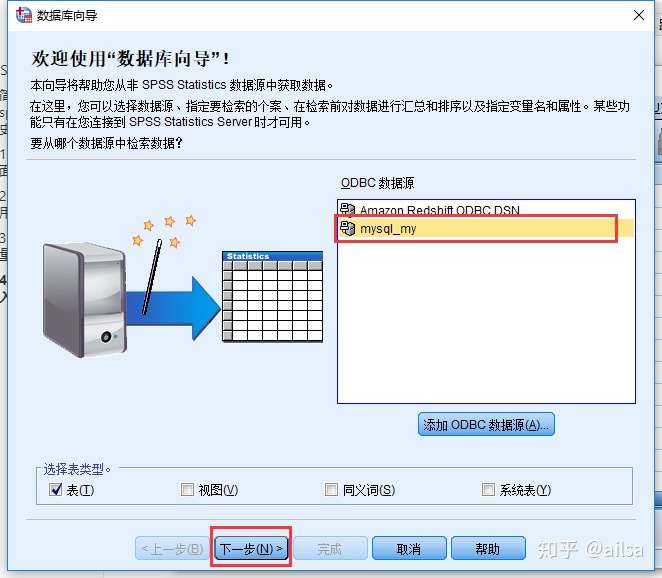
step4:选择你库中要导入的表,可以选择整张表,也可选择一张表的某些字段,确定即可
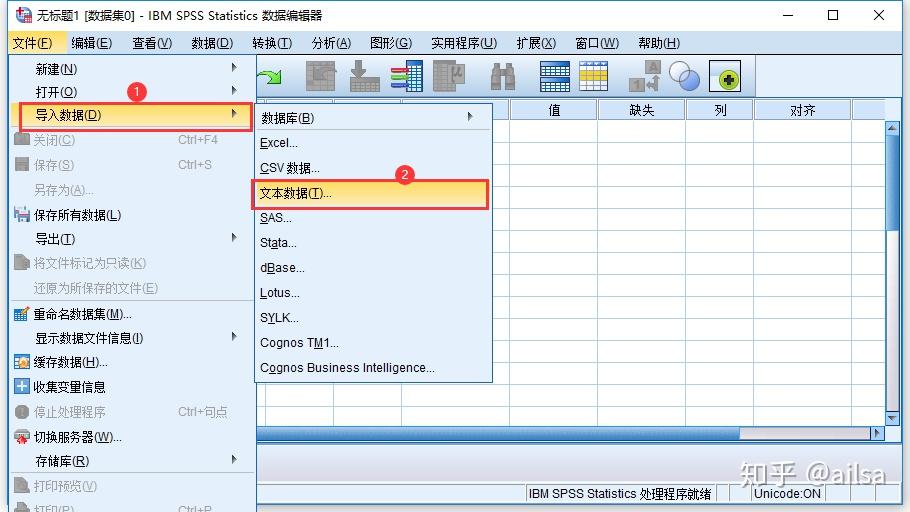
4.3.3.如何导入文本文件
step1:【导入数据】-- 【文本数据】
step2:选择文件位置--选中文件--打开
点击下一步
step2:根据实际情况选择
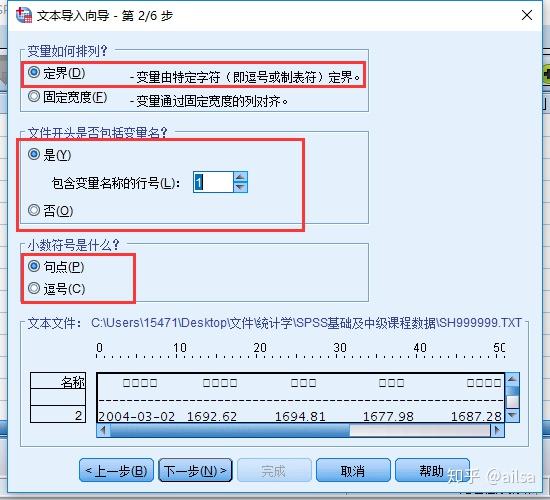
step3:按照实际情况选择,基本默认就能满足
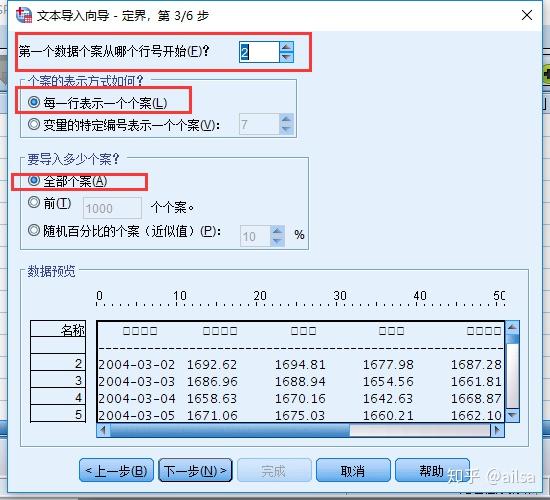
step4:
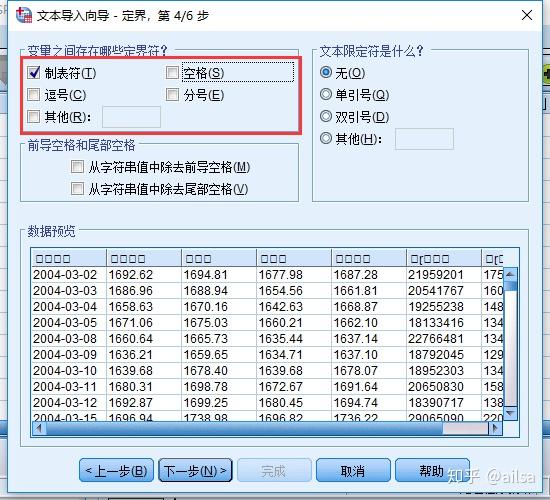
step5
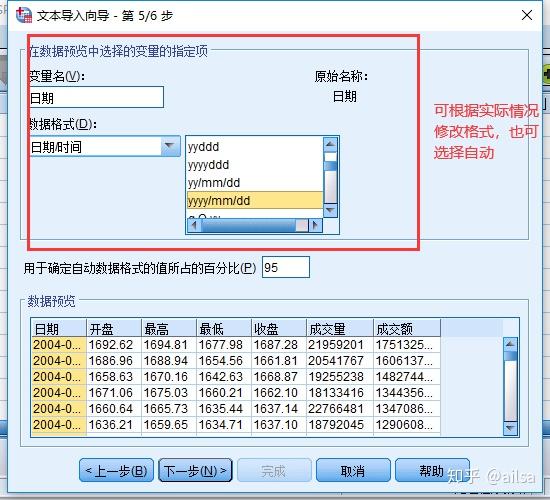
step6
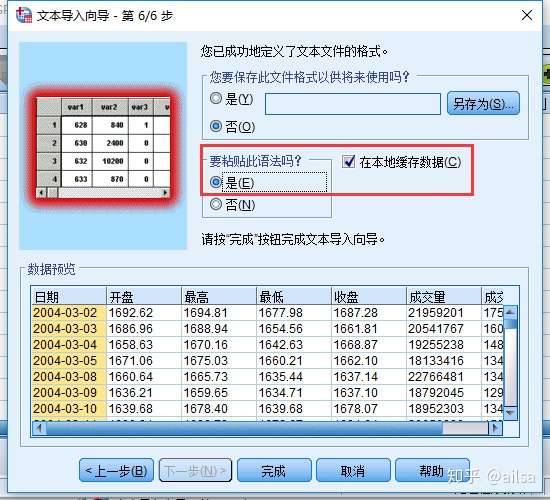
step7
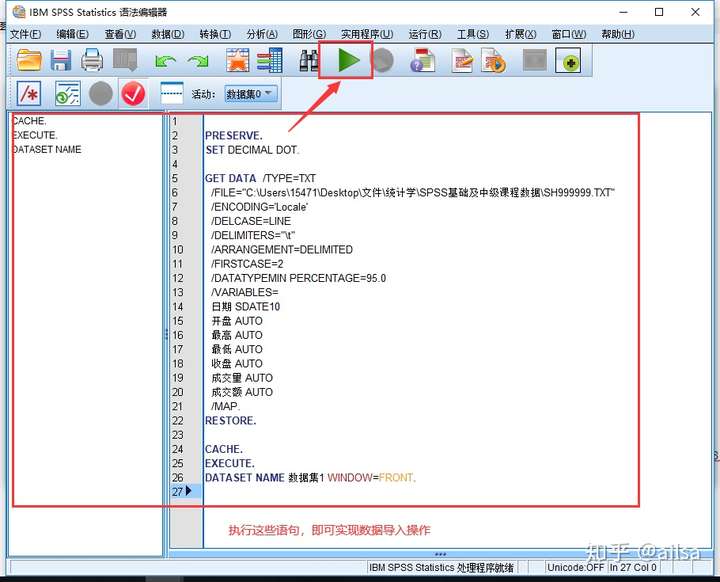
数据已成功
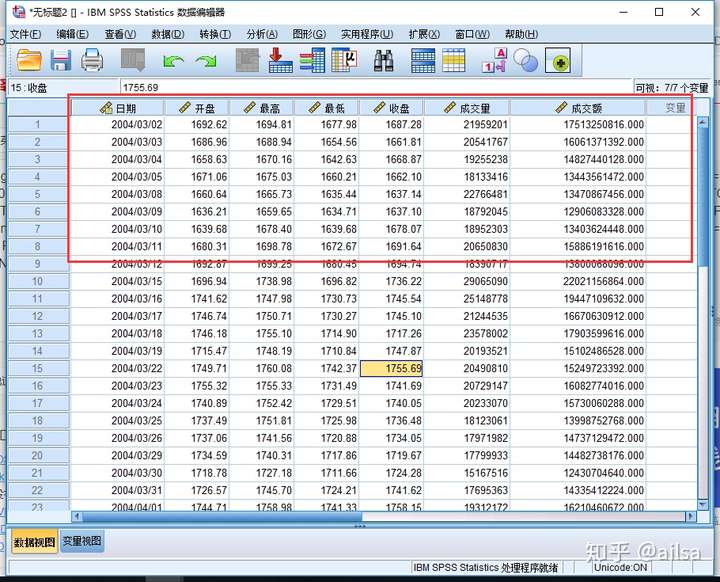
好的,以上就是我们经常遇到的导入外部文件的问题
4.4 保存与导出
4.4.1源数据文件的保存
1.打开已有文件:ctrl+S保存即可
2.新建的文件:另存为指定的格式
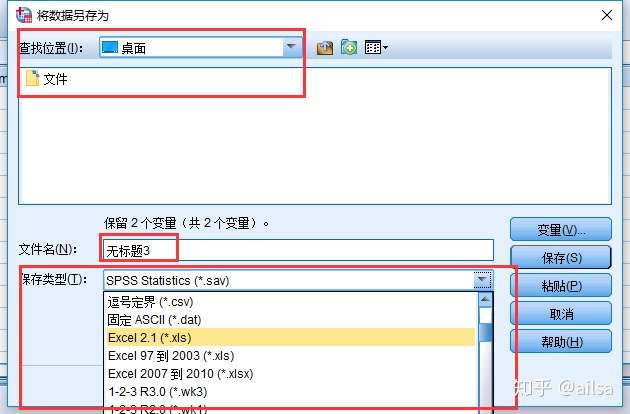
3.保存部分变量
spss的灵活之处
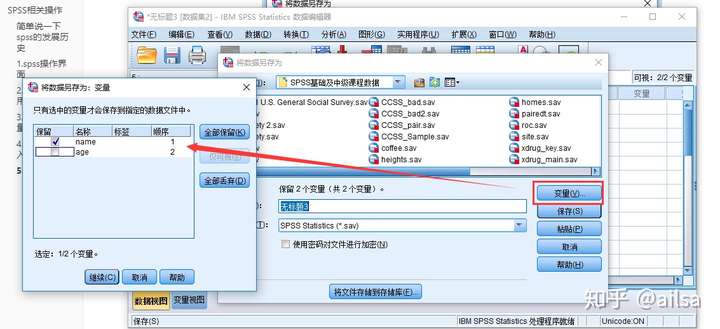
保存为Excel格式
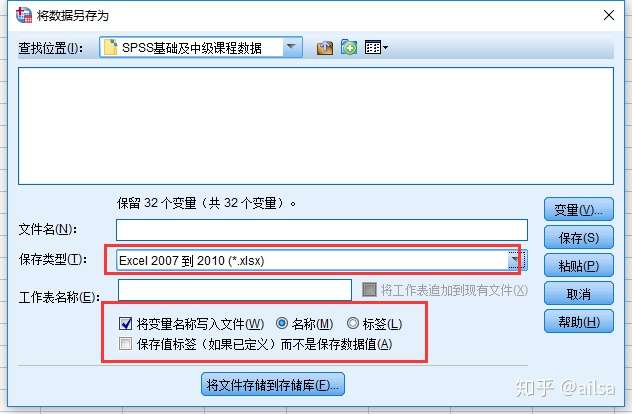
好处:
1.可以保存名称,也可保存标签
2.可追加保存到同一个Excel文件的不同sheet
3.还可以直接保存值标签(例如:性别一列,0代表男,1代表女,保存值标签直接保存的是男或者女,更直观)
注:保存为其他格式时,spss尽量做到兼容,但难免会出现问题,这个是无法避免的
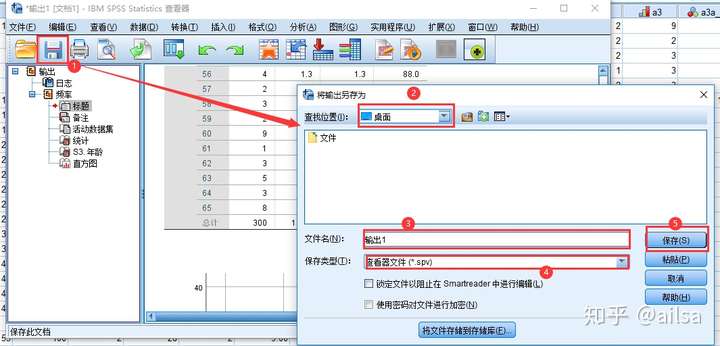
4.4.2结果窗口的保存与导出
保存
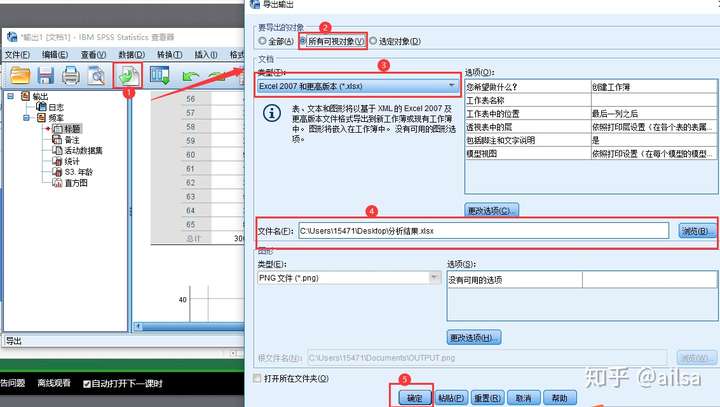
导出
常用的是导出Excel
结果输出
当然除了保存和导出,我们还可以对某个图或某个表进行复制粘贴操作,这个在Excel中和Word中都有很好的兼容
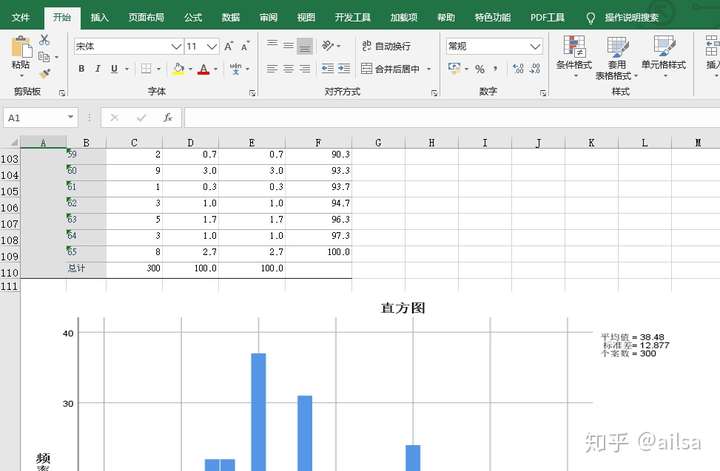
5.SPSS的常用操作
5.1数据录入
统计分析大部分都是针对二维表来实现的,我们都见过哪些二维表呢?
Excel中:行:数字组成 列:字母组成
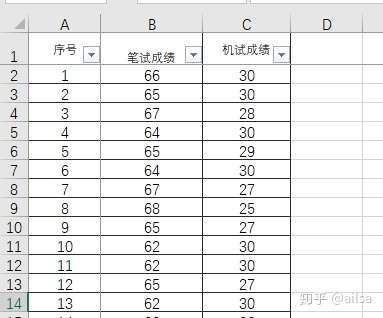
SPSS中:行:数字编号组成 列:变量名称
关系型数据库:mysql SQLserver
所以,基于二维表的操作,想必大家都不陌生了吧
那下面,我就说一说SPSS不同于其他软件的操作方式
SPSS中的数据由两部分组成,数据视图和变量视图,数据视图用来存储数据,类似于数据库中的表,变量视图用来定义变量的一些属性,类似于数据库中的表字段的设置
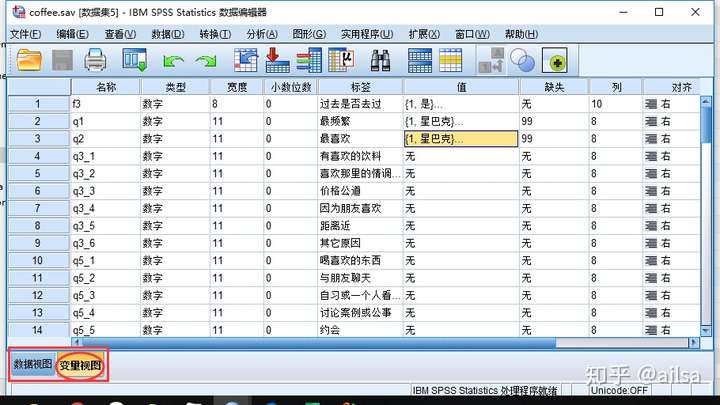
SPSS作为一个专业的统计分析软件,在处理调查数据的结果处理上是非常友好的
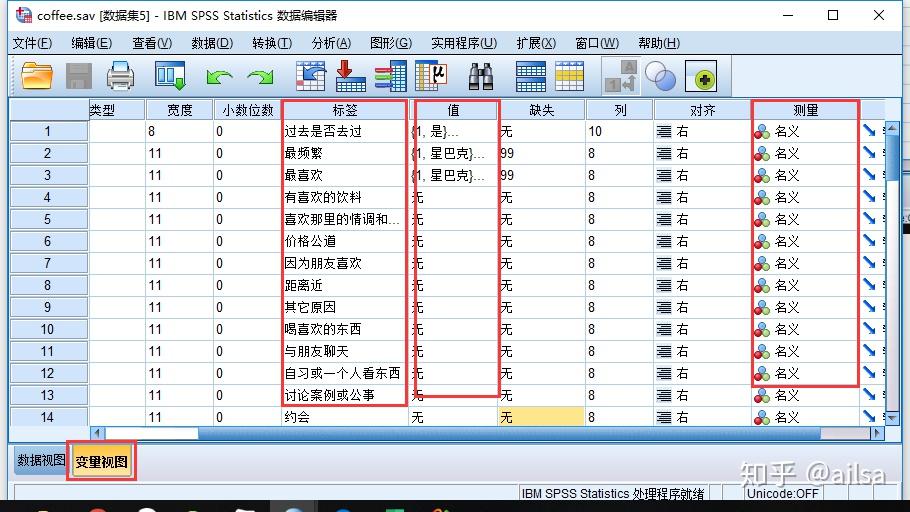
标签:用来解释这个变量存储的主要内容,类似于数据库中的注释
值:我们在进行数据处理的过程中,往往比较喜欢用数字,那对于文本型的内容,可用数字进行替换,值就是数字与文本的对应设置,例如:性别一列,0代表男,1代表女,那存储的时候就只存储0或1,而实际的值则是男或女,一般是针对分类标签而言。
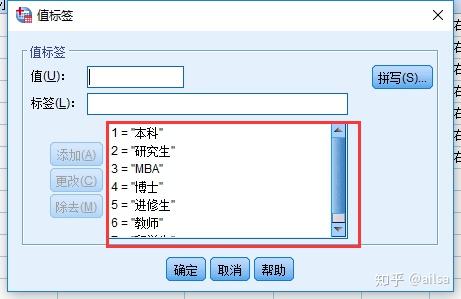
如何录入
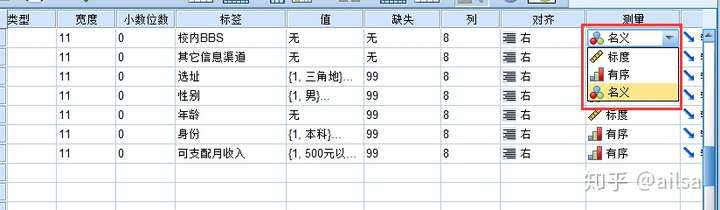
测量
讲到测量就不得不说一下,统计学上对于变量的测量尺度的分类了
测量尺度:指用怎样的精确程度来测量所感兴趣的指标
名义尺度:无序多分类,无大小,顺序之分,例如:性别,种族等
顺序尺度:有序分类,无大小,但有序,例如满意度,成绩等级,衣服的尺码等。
标度尺度:有大小,有顺序
定距变量:0是由意义的,温度
定比变量:0是无意义的,身高
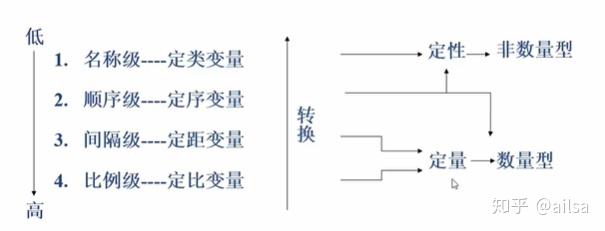
我们可以进行从高级别到低级别的类型转换,但是不建议从低到高
例如:可以把成绩0-100按照优良中差进行转化,但是要把优良中差强行按照某种规则转换成数字则存在很不准确的情况。
接下来看看在SPSS中的测量操作
名义:无序分类变量
有序:有序分类变量
标度:是连续型变量
测量 这个设置对分析起着非常大的作用,系统会根据你定义的类型不同,来默认显示不同的分维度
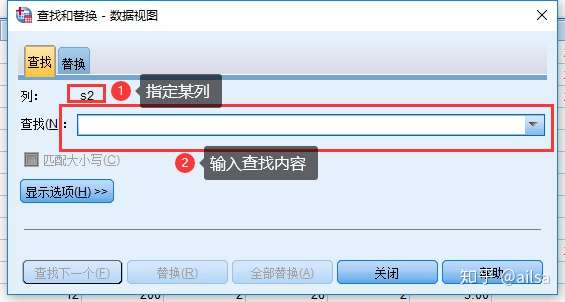
5.2查找与替换
跟Excel一样,Ctrl+ F查找,Ctrl+H 替换
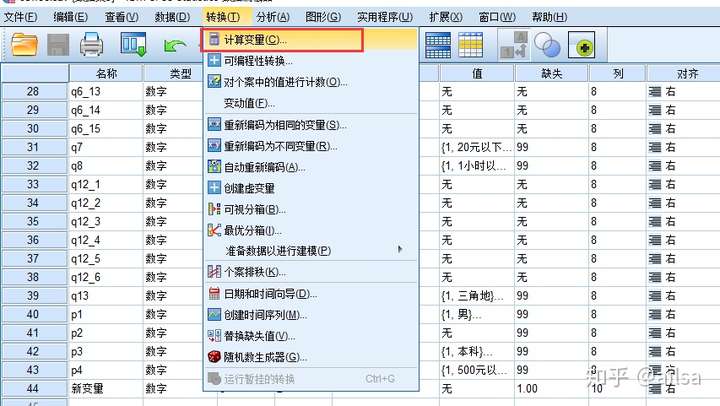
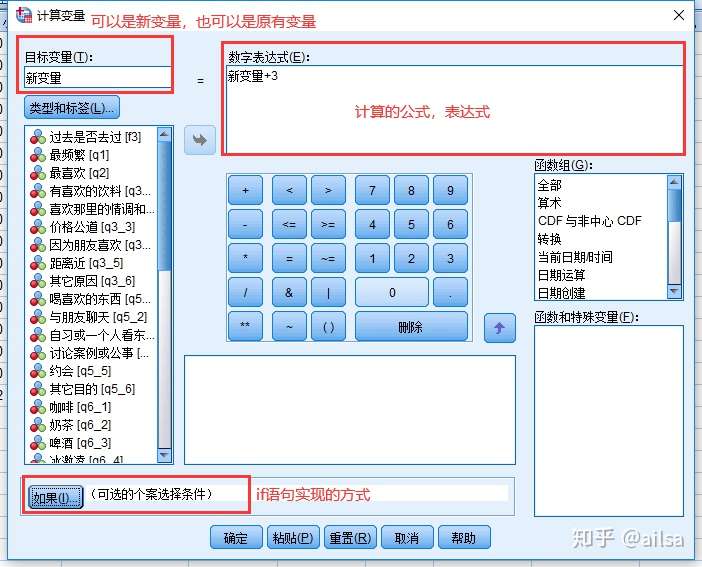
5.3 计算字段
可以实现基于之前的变量,经过计算,得出一个新的变量,也可以替换原有变量
5.4 排序
单个变量排序

多个变量的排序
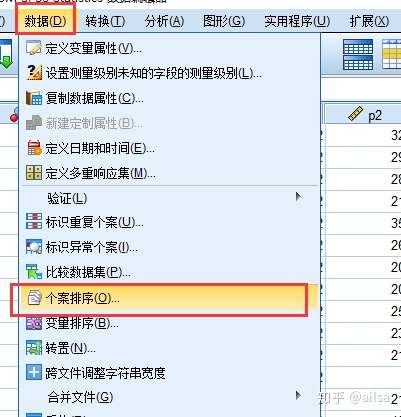
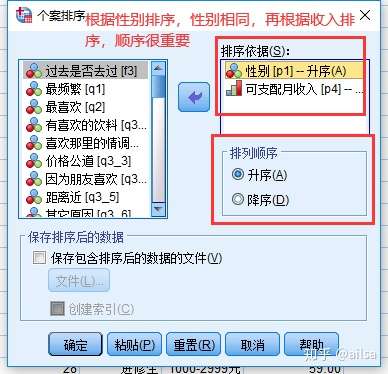
5.5 数据拆分
同一张表,有城市北京 上海 广州,则需要对每个城市做分析
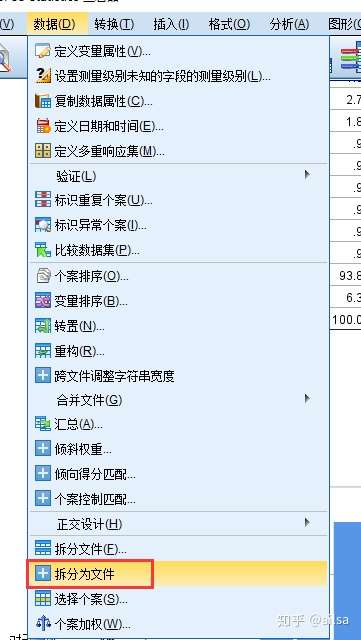
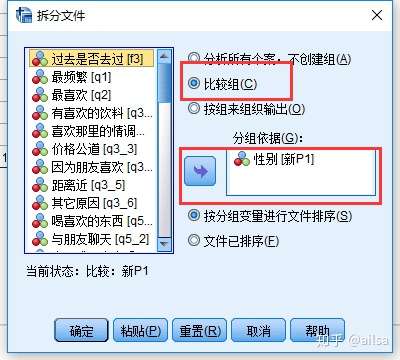
对年龄进行描述统计发现,按照分好的组进行分析的

使用完之后,如果不想对源数据进行修改,我们要重新进入,修改为原来状态
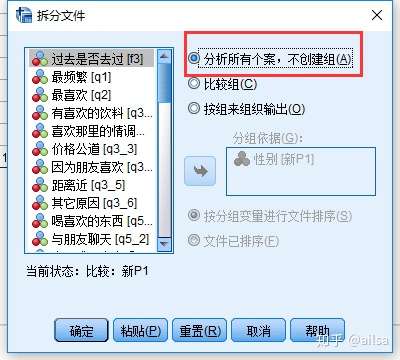
5.6 筛选
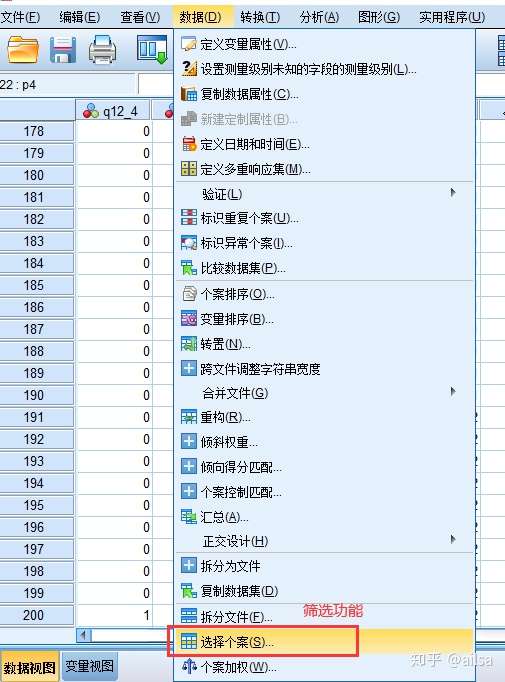
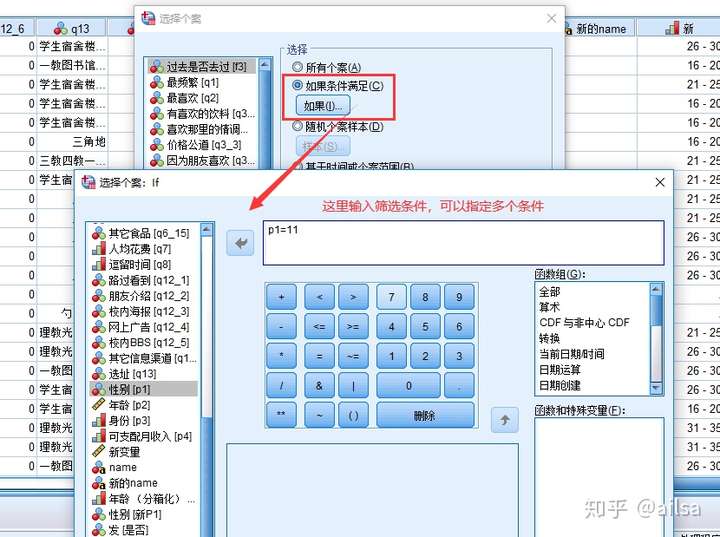
此时,我们看筛选结果
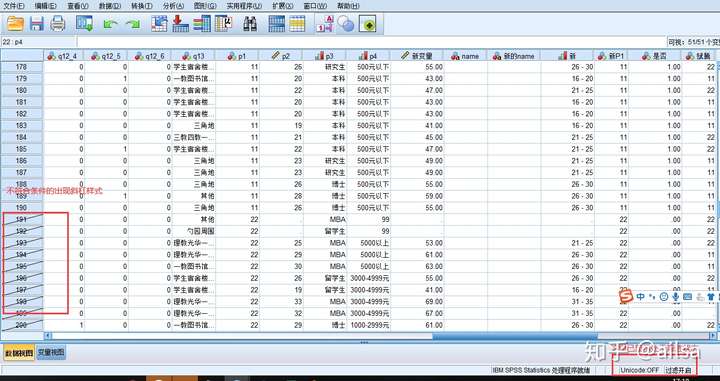
接下来做一个简单的分析
筛选后分析
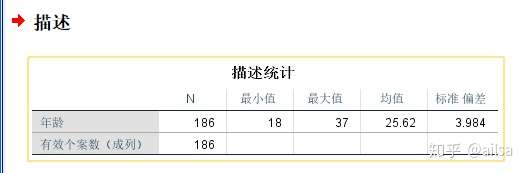
筛选前分析
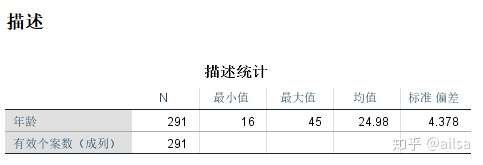
数据已经是根据筛选后做的了,因此,如果这时候保存,那原始数据就受到影响了,最好用完之后恢复到原来设置
6.数据管理
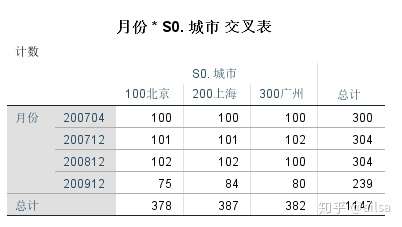
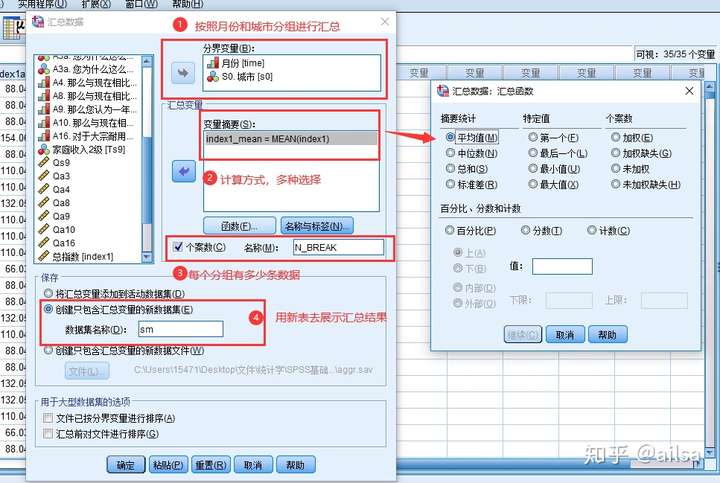
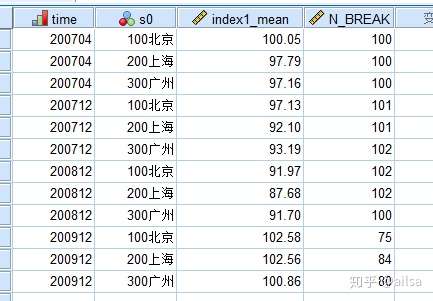
需求:求每个月每个城市的指数均值
6.1数据汇总
结果
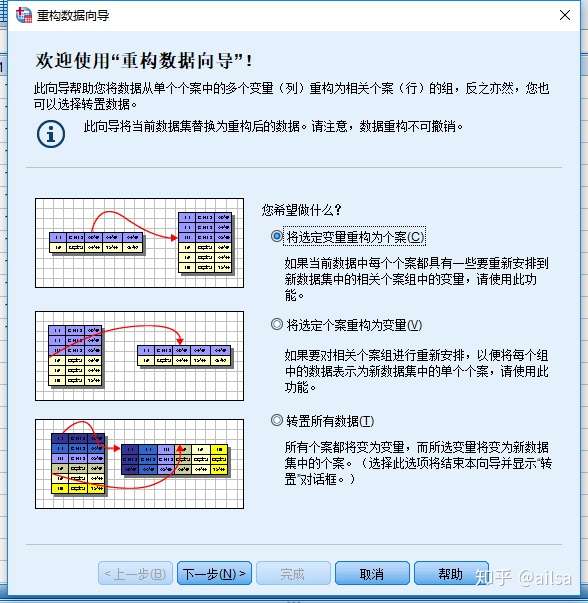
6.2 数据重组
我们标准的数据存储格式,应该是同一类型的数据放在同一列,但有时候并不是这样
例如:
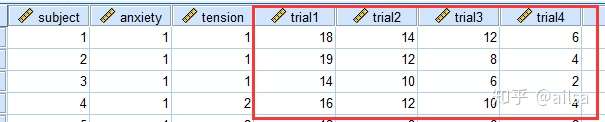
标准的格式
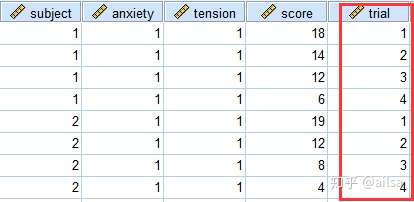
面对这种情况,我们该怎么办,难道要一个一个复制粘贴吗?
其实不用,SPSS有专门的功能来处理这种情况,而且可以相互转换
三种情况,一目了然
第一种情况:我们暂且叫宽型转长型
第二种情况:长型转款型
第三种情况:转置,行变列,列变行,这个就比较常见了
那拿第一种情况举例
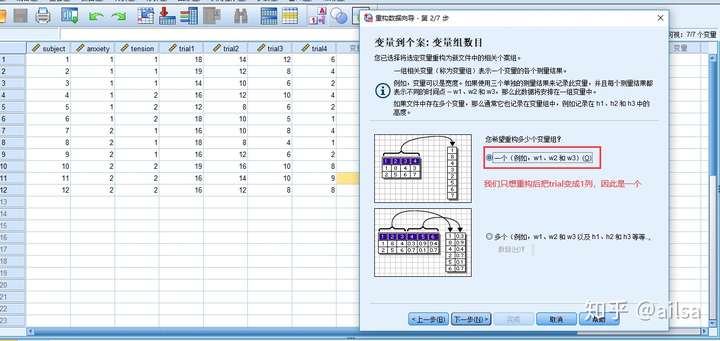
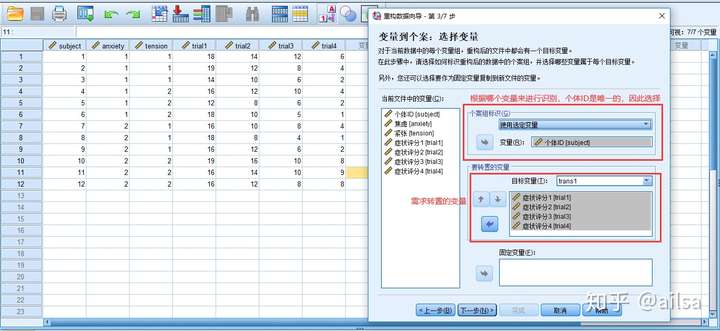
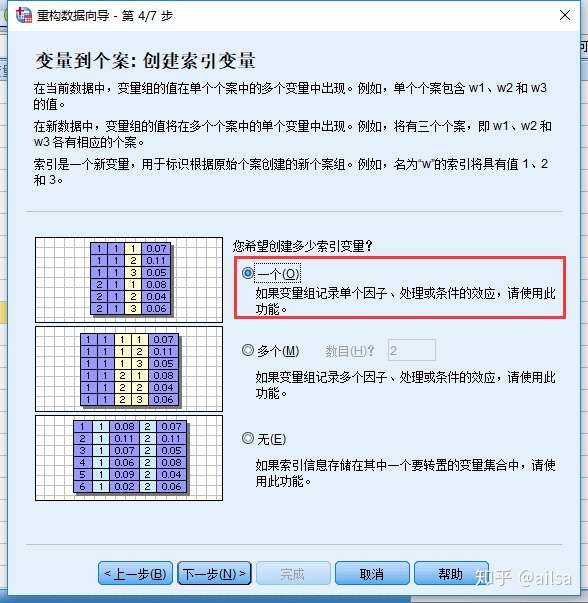
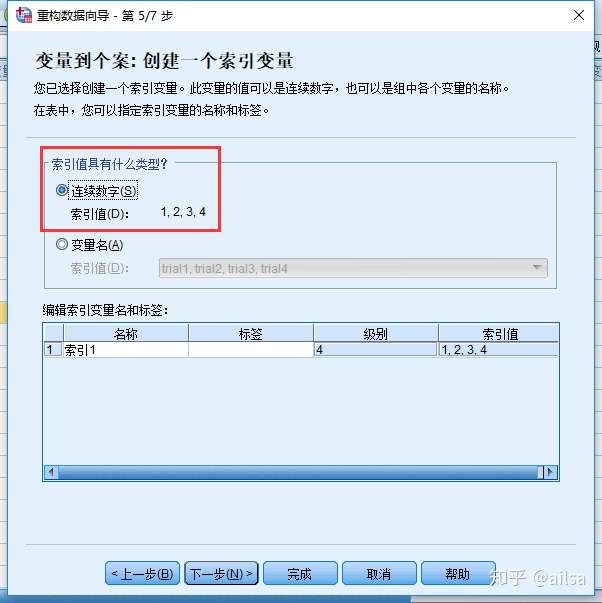
后面一步,默认即可
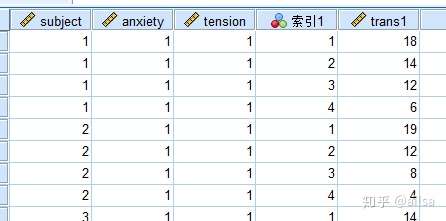
最终就可以实现了
长型转宽型
需要个别注意的是这一步
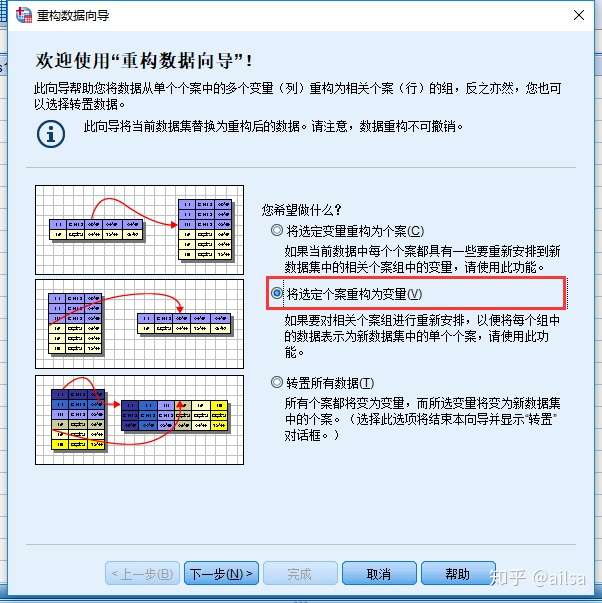
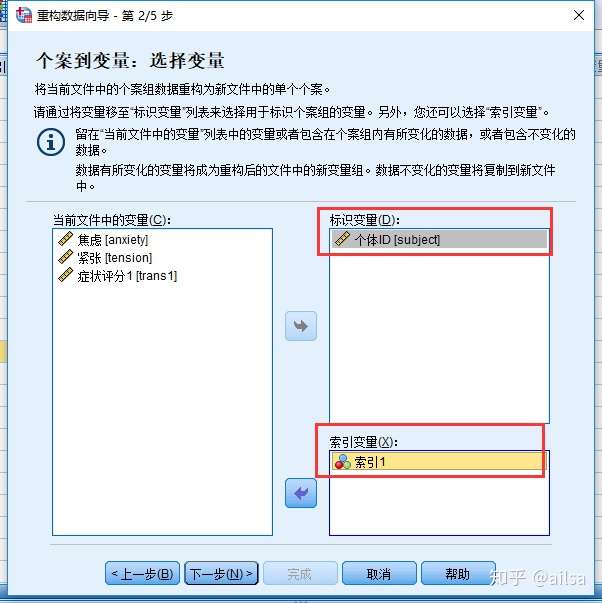
其他的按照默认的就可以了
结果展示
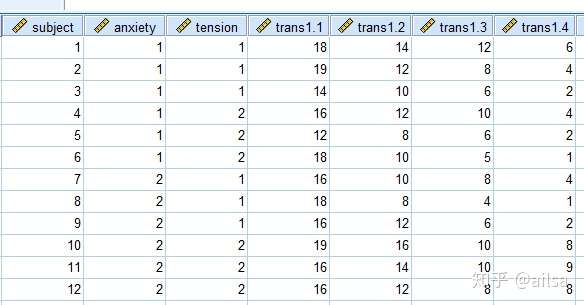
主要用于重复数据的记录
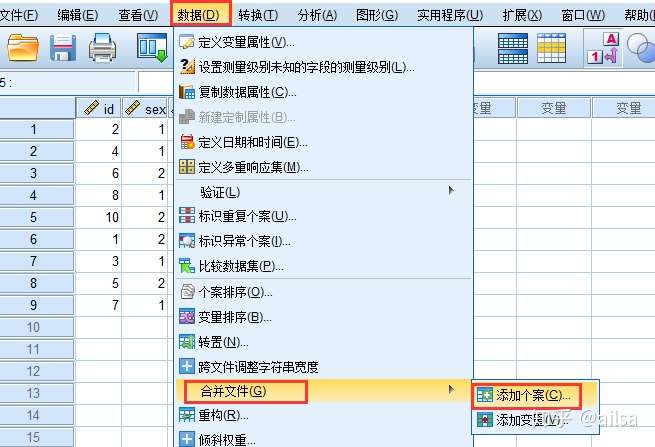
6.3 多个数据文件的合并
纵向合并
从外部文件中增加记录到当前文件中
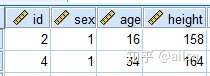
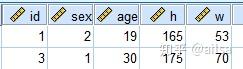
将a.sav与b.sav合并
a.sav表
b.sav表
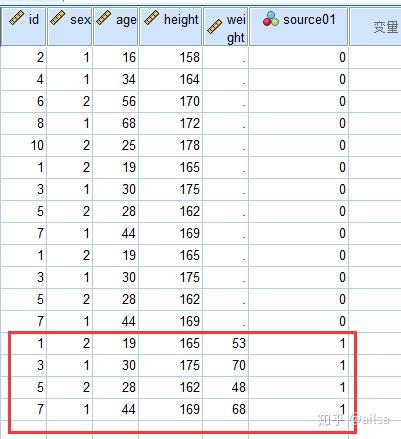
纵向合并,是把列相同的直接放在下面,列不同的需要手动设置

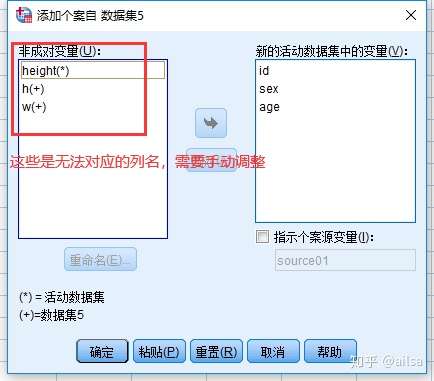
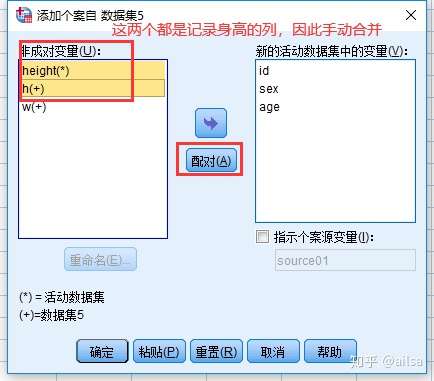
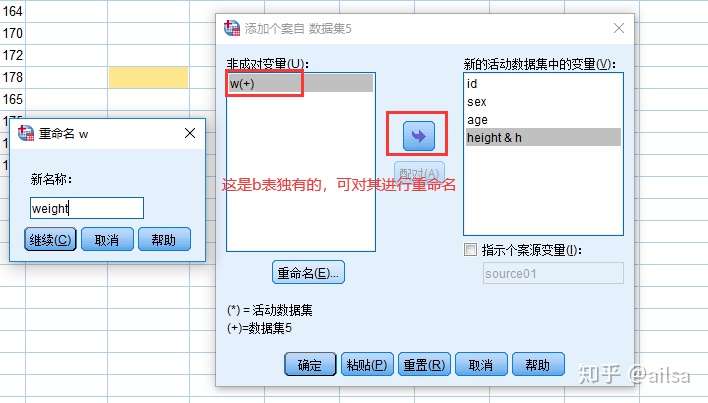
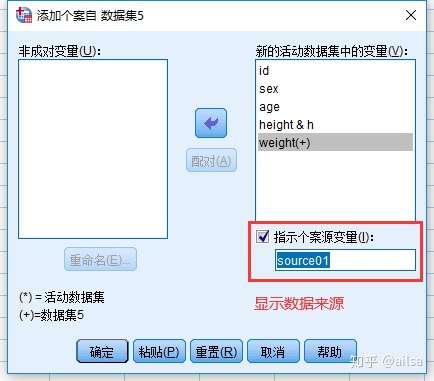
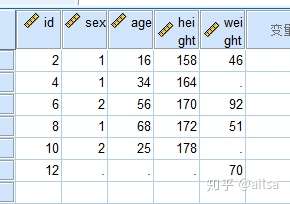
合并成功
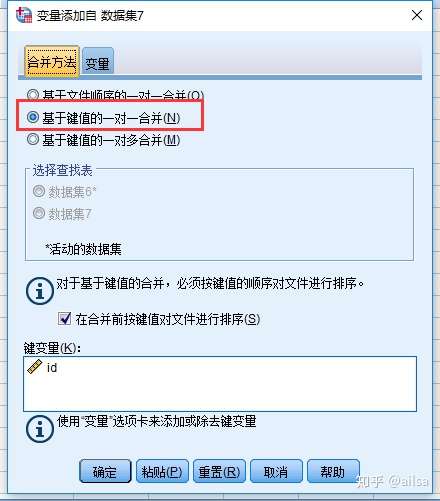
横向合并(连表操作,根据指定列进行合并)
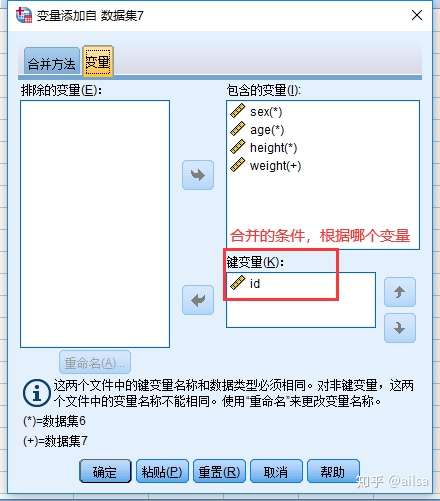
可以尝试一下,几种不同的合并方法,类似于sql中左连表,右连表
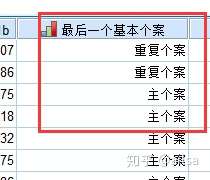
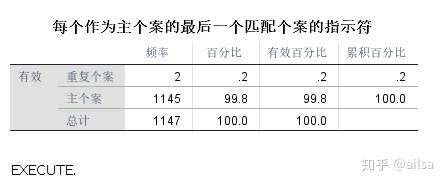
6.4 标识重复个案
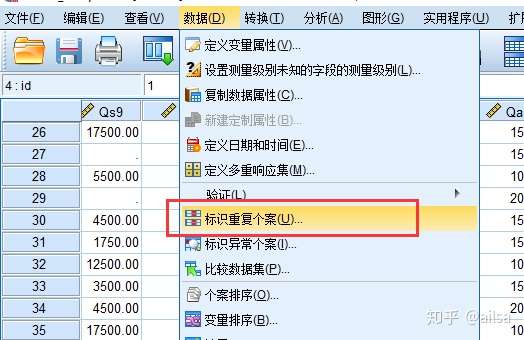

结果显示
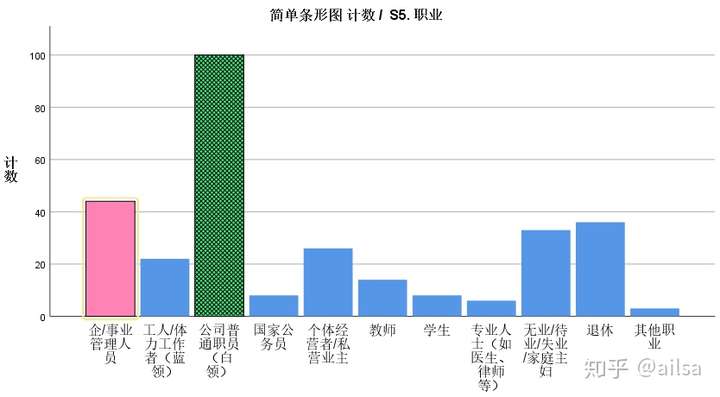
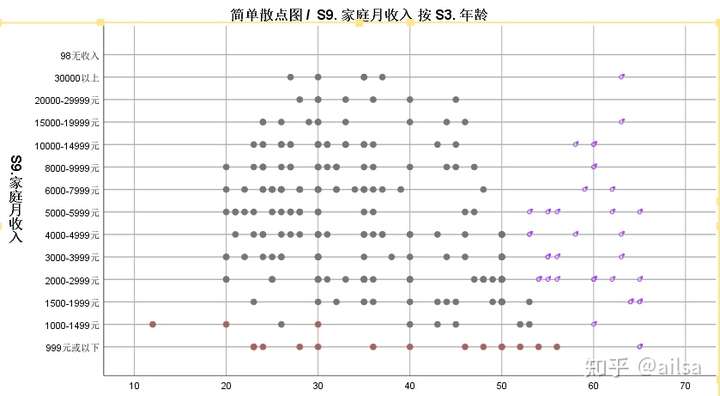
7.SPSS制作图表
最大优势:基于数据分析的需求来展开,灵活进行调整
图形的创建
- 可视化的图表构建器:主要操作方式
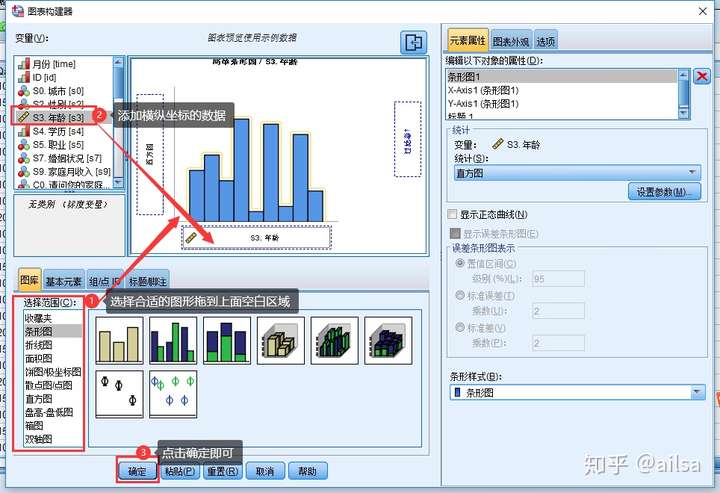
结果呈现
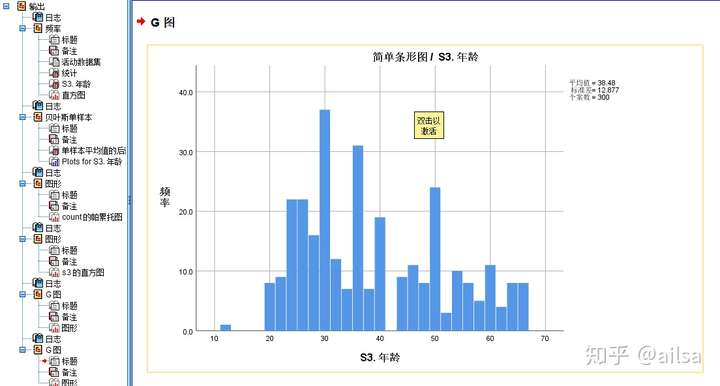
- 继承自老版本的传统对话框
- 方便老用户使用
- 注意有些特殊图形只能用该界面生成
详细介绍绘图对话框
巴拉巴拉巴拉
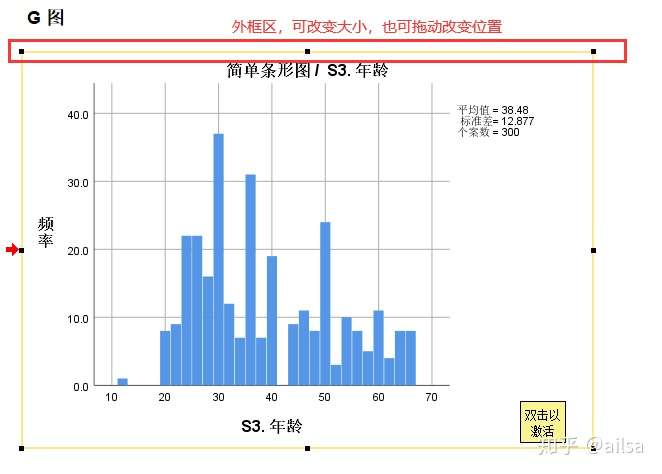
图形的编辑
选中控制框,可改变大小和位置
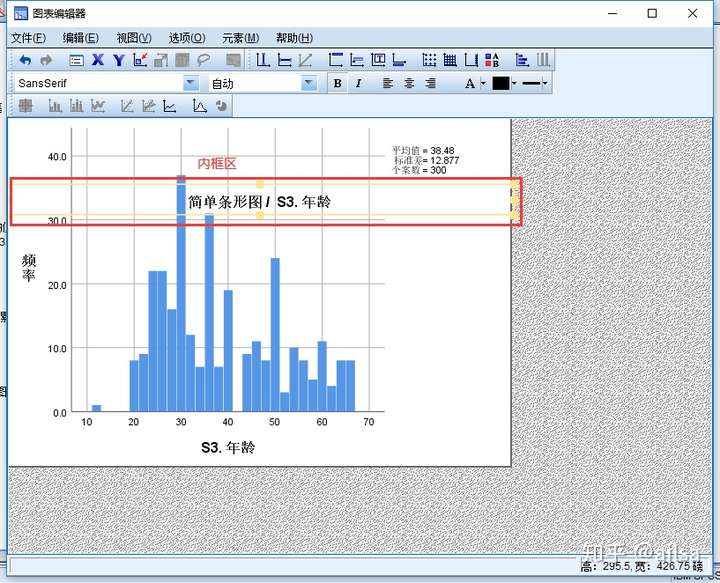
标准操作:
单击图形元素,选中所有同类元素
二次单击,则选中同组元素
三次单击,则只选中该图形元素
快捷方式
有图例时,单击图例则选中所有相应的图形元素
使用套索方式,一次选中多个对象
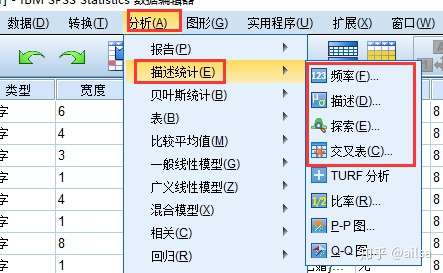
8.描述统计
对于描述统计,我们主要讲常用的四种操作
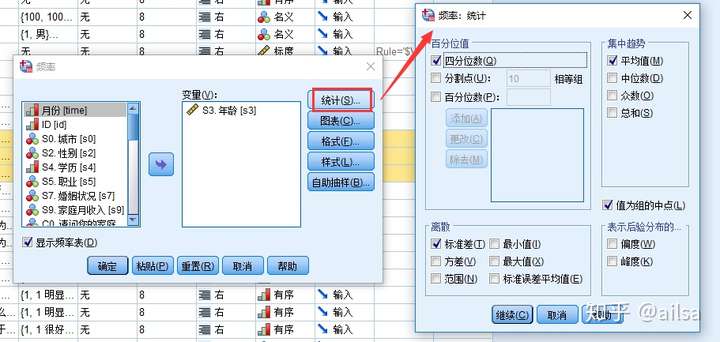
8.1频率
有比较全面的统计描述的内容,可根据频数进行相关的分析
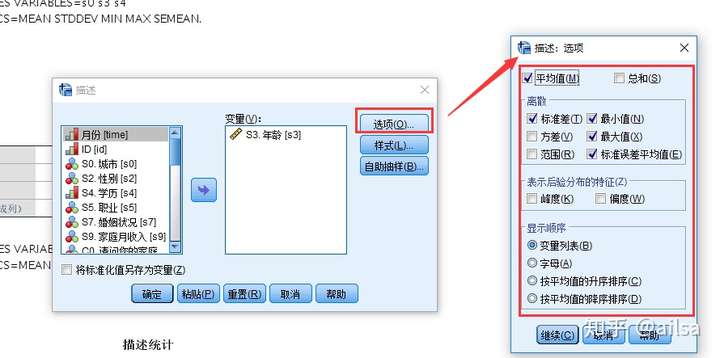
8.2描述
用于正态分布的连续型变量
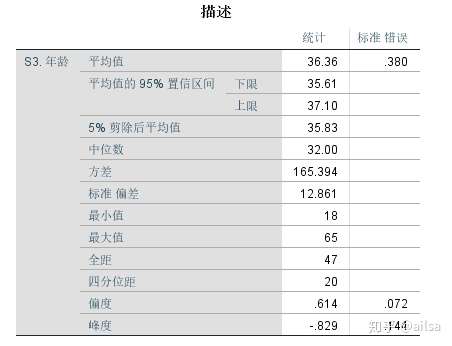
8.3探索
可对变量进行更为深入详尽的描述性分析,也是比较常用的
8.4交叉表