写在OO作业之前
在正式写oo作业之前,先说一些“废话”吧,就当是对oo的吐槽。
事实上,早在大一的时候,听说数分很难,然而事实证明数分并没有有让我通宵的体验。
在大二上的时候有一门课叫祭祖,号称是第一门给我们“推背感”的课。但是我也是很好的摸了过去,从P5才开始通宵。(虽然本菜鸡只是止步于P6而已)
早有耳闻北航的oo是一门非常“坑”的课程,开始我还不以为然。然而当第一周基本啥都没讲就给我们留了一个多项式相加的作业时,我才意识到事情并没有那么简单。
到第三周的ALS电梯已经是需要熬到1点钟,我一边血泪控诉oo(骂着我这个版本的eclipse不好用,控诉这门课的难度(心态崩了) )一边写代码debug。直到DDL前一天才解决了所有的bug,设计总算有了眉目。才仅仅经过三周,感觉像经历了什么大的挫折一样。(可能是因为我太菜了)
那么接下来我再来针对具体的三次作业来写写本菜鸡是如何在三次作业中survive下来的。
第一次作业:多项式加法
事先声明的是,在此之前我没有学习过面向对象的课程,包括暑期的面向对象先导课我也没有参加。(听说暑期的先导课效果很好,如果当时学习了估计这次作业不是很成问题)
甚至我连JAVA都没有学过,还好在寒假的时候听了同学的建议,在网上找了JAVA的学习视频学习了一段时间。至于学习效果如何,当然是不太好的。因为只是看视频,没有动手写代码,没有经过系统的训练。这样学习一门语言,往往只是掌握了基本的语法而已。对语言的运用则很成问题。虽然掌握的不好,但是不至于无法入门,总比零基础来编写要好。
因为对JAVA面向对象思想理解的不深,导致最后差点写成了个和C差不多,面向过程的代码。好在第一次作业比较和善之处,是PPT上给出了一个大体的框架。根据这个框架来补充代码,基本上算是勉强实现了面向对象。

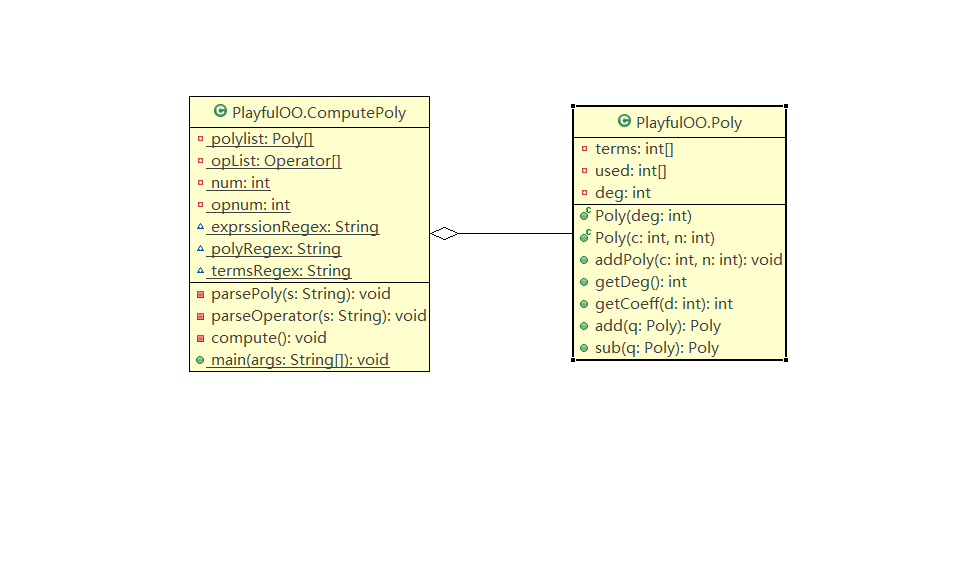
这里附上度量分析和类图
度量分析:
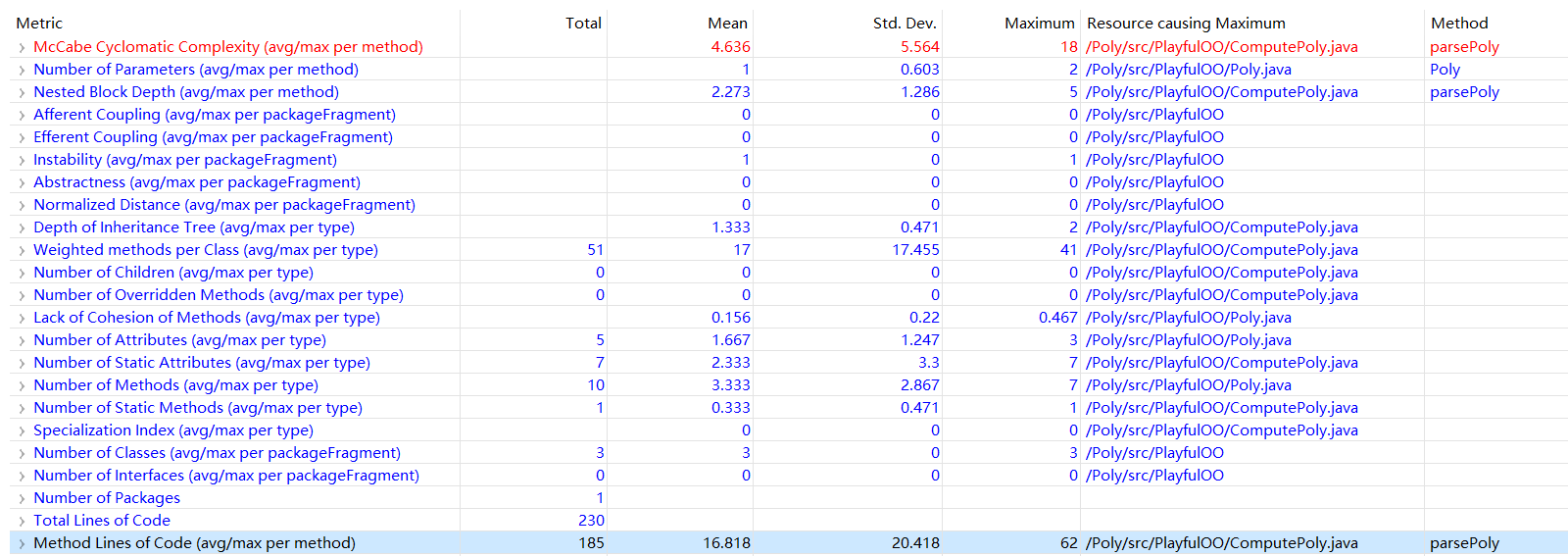
类图:
可以看出来飘红的点是圈复杂度,方法则是parsePoly,即将字符串分析出多项式的方法。这个方法圈复杂度高的原因恐怕是因为没有使用方便的工具matcher和parseInt来读取数字,而是使用了很麻烦的方法(即C语言的方法)来读取,导致这个方法需要的工作太多。
设计思路上完全与PPT上的框架一致,因此不在此赘述。总的来说,以前没有接触过面向对象,第一次作业能按照PPT的指导来写面向对象,可能算是一个优点吧。
代码反思:
(1)一开始在编写的时候,根据前辈的慕课教导,使用了正则表达式这一强大而可靠的工具,这点还是值得庆幸的。如果没有了解到这个工具,按照状态机来判断格式,洋洋洒洒能写出庞大的代码量。但是那样的代码,无论从可读性,可靠性,都不如利用正则表达式来的实在。而且用状态机来写,难免会出现考虑不周的情况,从而让人抓住马脚。
(2)早在寒假时就接触到了一句格言“不要重复造轮子”(Stop Trying to Reinvent the Wheel)可能辛辛苦苦码出来一堆东西,最后发现早有现成的工具让我来用了。比如这次作业中,读取数字这一部分,我采用了如下代码
if(buf[i] == '-') negative = -1; else { for(current=0;buf[i]>='0'&&buf[i]<='9';i++) { current = current*10+buf[i]-'0'; } } if(buf[i] == ',') { coeff = current * negative; negative = 1; }
用negative判断负号,用for循环读取数字,活脱脱的一个C语言读取数字的典范。(事实上我是先写的C程序,这段基本就是从C代码复制过来的)这样写,虽然没有问题,但是,一个字,蠢。在拿到第二份作业指导书的时候,要读取数字,我这时候才发觉用状态机判断的麻烦,开始另辟出路(面向百度),知道了用matcher来把字符串转为数字。后来发现这种方法的简单,强大,能轻松处理前导0和前导符号,比我用状态机高到不知道哪里去了。
这次作业之后,我才发现JAVA比C也是不知道高到哪里去了,各种内库函数,用起来都是十分方便。(之前专心致志造轮子的我真是滑稽)
BUG攻防:
虽然公测AK,但是在互测中,我的程序被找出来了bug。发现这个bug的时候我是痛心疾首,怎么有这么弱智的bug出现。
这个bug仅出现在最后的输出阶段。我在输出结果时,用一个for循环遍历到数组中最高指数的项,判断到系数不为0就输出。之前所有的项是输出 “(系数,指数),”,在指数最高的项输出“(系数,指数)”。这样有个明显的问题。如果指数最高项系数为0,那么最后一项输出会有一个该死的逗号“,”。出现这种bug,大概是因为线下自测时构造的测试样例太弱,以致于放过这种低级bug。
而下家的代码则是公测就出现了问题,互测时因为空多项式处理不当被我找到一个bug。老实说下家的dalao代码写的是比我好的,只不过处理的太多太麻烦而忽视了代码的正确性,而我只是保证了代码的正确性。
由于这次题目难度不是很大,所以我仅仅是按照测试树构造测试集来测试下家。没有发现其他错误就放弃了,改为查看下家代码,最后才发现的空多项式处理不当的bug。
第二次作业:傻瓜电梯
这次作业比第一次的难度增加,我觉得大致是因为下面两点:一是因为这次作业没有给出具体的框架,仅仅给出了五个类的设计建议。(我到现在还不知道楼层类有什么用)所以这才是真正考验我们面向对象能力的一次作业。二是指导书的加量不加价太过明显,看着指导书就有头疼的感觉,而且这次的内容也抽象的多。一般遇到这种抽象的题目什么的,我都会先去看样例,然而指导书的样例断绝了我的念头(你懂的)。万般无奈下我做出了一个现在看来十分正确和明智的决定:
花了一天来看指导书。不打开eclipse,就是看指导书。从头到尾,看的迷的地方就再看一遍。
这样做的好处是,我理解了“我要干什么”。
所以这次开始码之后,没有因为跟指导书不符而回过头大幅修改的情况。早在计组的经验中我们就已经得知,不要轻易开始敲代码,搞清楚设计之后再开始编码,效率能提升不少。
虽然理解了整体的设计需求,以及有了大体的框架,但是想填满这五个类还是不容易的。这时候我使用了计组的ALU策略(计组的时候要搭建CPU,开始不知道干什么,于是我从最简单的ALU写起,把所有的小部件写完之后,大体也就清晰了不少)。摸着石头过河,搞清楚电梯能干什么写出了电梯,按照这个思路把整个补充完了。
但是回过头来看,第二次作业还是有不足的地方,所以在第三次作业之前,我修改了第二次作业的设计。因为修改的地方不是很多,这个部分没有花多长时间,但是为第三次作业算是做了垫脚石。不然按照我原来的设计,第三次作业估计得写的麻烦死。修改部分如下:
(1)存储请求的队列,原本为Array数组结构,改为了ArrayList链表结构。这样无论是取出请求,删除请求,改变请求位置,都简单了不少。(第二次作业怎么没发现这个这么好用)
(2)第二次作业中,主方法完成了从读取,到扫描请求队列,到调度的所有功能。这种设计明显偏向面向过程,主方法完成了所有功能。于是我把它拆分为两个部分。一是读取输入,并把合法请求放入队列中;二是扫描队列并且调度。而且把判断同质请求单独放置了一个方法,这样就显得更加符合面向对象的思想。而且对第三次作业的继承,也能很好的符合需求。
这么看来,第二次作业的原始稿有些惨不忍睹,于是我在这放出修改版后的类图和分析。(有些不敢想象原始版本的度量分析是什么样的。不过现在也找不到那个版本了)
度量分析:
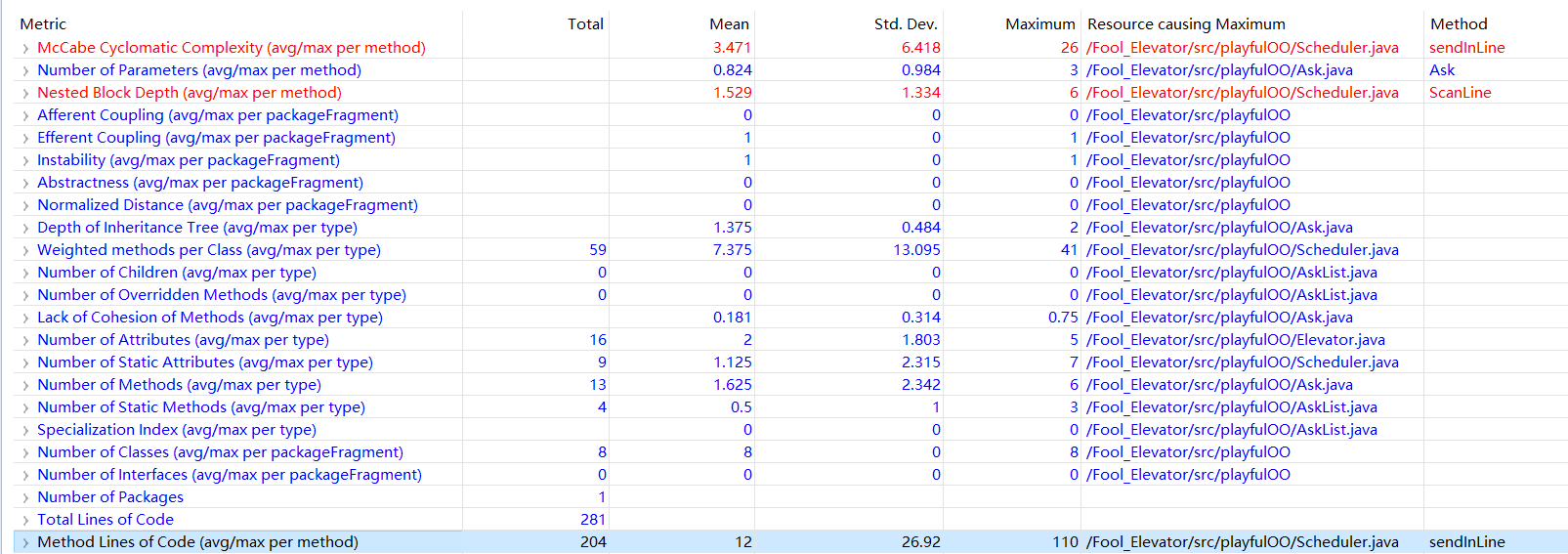
类图:
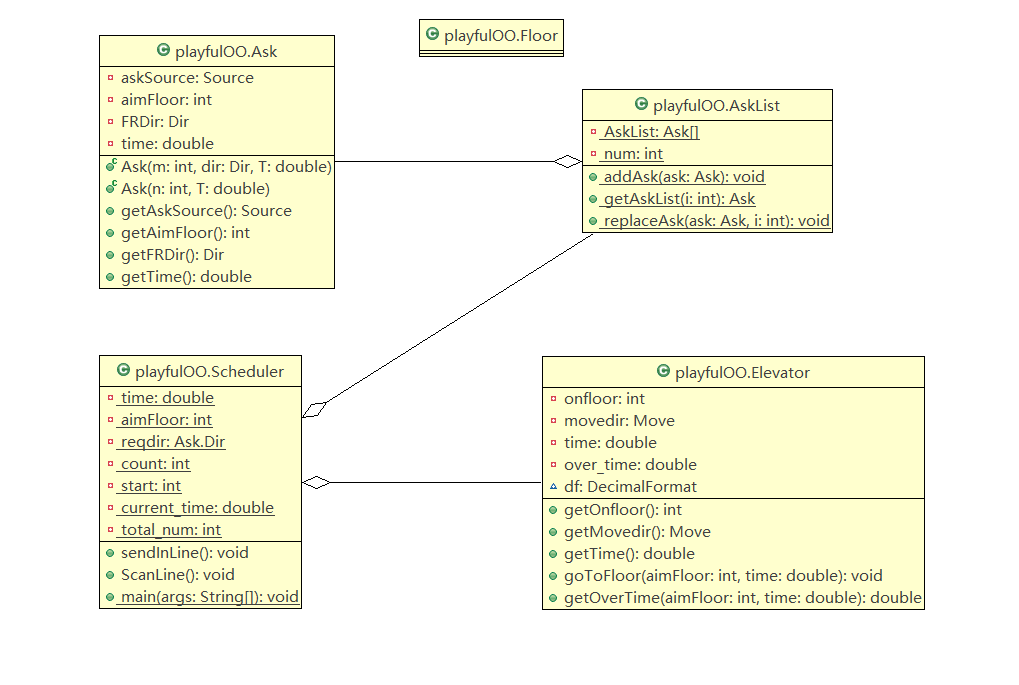
代码反思:
其实把原来的一个main函数解决到底,改装成便于第三次作业设计要求的电梯没花多长时间。但是原来那种设计方式质量还是惨不忍睹的,而我又没有优化,把优化时间放在了第三次作业的时候。还是来看看优化之后的代码吧。
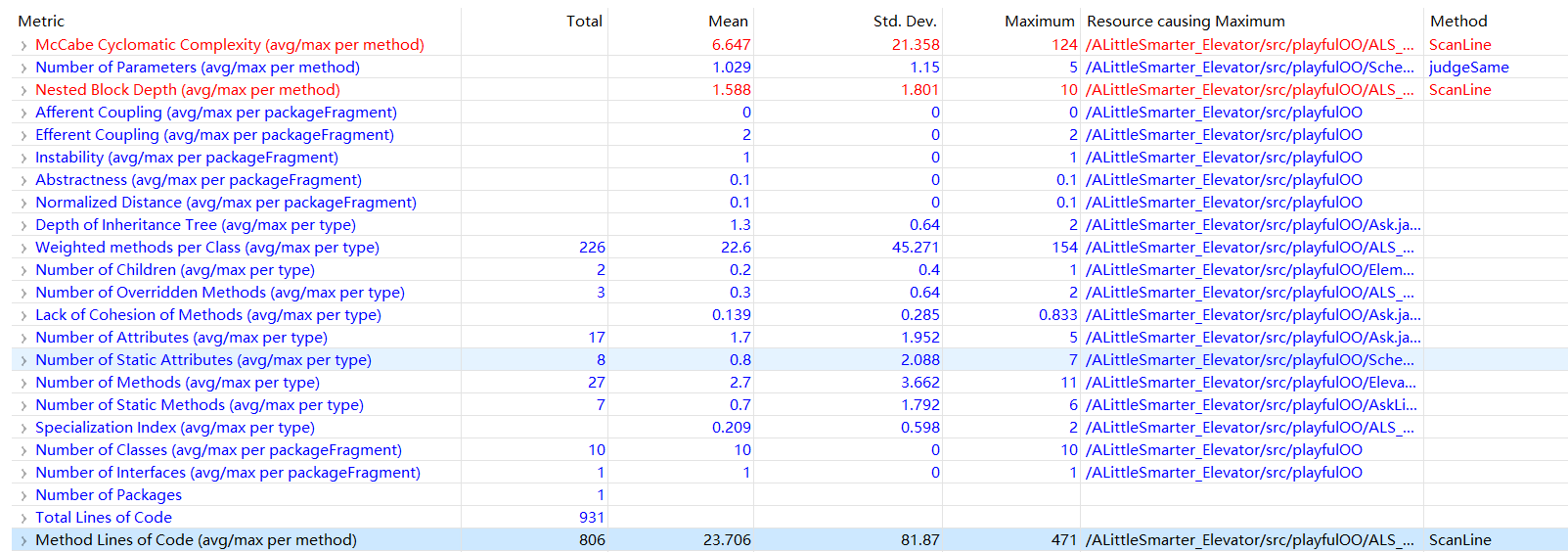
对标红的McCabe Cyclomatic Complexity和Nested Block Depth进行分析。
McCabe Cyclomatic Complexity:圈复杂度。圈复杂度过高的原因是因为scheduler类承担了太多职能,既要判断输入,把合法输入塞到请求队列中,又要扫描队列,调度电梯。还有去除同质请求之类的,这么看来圈复杂度超限好像还挺正常的。这样的缺点是代码不好维护可读性差,好在这次debug没花多长时间。
Nested Block Depth:嵌套块深度。嵌套块深度表示if,for循环嵌套的个数。这个大抵是因为去除同质请求,每次拿出来主请求之后,要遍历之后的队列,这里就用到了两个for了。而且每次判断还有if-else块,所以导致了嵌套块深度过高。(我不想说之前用array的版本估计更高。因为每次去掉一个同质请求的时候,只能用for for来把之后的请求往前挪一位来去除同质请求。还好改成arraylist了不然怕是药丸)
总的来说,这次代码写完之后基本上没出什么bug,再用try-catch来防御代码,就自以为大功告成了。然而写出来的代码质量确是很低的,也是典型的只为了正确性抛开了优化设计的典型。事实证明,代码写完之后完全可以有时间回顾一下写完的代码,想想哪里可以优化,为下一次作业做好铺垫。
BUG攻防:
公测依然AK,因为这次傻瓜电梯从调度上没有什么多的要求,仅仅是判断完同质请求就搞定了。
然而我还是太天真了。在bug树上看到自己的bug时,有一种自己被暗算,被偷袭了的感觉。
这次被爆的bug是因为制表符TAB不算空格,而我会把”\s+"(即所有空白字符)转为“”(过滤空格),于是就被爆了一个bug。
测试者把我这个bug报了还在笑,我是笑不出来,眼泪往肚子里咽。(感觉这门课还能锻炼心态)
我下家写的代码就弱了很多,他第一条专门有判断是否时间为0,但是如果非法输入,会少输出一行ERROR,于是公测挂了一堆。我也是从这里找到了他的bug,至于功能性和同质测试完成的还是不错的,因为确实不难。
测试策略还是沿着树测下来,傻瓜电梯没有捎带,构建再强大的测试用例也并没有什么用。
这次bug攻防中我知道了原来这游戏还有这种玩法?真实面向readme找bug?所以之后写readme的时候,一定要小心细致,把所有可能被图谋不轨的测试者发现的细节问题都考虑到,不在这种莫名其妙的地方被爆bug。不过之后的作业也是越来越难,如果还是在这种地方找bug,那么我也是 。
。
第三次作业:ALS可捎带电梯
这次ALS电梯,写代码debug到了一点钟,星期二晚上才解决所有bug弄出来最终版,设计也算是有了眉目,可以说是十分辛酸了。
说一下这次电梯作业的时间分布吧。
1.还是看指导书,依然花了不少时间。最重要的是弄清楚“什么是捎带”,什么情况需要捎带。
2.修改第二次写的代码,这部分真的很有必要。(如果继承第二次的原版本估计药丸)
3.写ALS调度
耗时最长的当然是第三部分写ALS,然而前两部分的时间同样很重要。修改了第二次作业之后,如何继承就更加清晰,写起代码也就仅仅需要修改调度部分了。然而这个部分则是花了不少精力与时间,包括构思如何处理捎带,以及在实现过程中的debug过程。因为构思的一些问题,中间我还回头修改了一点地方,好在修改的地方不多。
debug途中最难受的地方就是eclips给我带来的错误,我用下面的式子来计算目标楼层。
elv.getOnfloor() + (next_time - get_overtime) * 2;
但是很明显需要把double类型转为int类型,于是我用eclipse的快捷修改,变成了这样。
elv.getOnfloor() + (int) (next_time - get_overtime) * 2;
乍一看没有错误,结果有一段调试一直过不去,找了半天才发现是int强转的范围出错,应该是这样。
elv.getOnfloor() + (int) ((next_time - get_overtime) * 2);
像此类的debug过程还有,比如方法名叫sendInLine,调用时变成了sendinLine,等等。可见编码时的规范性和细节都十分重要。好在大的设计方向没错,最终功能性还是很好的完成了,大概是把请求分了几类:
1.主请求,即当前请求
2.副请求,即主请求过程中,能够完成的捎带请求
3.未完成的捎带请求(我起名为undo),即完不成的捎带请求
总之按照这个思路写,基本也是按照指导书的要求实现了捎带。
接下来从度量分析和类图来反思代码质量:
度量分析:
类图:
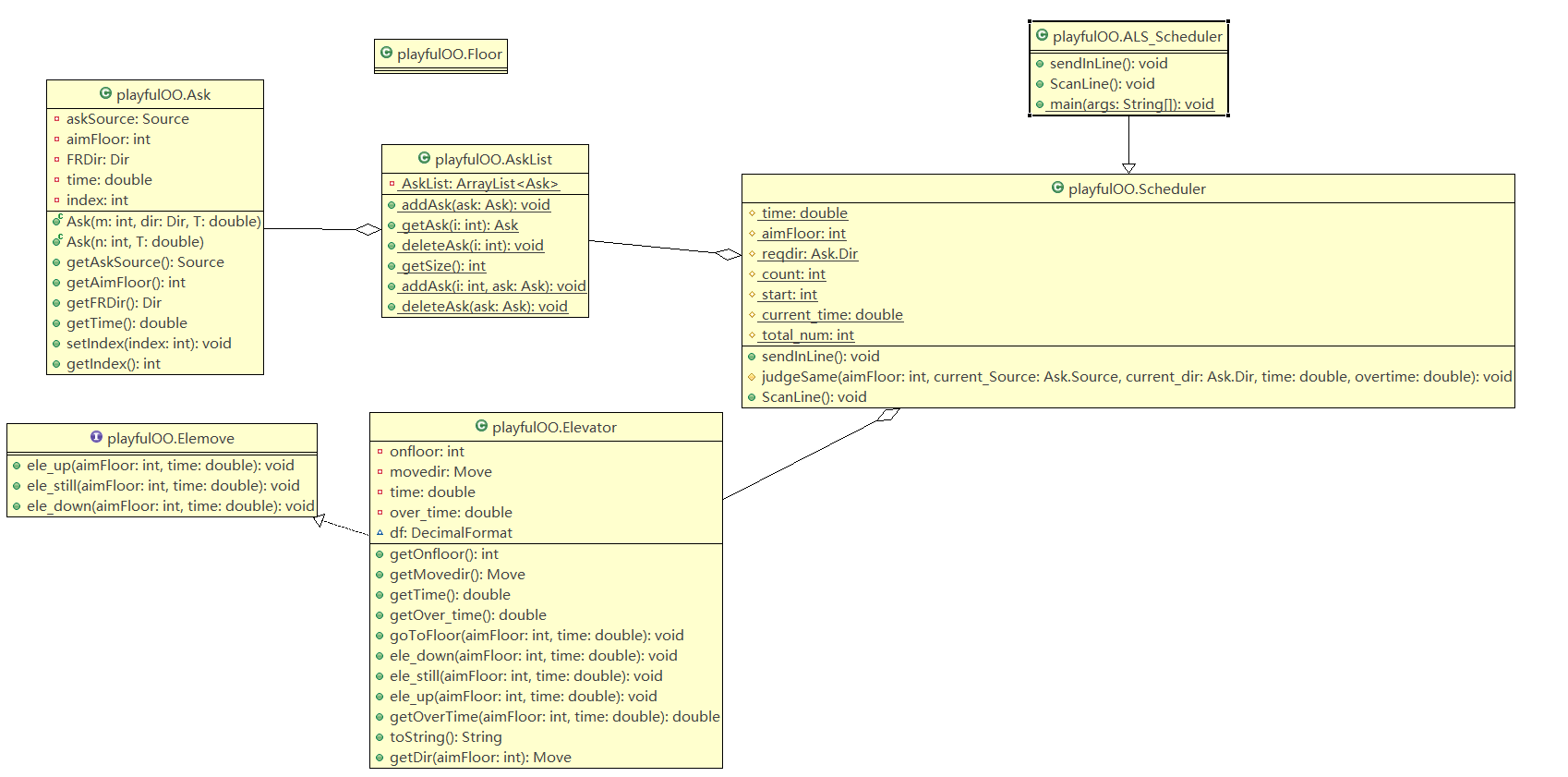
代码反思:
仍然是圈复杂度和嵌套块深度,这次由于功能设计,用了更多for,更多if。问题也很明显,很不直观,所以注释也是成吨成吨的加。
另外一个有意思的点是圈复杂度最后的方法,第二次是sendInLine,读取请求,这里是因为需要判断很多不合法情况所以圈复杂度高。这一次变成了ScanLine,扫描队列,也就是ALS的核心部分。这部分要实现捎带,确实有很多需要添加的部分。
其实当时为了忙着debug实现功能也是写的焦头烂额,完全没有考虑太多优化部分,想着写完了就行。回过头来看这次代码,写的是真的差。冗长,繁复。如果不是注释多我可能之后都不会看懂。只不过有了度量分析之后,能够看得更明白一点。显著的问题:
1.方法太少,一个方法恨不得能承担所有职能。好在判断同质我单独写了一个方法。
2.重复冗长。记得寒假在网上找资料学java的时候听到的一个准则,do not repeat yourself。看下这个代码完全就是在repeat myself。包括遍历找请求的部分,我可能复制了几遍。虽然复制也就ctrl + c ,ctrl + v,但是代码质量也下滑了不少。多写方法,完全可以减少代码量的。
这次代码是我写的最不满意的一次,之后的代码可能要吸取这次的教训,多写方法,少repeat。
BUG攻防:
这一次因为难度大了,自己测试的时间也多了,好在有较强的测试数据帮助我找到了自己的bug,顺利的de完。
这一次的测试策略大概是构造一个包含所有情况的大样例,然后一次性测试最终结果。如果不同的话再从中找出来错误之处(我和舍友都是这样找到了自己的bug)。把功能性测试完,细节都注意到之后才算自己的debug工作完成。
这次公测仍然AK,互测并没有被找到bug。虽然代码写的不好,但是所幸没有bug,这也得益于我以正确度至上的策略。
测试下家的功能性测试跟自己的策略一样,他也很好的完成了,可见也是下了功夫的。之后再看代码,找出了正则表达式的bug。
三次测试,下家功能性完成的都很不错,但是在一些细节会有些问题。比如正则表达式,这部分可以在线下测试时多下点功夫,在这方面出错还是挺恼火的。
心得体会:
大概是一个菜鸡的一点感受:
1.不要拖延。OO给的时间比计组还紧,越早开始越有充裕的时间来应付可能出现的bug或者意外情况。我比较喜欢预留一天的缓冲时间,星期三提交星期二就要写完,这样星期三就能有测试时间和debug时间,不会出现拖到DDL之后的情况。
2.多用好的工具。菜就要多学习,就拿表达式合法判断来说,正则表达式就是比状态机强大;同样请求队列ArrayList就是比Array方便。这些东西在网上找一找资料,绝对比闭门造轮子要好。用工具来写,代码的质量和可读性都高于不用工具。
要知道,没有什么是度娘不能告诉你的。如果有,那就谷歌。
3.花时间在读指导书和构造设计是十分值得的,直接上来就写代码,可能会出现一个bug改完,又有新的bug出现的问题。读懂指导书,想好设计思路,绝对不会吃亏的。
4.多学习别人的代码。尤其是如果抽到了dalao的代码,可以好好的膜了。写的好的地方也是可以借鉴的。(直接抄代码肯定是不行的)
5.我的策略是以正确性为首,不被找出bug为主要目的。其实一个代码写完之后,完全是有时间可以反思一下自己代码的质量。哪里可以优化,哪里重复了,用一部分时间在这上面还是能收获不少的。
6.关于互评这点还是小小吐槽一下吧,毕竟被扣了奇怪的点,难免还是有点不爽的。这个故事告诉我们,readme一定要写的详细完备,哪怕没多大问题,如果被有心人找出来扣了分就不好了。毕竟防火防盗防同学。我的策略是更偏向于花时间测试完善自己的代码,因此时间也更侧重于测试自己的代码而不是测试别人的代码。
不管怎样我觉得面向readme编程,从readme里面抠错误玩文字游戏的,是有违OO互测机制的初衷的。之后的作业难度越来越高,希望这样的情况能发生的更少一点。
虽然这三个星期,写oo作业还是非常辛苦,但是收获还是不少,比如学到了面向对象的思想,比如获得了充实的感觉,感觉没有虚度光阴。
至此OO的第一阶段也算是顺利通过了,如果拿游戏打比方,那么现在也才是刚刚通过新手村,前往冒险旅途的开始而已,下面的挑战难度将会更大。
希望自己能够坚持下来,将后面的每一次作业做好。多学,多写,多想。也希望大家能齐心协力,携手通关。
毕竟去补给站这事,大家都不想的对吧。


如果有什么写的不好的地方欢迎大家指出。