一.先知道 sharding-jdbc 是个什么 可以再官网看一下: https://shardingsphere.apache.org/index_zh.html
二.引入maven 依赖, 注意每个版本的配置不一样,我这里是4.X 其他版本的配置可以去官网查看
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>sharding-jdbc-spring-boot-starter</artifactId>
<version>4.1.1</version>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid</artifactId>
<version>1.2.3</version>
</dependency>
三. 如果出现 sqlTemplate 等异常 说明项目里面引入了 druid-spring-boot-starter 依赖 和 原生的 druid 冲突了 这里需要使用原生的或者可以把 依赖换成这个
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>sharding-jdbc-spring-boot-starter</artifactId>
<version>4.0.0-RC1</version>
</dependency>
四. yml 配置 分表配置,这里只是简单的分表
spring:
shardingsphere:
datasource:
names: ds01
ds01: # 数据源
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.jdbc.Driver
url: jdbc:mysql://192.168.254.106:5166/evaluate_center?useUnicode=true&characterEncoding=utf-8&useSSL=false
username: admin
password: admindgg
sharding:
tables: # 分表配置
test:
actualDataNodes: ds01.test${0..1}
# 分片键(分表字段)这里通过id 分表,具体字段可以自己定义,分表规则
table-strategy:
inline:
shardingColumn: id
algorithm-expression: test${id % 2}
keyGenerator:
type: SNOWFLAKE
column: id
props:
sql:
# 打印SQL
show: true
五. 创建数据库表 test0, test1

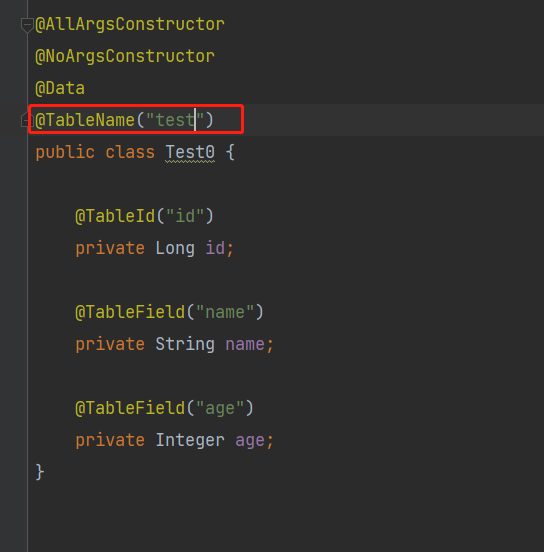
六. 然后创建对应的实体,注意这里的@TableName表名不要给后缀比如test0,test1,直接写test,不然只会插入指定的表
七. 创建对应的controller,service,mapper,这里就不赘述这个了
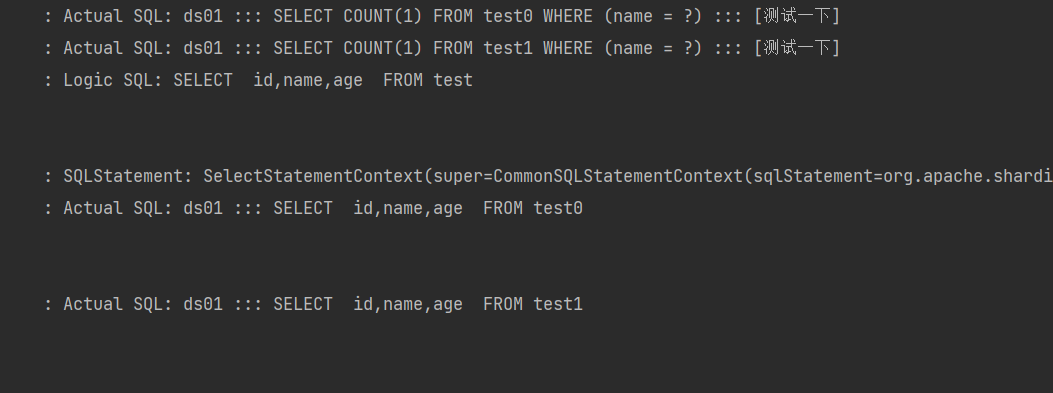
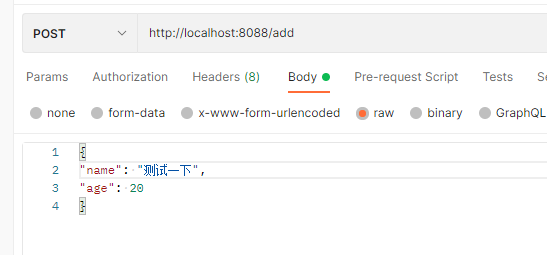
八. 调用测试,调用添加接口可以看到数据插入执行的sql,并且查看数据库都有数据,可以看出id 为偶数的在test0,id 为奇数的在test1
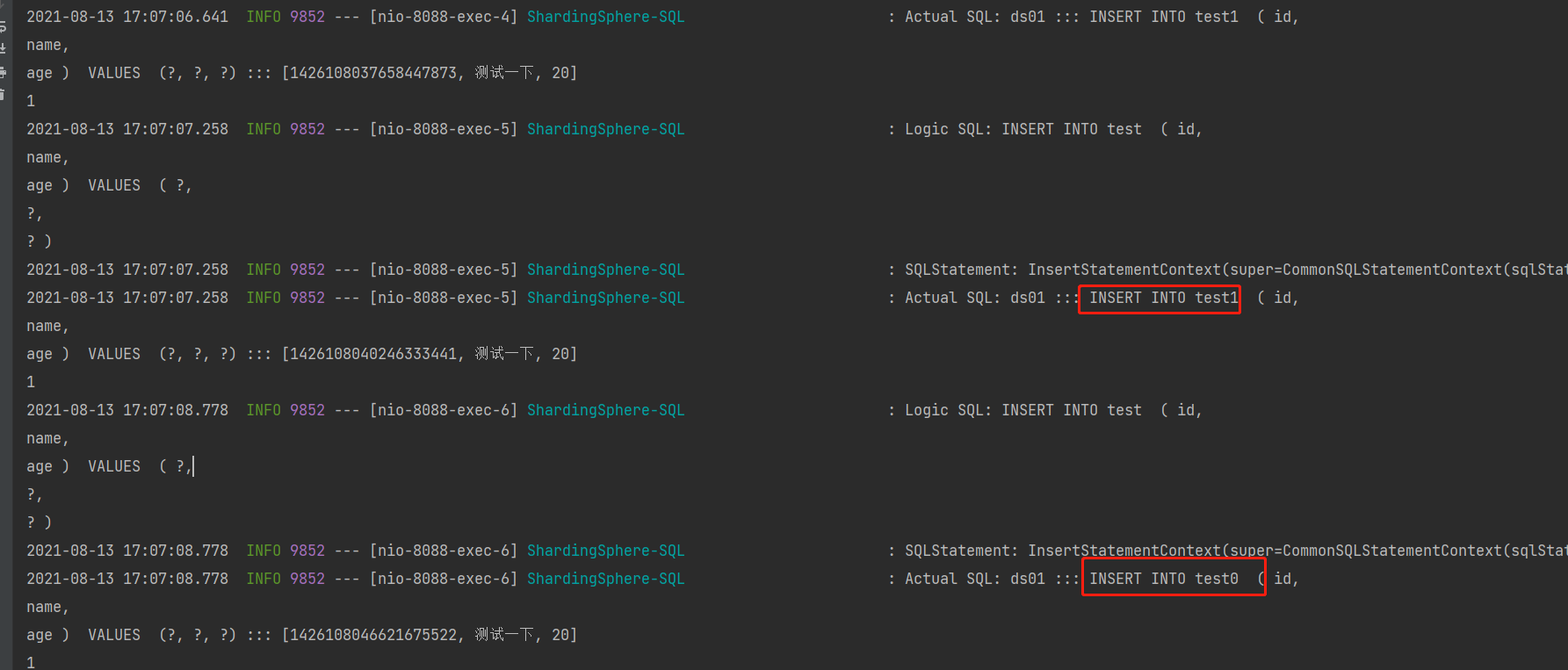
test0
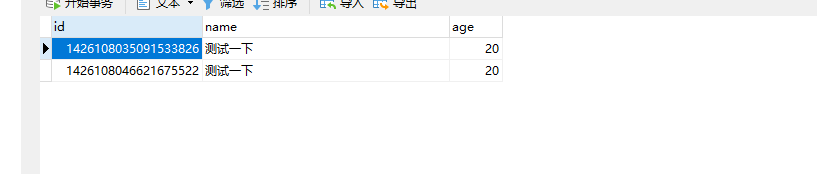
test1
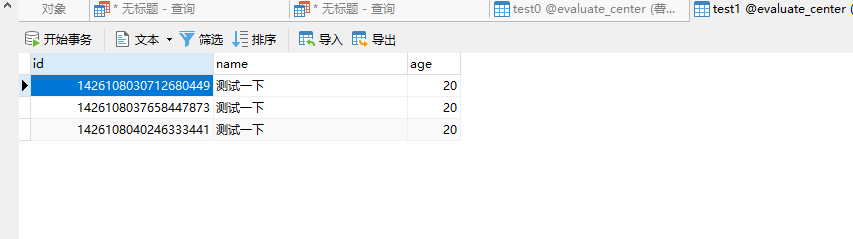
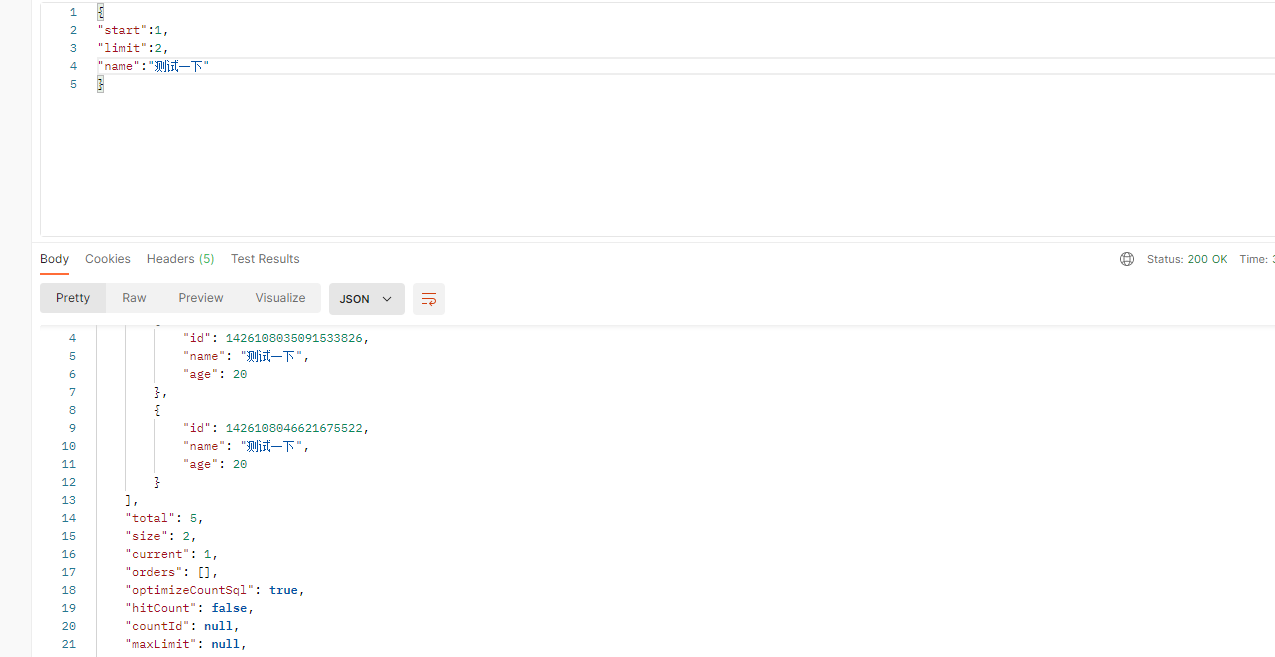
九. 测试查询: 通过分表id 查询,和某个字段分页查询
通过id 查询


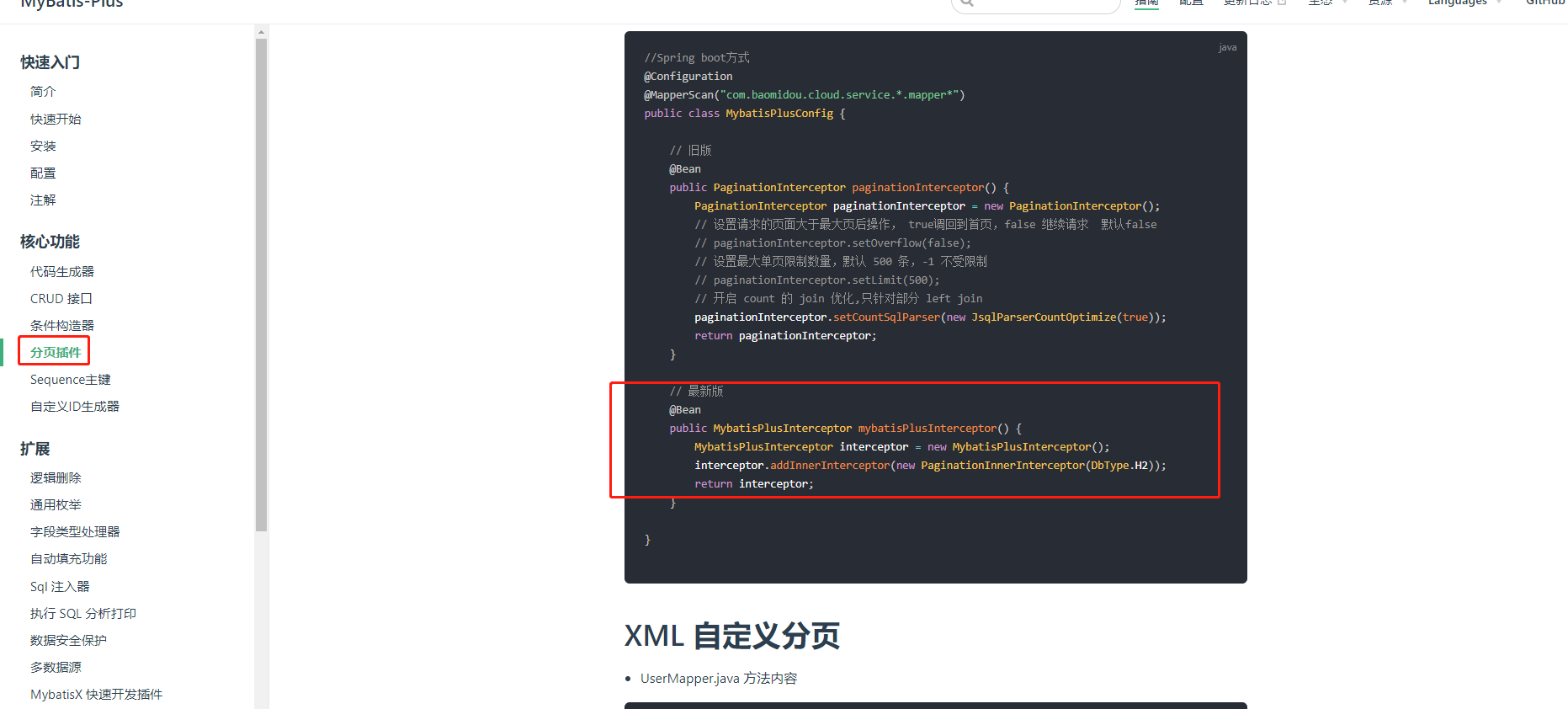
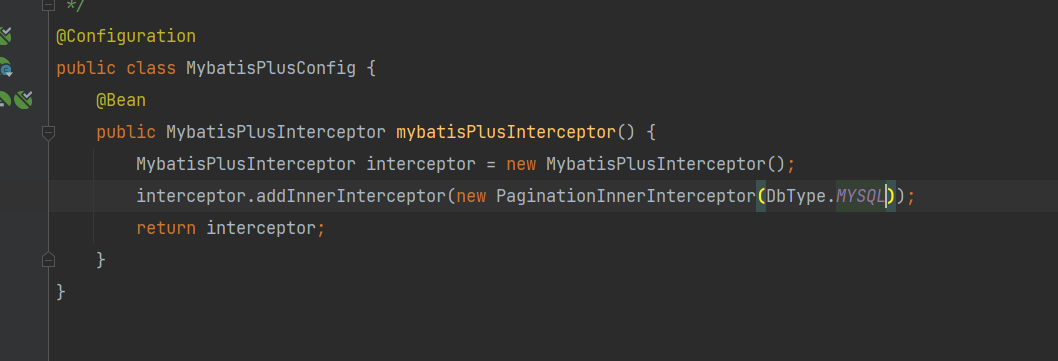
分页查询,如果使用mybatis-plus 分页记得加上分页插件