电面突然被问到这个问题,之前看到过,但是印象不深,导致自己没有答出来,现在总结一下。
HashMap的内部存储结构
transient Node<K,V>[] table; static class Node<K,V> implements Map.Entry<K,V> { final int hash; final K key; V value; Node<K,V> next; }
使用了一个Node数组,这个Node数组的默认大小为16,所有hash值相同的key会存储到同一个链表中,HashMap的构成大概是这个样子(数组、链表、红黑树)
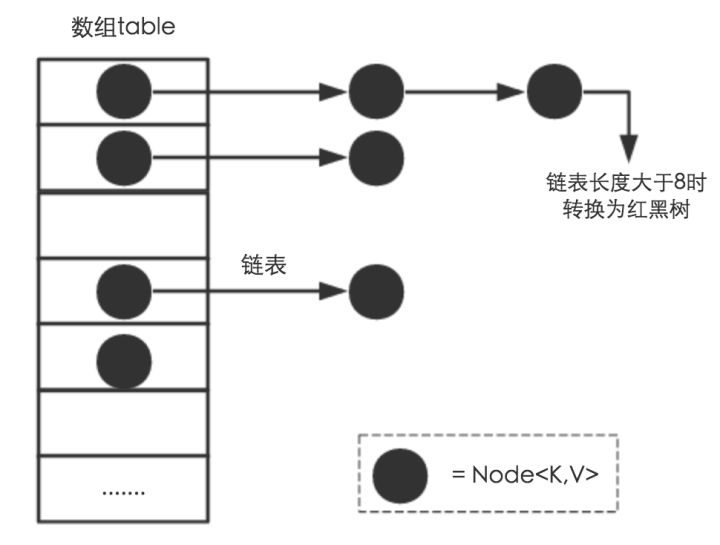
知道了hashmap的实现原理,那么再来谈一谈HashMap的自动扩容机制,默认的Node数组大小为16,如果有特别多的元素,比如说100万个元素,那么最优的情况下,每个hash桶有100万/16=62500个元素,那对于这么多元素来说,存取难度会增加,为了解决这个问题,加入了自动扩容机制。
说到自动扩容机制,首先要知道一些字段
int threshold; // 所能容纳的key-value对极限 final float loadFactor; // 负载因子 int modCount; int size;
threshold是HashMap所能容纳的最大数据量的Node个数,loadFactor是负载因子,modCount用来记录HashMap内部结构发生变化的次数,size是记录实际存在的键值对数量。这里面,threshold=loadFactor*length,这个length是数组长度,当HashMap中元素超过threshold值的话,就发生自动扩容,例如初始的Node长度为16,负载因子为默认的0.75,那么如果元素个数超过了16*0.75=12的话,就会引发自动扩容,Node自动扩展为原来的两倍
那为什么HashMap线程不安全呢?
一、如果多个线程同时使用put方法,当key值一样时,可能会发生覆盖
二、如果多个线程同时检测到元素个数超过了loadFactor*数组大小,那么就会发生多个线程同时对Node数组进行扩容,都重新计算元素位置以及复制数据,但最终只有一个线程扩容后的数组会赋给table,那么其他线程的都会丢失,并且各自线程put的数据也会丢失。
HashMap在并发执行put操作的时候会引起死循环,导致CPU利用率接近100%,多线程会导致HashMap的Node链表行程环形数据结构,一旦行程环形数据结构,Node的next节点永远不为空,会在获取Node时产生死循环。