Java中对字符串等进行转换字节数组时, 需要根据字符集编码来进行转换, 当不显示的指定字符集编码时(如: "测试".getBytes()), 会使用Charset.defaultCharset()获取到的字符集编码进行转换!
相关代码如下:
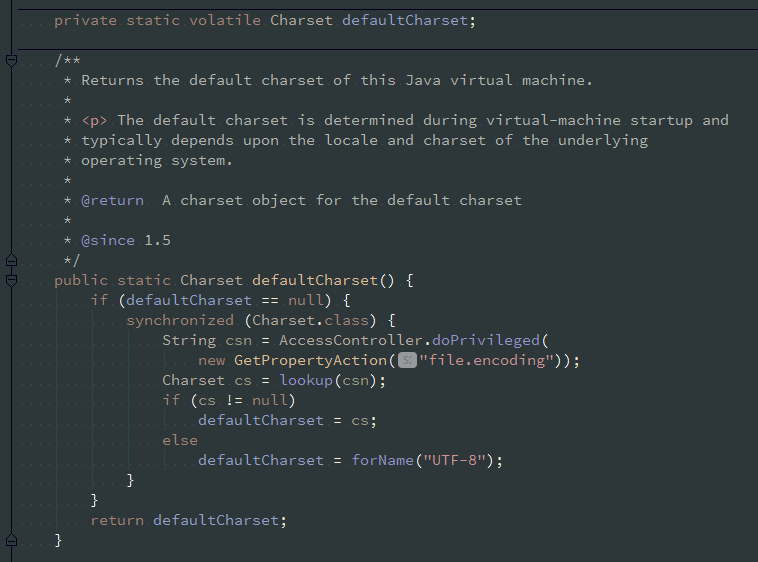
上面的代码可以看出, 在JVM中defaultCharset()是在初始化阶段被调用, 且只会初始化一次, 首先会取file.encoding指定的字符集, 如果取不到则使用系统默认字符集(如: windows下为GBK), 然后通过
取到的字符集名称(csn)去获取Charset对象, 如果能获取到则将其设为defaultCharset, 如果取不到则将defaultCharset设置为UTF-8字符集, defaultCharset一旦被初始化后, 在JVM之后的运行过程中
就无法再进行更改, 比如在JVM启动后在程序中使用properties.setProperty("file.encoding","UTF-8");也不会改变defaultCharset的值~~~
如果想指定defaultCharset的值, 则可以通过JVM启动参数(-Dfile.encoding="UTF-8")来显示的指定此JVM的字符集!!!
拓展内容:
Charset name属性的命名规范如下:
- 大写字母 'A' 到 'Z'('u0041' 到 'u005a'),
- 小写字母 'a' 到 'z'('=pos; 到 ' apos;),
- 数字 '0' 到 '9'('u0030' 到 'u0039'),
- 短划线字符 '-'('u002d',连词符号),
- 句点字符 '.'('u002e',句点),
- 冒号字符 ':'('u003a',冒号),和
- 下划线字符 '_'('u005f',下划线)。
Charset 名称必须以字母或数字开头。空字符串不是合法的 charset 名称。Charset 名称是大小写不敏感的,也就是当比较 charset 名称时总是忽略大小写。
每个 charset 有一个规范名称,也可能有一个或多个别名。规范名称由此类的 name 方法返回。根据约定,规范名称通常是大写的。charset 的别名由 aliases 方法返回。
一些 charset 有一个历史名称,定义这个名称是为了和以前版本的 Java 平台兼容。charset 的历史名称既可以是它的规范名称,也可以是它的某个别名。历史名称由 InputStreamReader 和 OutputStreamWriter 类的 getEncoding() 方法返回。
Java 虚拟机的每个实例都有默认的 charset,它可能是也可能不是某个标准 charset。默认 charset 在虚拟机启动时决定,通常根据语言环境和底层操作系统使用的 charset 来确定。