【问题】
先说遇到的问题。最近开发一个功能的时候,需要将订单按照时间排序,然后在倒序分页展示。语句大概是这样的:
SELECT * FROM goods_order WHERE goods_type_id = '1' ORDER BY goods_name LIMIT 0,10
然后根据客户端传入的页码变化Limit后面的起始位,如LIMIT 0,10,LIMIT 10,10等。此时出现了一个问题,由于Order by后的字段值一致,所以导致不同的页面中有重复数据。这里为了简单模拟,给出一个建表语句:
SET NAMES utf8mb4; SET FOREIGN_KEY_CHECKS = 0; -- ---------------------------- -- Table structure for goods_order -- ---------------------------- DROP TABLE IF EXISTS `goods_order`; CREATE TABLE `goods_order` ( `id` int(0) NOT NULL, `goods_name` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_bin DEFAULT NULL, `goods_type_id` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_bin DEFAULT NULL, `price` int(0) DEFAULT NULL, PRIMARY KEY (`id`) USING BTREE ) ENGINE = InnoDB CHARACTER SET = utf8mb4 COLLATE = utf8mb4_bin ROW_FORMAT = Dynamic; -- ---------------------------- -- Records of goods_order -- ---------------------------- INSERT INTO `goods_order` VALUES (1, '123', '1', 1); INSERT INTO `goods_order` VALUES (2, '123', '1', 1); INSERT INTO `goods_order` VALUES (3, '123', '1', 1); INSERT INTO `goods_order` VALUES (4, '123', '1', 1); INSERT INTO `goods_order` VALUES (5, '123', '1', 1); INSERT INTO `goods_order` VALUES (6, '123', '1', 1); INSERT INTO `goods_order` VALUES (7, '123', '1', 1); INSERT INTO `goods_order` VALUES (8, '123', '1', 1); INSERT INTO `goods_order` VALUES (9, '123', '1', 1); INSERT INTO `goods_order` VALUES (10, '123', '1', 1); INSERT INTO `goods_order` VALUES (11, '123', '1', 1); INSERT INTO `goods_order` VALUES (12, '123', '1', 1); INSERT INTO `goods_order` VALUES (13, '123', '1', 1); INSERT INTO `goods_order` VALUES (14, '123', '1', 1); INSERT INTO `goods_order` VALUES (15, '123', '1', 1); INSERT INTO `goods_order` VALUES (16, '123', '1', 1); INSERT INTO `goods_order` VALUES (17, '123', '1', 1); INSERT INTO `goods_order` VALUES (18, '123', '1', 1); INSERT INTO `goods_order` VALUES (19, '123', '1', 1); INSERT INTO `goods_order` VALUES (20, '123', '1', 1); INSERT INTO `goods_order` VALUES (21, '123', '1', 1); INSERT INTO `goods_order` VALUES (22, '123', '1', 1); INSERT INTO `goods_order` VALUES (23, '123', '1', 1); INSERT INTO `goods_order` VALUES (24, '123', '1', 1); INSERT INTO `goods_order` VALUES (25, '123', '1', 1); INSERT INTO `goods_order` VALUES (26, '123', '1', 1); INSERT INTO `goods_order` VALUES (27, '123', '1', 1); SET FOREIGN_KEY_CHECKS = 1;
建好表后,我们查询第1页和第2页的数据,就能够看到重复的数据了。即:
SELECT * FROM goods_order WHERE goods_type_id = '1' ORDER BY goods_name LIMIT 0,10 SELECT * FROM goods_order WHERE goods_type_id = '1' ORDER BY goods_name LIMIT 10,10
这里我将两个查询的结果图放在一起供大家比较:
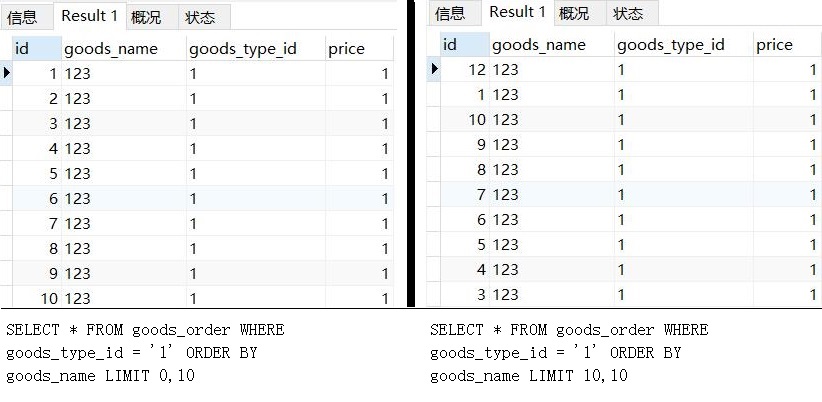
其实这里还有一个现象,如果说每一次排序都是不稳定的,或者随机的(Order By后的字段值相同时),那么我们重复执行相同的sql语句查询出来的结果应该不同。但实际情况是,这种混乱的情况相当稳定。只要是数据库的数据没有变化,我们用相同的sql语句执行出来的结果完全相同。
但如果说,这种排序是不随机的,稳定的,那我们使用还是不使用LIMIT,整个结果应该是一致的,为什么会发生不同页码的数据重复呢?
------------------------------------------------------------------------------------
【官网的说明】
我们先看官方(https://dev.mysql.com/doc/refman/8.0/en/limit-optimization.html)对于ORDER BY后字段值相同场景下的一段描述:
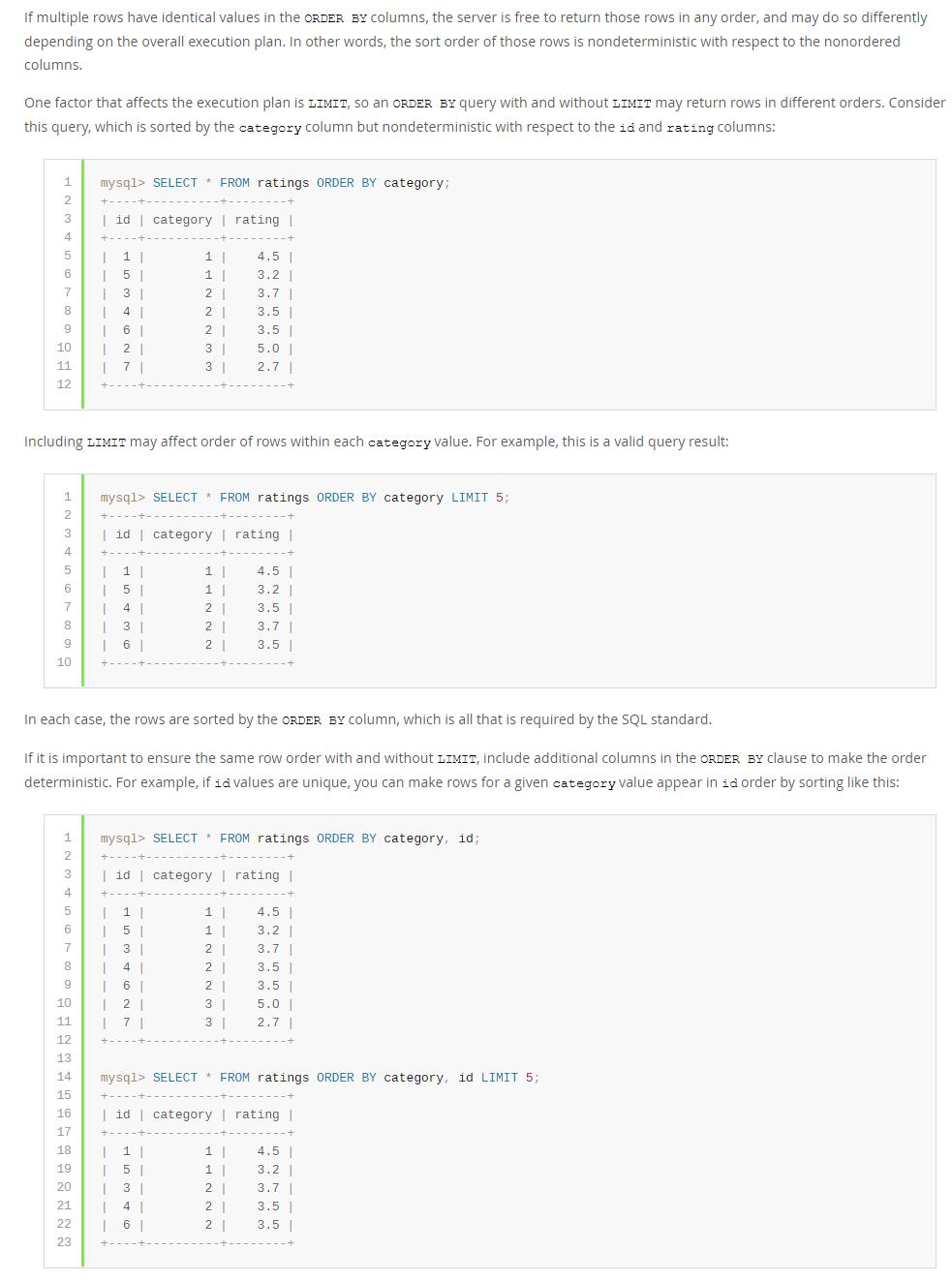
官方不但给出了这种现象的描述,而且给出了一个常规的解决方案:用一个唯一字段,如id,进行组合排序,这样就能避免存在Limit和不存在Limit条件时不一致的问题。
但是,只是说明,还不能解决我们心里的疑问。为什么会有这种现象?加上了唯一的id在排序中,为什么就解决了这个问题呢?
------------------------------------------------------------------------------------
【原因】
<参考:https://www.cnblogs.com/zhengxl5566/p/14030081.html>
这篇文章里,作者已经从源码的级别分析了这种现象出现的原因。这里我做一个简要的自我理解的说明:
首先,从MySQL5.6开始,对于ORDER BY+LIMIT这种组合,优化器会使用priority queue来处理。这个优先队列是什么呢?我们在源代码(https://dev.mysql.com/doc/dev/mysql-server/8.0.25/priority__queue_8h_source.html)中可以看看对于priority queue的实现说明:

可以看到这个优先队列其实就是max-heap,使用这种结构就是为了快。那么,这跟我们遇到的问题有什么关系呢?
在之前提到的参考文中,作者用流程图还原了一个5个节点的小顶堆是怎么完成priority queue的执行逻辑的。简单说,就是固定了几个节点之后,当所有的数据都经过这个堆,按照堆排序的规则进行数据的安插和取舍,那么堆上最后保留的数据就是我们想要的排序结果。
而MySQL服务器中,Limit的使用基本都可以归结为LIMIT n,也就是说,如果你使用了(Limit m,n),那么服务器会把m+n个数据的个数作为堆的大小,然后进行所有数据的排序,最后返回给你m+n这一堆有序数据的最后n个。所以,这个原因就归结为两个要点:
1.不同页的数据,Limit x,n和Limit y,n的堆结构的节点数量不同,也就是堆的大小发生了变化;
2.堆排序的不稳定性。即当堆大小变化后,相等项目的相对顺序可能会发生变化。
我们一开始分页的数据,是LIMIT 0,10以及LIMIT 10,10,所以服务器中两个堆的大小就是10和20,只不过第二个语句是通过20个节点的堆排序完成后,将后10个数据返回给我们了。由于order by中的字段内容完全相同,所以当堆的大小发生变化后,整个顺序与之前不相同也就不难理解了。
为了验证,我们可以做另一个实验。我们使用Limit x,y和Limit m,n来进行取数,但是x+y与m+n的大小保持一致,也就是堆的大小相同,看看排序结果是不是一致的:
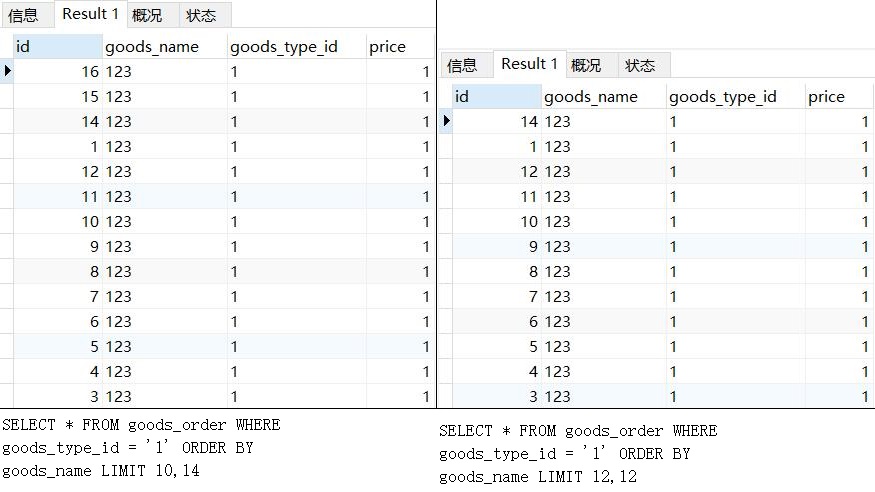
可以看到,在order by goods_name Limit m,n中排序字段值相同,且m+n大小一致的前提下,两组结果末尾相同倒序位数的数据是相同的。
------------------------------------------------------------------------------------
【扩展】
上面说明了现象,原因,但是对于LIMIT N的这种优化,还是有些可以拓展的内容。我们在分页开发中,后端程序往往直接order by category limit x,n,而后通过x和n的变化来处理前端的分页数据请求,但是通过上述内容可知,当x+n特别大的时候,服务器中的堆也就特别大。
如果用户要看结尾的几页数据,当数据量特别大的时候,那个性能就很难堪了。所以,有个简单的优化方法,就是缩小查找范围。
比如,下面的语句:
SELECT * FROM goods_order WHERE goods_type_id = '1' ORDER BY id LIMIT 0,2;
SELECT * FROM goods_order WHERE goods_type_id = '1' ORDER BY id LIMIT 2,2;
这两句查的是第1页和第2页的数据,但是如果id自增且连续的话,我们完全可以通过计算,来控制我们进行排序的范围起点:
SELECT * FROM goods_order WHERE goods_type_id = '1' ORDER BY id LIMIT 0,2;
SELECT * FROM goods_order WHERE goods_type_id = '1' AND id>2 ORDER BY id LIMIT 0,2;
(实际编码中我们不会这么做,但是思路相通,后续分析LIMIT的优化手段)
此时,堆的大小相同,但是排序的结果完全一致。这也算是一种优化,当m+n的量尤其大时,这为我们服务器带来的资源节省是很可观的。
从这个角度,我们也能够理解,为什么说不建议使用UUID作为主键。
未完待续......